Flink工作原理:JobClient、JobManager与TaskManager
103 浏览量
更新于2024-08-27
收藏 358KB PDF 举报
"Flink是基于Java实现的流计算引擎,能够处理流数据和批数据,功能涵盖Spark和Spark Streaming。其核心理念是将批处理视为特殊形式的流处理。在运行时,Flink系统主要涉及三个关键组件:JobClient、JobManager和TaskManager。流程是用户通过JobClient提交程序,经过解析、优化后交给JobManager,再由TaskManager执行任务。"
Flink的基本工作原理主要围绕着这三个组件展开:
1. **JobClient**:JobClient是用户与Flink系统的接口,它接收并解析用户提交的Flink程序。JobClient对程序进行执行计划的构建,将程序中的各种操作(如SourceOperator、TransformationOperator和SinkOperator)转化为Operator Graph。这个图表示了数据流的处理路径。接着,JobClient会进一步优化执行计划,通过融合相邻的Operator来减少不必要的数据传输,形成OperatorChain。
2. **JobManager**:JobManager是Flink的协调器,它接收来自JobClient的优化后的执行计划,并负责任务调度和状态管理。JobManager将Operator Graph分割成一系列的任务(Task),并将这些任务分配给可用的TaskManager来执行。此外,它还处理故障恢复和资源管理。
3. **TaskManager**:TaskManager是Flink的执行节点,它们实际执行Task并处理数据流。每个Task被分解为多个SubTask,SubTask之间通过网络进行数据交换。Flink支持两种数据传输模式:one-to-one模式和重新分布模式。在one-to-one模式下,数据无需重新分布,可以直接在TaskManager之间本地传递,减少了网络延迟。
Flink的流处理模型强调事件时间(event time)而非处理时间(processing time),这使得Flink能够处理乱序到达的数据,提供准确的一次性语义(exactly-once semantics)。此外,Flink的检查点(checkpoint)机制确保了在系统故障时能够恢复到一致的状态。
Flink的并行性和容错能力是通过将数据流划分为多个并行的数据通道(channels)来实现的。每个Operator的SubTask都会处理一部分数据,而TaskManager之间的通信通过网络shuffle进行,确保数据能够在不同节点间高效地传输。
Flink的设计使其在实时数据处理领域具有高性能和高可用性,能够应对大规模数据流的挑战。它的流批一体化处理能力和强大的容错机制使其在大数据处理场景中表现出色。
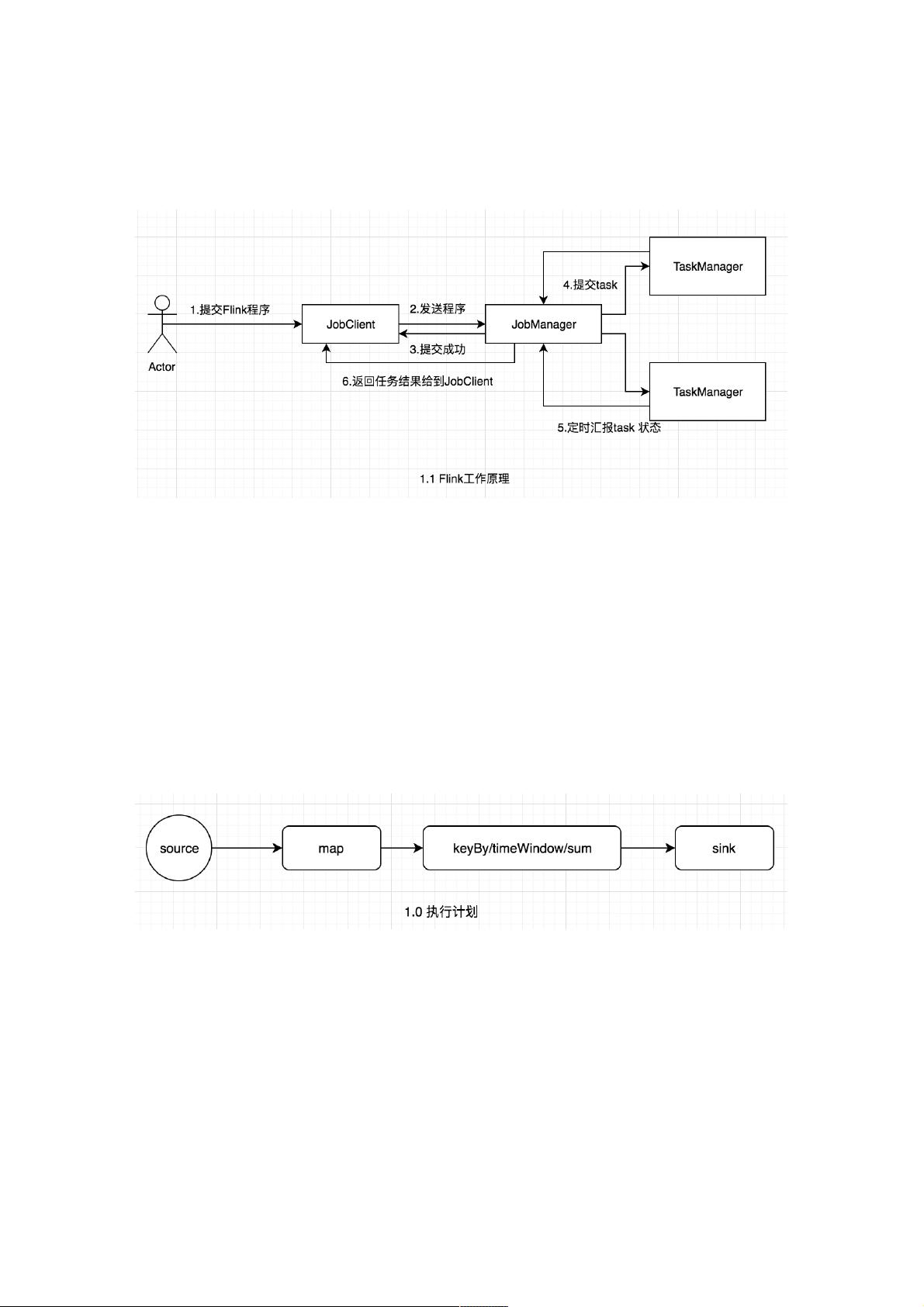
Flink基本工作原理基本工作原理
Flink是新的stream计算引擎,用java实现。既可以处理stream data也可以处理batch data,可以同时兼顾Spark以及Spark
streaming的功能,与Spark不同的是,Flink本质上只有stream的概念,batch被认为是special stream。Flink在运行中主要有
三个组件组成,JobClient,JobManager 和 TaskManager。主要工作原理如下图
用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化提交到JobManager,最后由TaskManager运行task。
JobClient
JobClient是Flink程序和JobManager交互的桥梁,主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交
执行计划到JobManager。为了了解Flink的解析过程,需要简单介绍一下Flink的Operator,在Flink主要有三类Operator,
Source Operator ,顾名思义这类操作一般是数据来源操作,比如文件、socket、kafka等,一般存在于程序的最开始
Transformation Operator 这类操作主要负责数据转换,map,flatMap,reduce等算子都属于Transformation Operator,
Sink Operator,意思是下沉操作,这类操作一般是数据落地,数据存储的过程,放在Job最后,比如数据落地到Hdfs、
Mysql、Kafka等等。
Flink会将程序中每一个算计解析成Operator,然后按照算子之间的关系,将operator组合起来,形成一个Operator组合成的
Graph。如下面的代码解析之后形成的执行计划,
解析形成执行计划之后,JobClient的任务还没有完,还负责执行计划的优化,这里执行的主要优化是将相邻的Operator融
合,形成OperatorChain,因为Flink是分布式运行的,程序中每一个算子,在实际执行中被分隔为多个SubTask,数据流在算
子之间的流动,就对应到SubTask之间的数据传递,SubTask之间进行数据传递模式有两种一种是one-to-one的,数据不需要
重新分布,也就是数据不需要经过IO,节点本地就能完成,比如上图中的source到map,一种是re-distributed,数据需要通过
shuffle过程重新分区,需要经过IO,比如上图中的map到keyBy。显然re-distributed这种模式更加浪费时间,同时影响整个
Job的性能。所以,Flink为了提高性能,将one-to-one关系的前后两类subtask,融合形成一个task。而TaskManager中一个
task运行一个独立的线程中,同一个线程中的SubTask进行数据传递,不需要经过IO,不需要经过序列化,直接发送数据对象
到下一个SubTask,性能得到提升,除此之外,subTask的融合可以减少task的数量,提高taskManager的资源利用率。图1.0
中的执行计划,优化结果如下图,Flink的subTask融合规则可以参考官方文档。
值得注意的是,并不是每一个SubTask都可以被融合,对于不能融合的SubTask会独立形成一个Task运行在TaskManager
中。
改变operator的并行度,可能会导致不同的优化结果,同时这也是性能调优的一个重要方式,例如不显式设置operator的并行
度的时候,默认所有算子的并行度是一样的,所以会有下图中的优化结果。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
103 浏览量
2023-04-28 上传
2019-07-17 上传
2019-02-26 上传
2023-03-21 上传
点击了解资源详情

weixin_38590567
- 粉丝: 2
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
