Hadoop源码解析:分布式存储与计算框架关键组件
Hadoop源码分析深入探讨了Apache基金会开发的分布式计算框架的核心组件——Hadoop。作为Google核心竞争技术之一的分布式云计算的开源版本,Hadoop提供了一种在廉价硬件上构建高性能、高容错性和高吞吐量数据处理环境的方式。它主要包括两个关键组件:Hadoop Distributed File System (HDFS) 和 MapReduce。
HDFS是一个分布式文件系统,其设计目标是支持大规模数据集的存储和访问。它具有高容错性,能够在节点故障时自动恢复数据,确保数据的一致性和可靠性。HDFS通过抽象层隐藏底层细节,使得用户无需关注文件系统的底层实现,无论是本地文件系统还是云存储服务如Amazon S3,都能无缝集成。这种设计导致了Hadoop包间的依赖关系复杂,尤其是conf包与fs包之间的交互,体现了HDFS的分布式特性。
另一个重要组成部分是MapReduce,这是一个并行编程模型,用于处理大规模数据集。它将复杂的计算任务分解为一系列简单的map和reduce操作,允许在集群中分布式执行。Hadoop的MapReduce框架在HDFS之上运行,这两个组件紧密相连,共同构成了Hadoop的核心生态系统。
Hadoop源代码分析系列文章深入剖析了Hadoop的顶层包结构及其依赖关系,着重关注图中的蓝色部分,即HDFS和MapReduce的核心模块。这些分析有助于理解分布式系统的设计原则,以及如何利用Hadoop进行数据处理和存储。通信机制在Hadoop中也扮演着重要角色,因为MapReduce和HDFS都需要高效的通信来协调任务分发和结果交换。
通过对Hadoop源码的深入研究,开发者能够学习到分布式系统的设计理念,提高自己的编程技能,并为处理大规模数据集提供强大的工具。同时,这也有助于开发者理解和优化其他基于类似思想的开源项目,如Facebook的Hive。Hadoop源码分析不仅是技术开发者必备的技能,也是理解现代大数据处理基础设施的重要途径。

有了上面的描述,我们得到下面左边的状态图:
大家应该注意到,上面的升级回滚提交都不可能一下就搞定,就是说,系统故障时,它可能处于上面右边状态中的某一个。
特别是分布式的各个节点上,甚至可能出现某些节点已经升级成功,但有些节点可能处于中间状态的情况,所以 " 采
用类似于数据库事务的升级机制也就不是很奇怪。
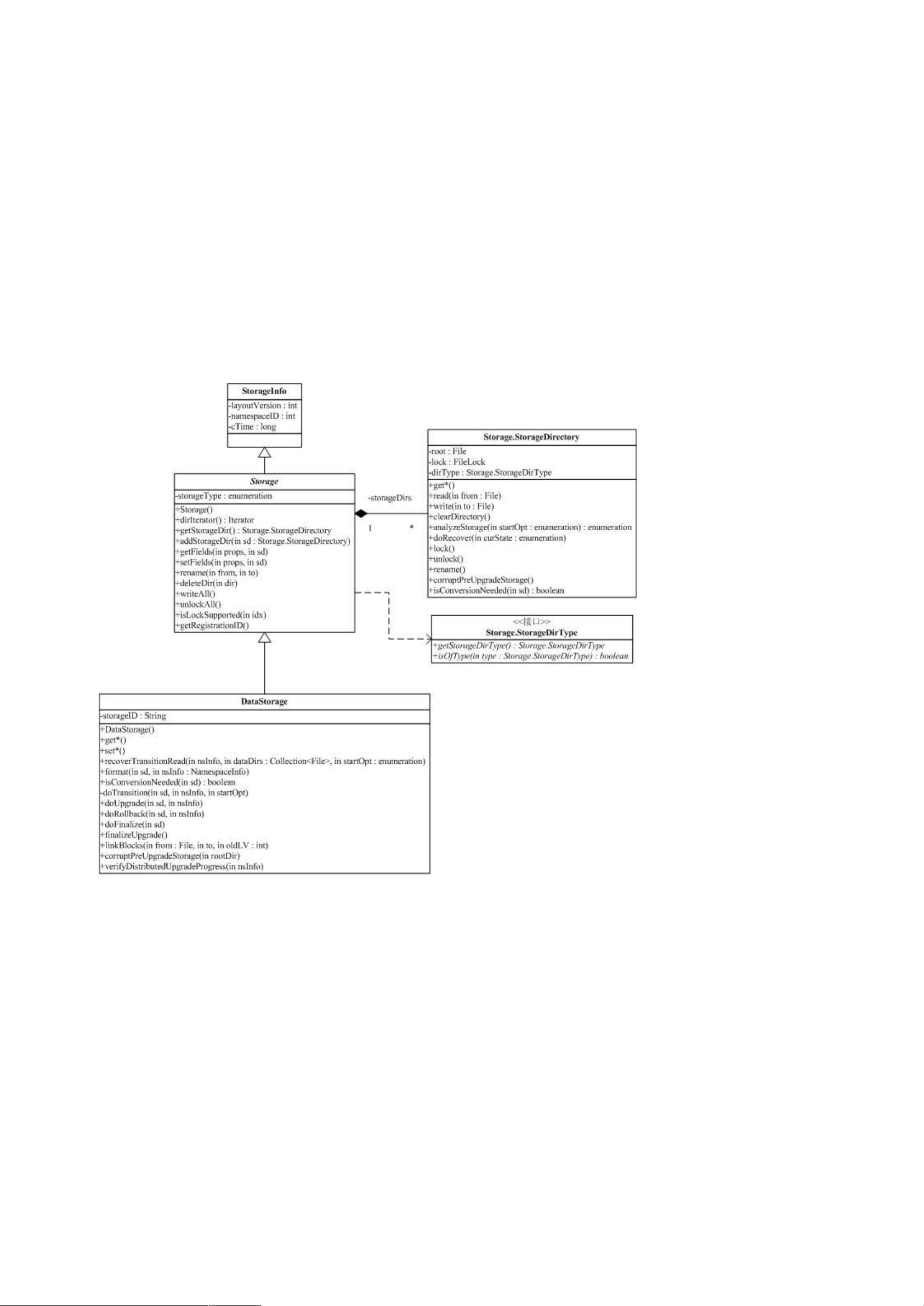
大家先理解一下上面的状态图,它是下面我们要介绍 '< 存储的基础。
Hadoop
源代码分析(一一)
我们来看一下升级回滚提交时的 '< 上会发生什么(在类 ' 中实现)。
前面我们提到过 E5,(< 文件,它保存了一些文件系统的元信息,这个文件在系统升级时,会发生对应的变化。
升级时,<< 会将新的版本号,通过 '< 的登录应答返回。'< 收到以后,会将当前的数据块文件目
录改名,从 ) 改名为 ,建立一个 ),然后重建 ) 目录。重建包括重建 E5,(< 文件,
重建对应的子目录,然后建立数据块文件和数据块元数据文件到 的硬连接。建立硬连接意味着在系统中只保留
一份数据块文件和数据块元数据文件,) 和 中的相应文件,在存储中,只保留一份。当所有的这些工作
完成以后,会在 ) 里写入新的 E5,(< 文件,并将 目录改名为 ,完成升级。
了解了升级的过程以后,回滚就相对简单。因为说有的旧版本信息都保存在 目录里。回滚首先将 ) 目录改名
为 ,然后将 目录改名为 ),最后删除 目录。
提交的过程,就是将上面的 目录改名为 F)- ,然后启动一个线程,将该目录删除。
下图给出了上面的过程:

剩余63页未读,继续阅读
2011-05-21 上传
2010-05-20 上传
2012-06-19 上传
2011-09-01 上传
2021-03-04 上传
2012-04-10 上传

adam_tang
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- La_Carte
- abouhanna:凯文的个人网站
- graphml:GraphML是图形的基于XML的文件格式
- pandas_gbq_magic-1.1.1.tar.gz
- h264_streaming.2.2.7.rar
- TM Light-开源
- Loup-crx插件
- shinyfullscreen:使用“ Screenfull.js”在“发光”应用程序中全屏显示HTML元素
- pandas_gbq_magic-1.1.0.tar.gz
- Detection_FootballvsCricketBall 检测_足球vs板球-数据集
- frdomain-extras:功能性和React性域建模的附加伴奏
- chrome-alex-crx插件
- Tiny Box-开源
- Aircnc:Rockeseat的教程在Omnistack9周内开发了应用程序
- Universe:一个软件平台,用于在世界范围内的游戏,网站和其他应用程序中测量和培训AI的一般情报。-Python开发
- Blog-Theme-Hexo-ICARUS-CUSTOMED:ppofficehexo-theme-icarus를수정하여사용중인
