Flink调优:RocksDB设置与性能监控策略
版权申诉
67 浏览量
更新于2024-08-07
收藏 1.74MB DOC 举报
本文档深入探讨了Apache Flink中RocksDB状态管理器的调优策略,特别是针对其作为State Backend在处理性能瓶颈时的关键优化。RocksDB是一种键值存储系统,以其高效的写入性能和内存与磁盘结合的存储机制而闻名。Flink中的RocksDB StateBackend主要关注磁盘I/O操作,因为每次读写都需要处理序列化和反序列化,这可能成为性能瓶颈。
首先,文章介绍了Flink 1.13版本引入的性能监控功能,即latency tracking state,用于追踪和分析State访问的延迟情况。这个功能对于所有类型的State Backend都适用,包括自定义实现。尽管能提供有价值的信息来识别性能问题,但频繁的采样会带来约1%至10%的性能损失,具体取决于backend类型。对于RocksDB,损失较小,而对于heapState Backend,由于内存操作的影响,性能损失可能会显著增加。为了平衡监控精度和性能,用户可以调整采样间隔、保留历史采样数据的数量,以及是否将状态名作为变量。
其次,文档重点推荐开启增量检查点功能。RocksDB作为唯一的支持有状态流处理应用程序的增量检查点后端,允许在不影响处理流程的情况下,仅更新状态的更改部分,从而显著降低全量检查点带来的I/O开销。通过将state.backend.incremental参数设置为true,或者在代码中指定,用户可以充分利用这一特性来优化Flink Job的吞吐量和资源利用率。
此外,文中还可能涉及其他RocksDB调优技巧,如调整block cache的大小、设置合适的compaction策略以减少磁盘碎片、以及配置适当的内存池管理等,这些都是提升性能和避免内存溢出的重要手段。通过深入了解这些参数和优化技巧,Flink用户可以更好地调整RocksDB配置,以适应特定场景的需求,从而实现更高效的流处理任务执行。
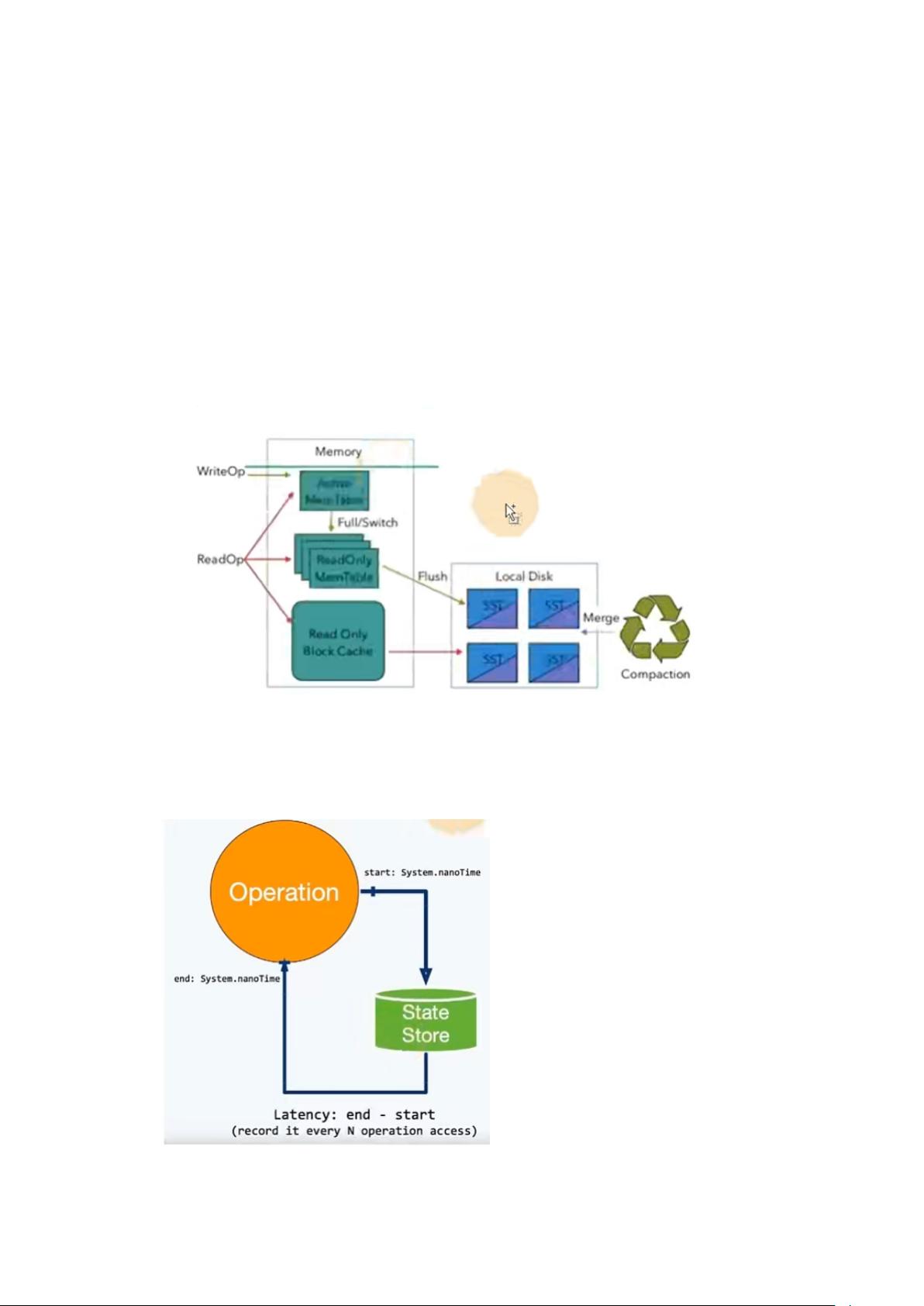
flink 调优之 RocksDB 设置
一、开启监控
RocksDB 是基于 LSM Tree 实现的,写数据都是先缓存到内存中,所以 RocksDB 的写请
求效率比较高。RocksDB 使用内存结合磁盘的方式来存储数据,每次获取数据时,先从内
存中 blockcache 中查找,如果内存中没有再去磁盘中查询。使用
RocksDB 时,状态大小仅受可用磁盘空间量的限制,性能瓶颈主要在于 RocksDB 对磁盘
的读请求,每次读写操作都必须对数据进行反序列化或者序列化。当处理性能不够时。仅需
要横向扩展并行度即可提高整个 Job 的吞吐量。
flink1.13 中引入了 State 访问的性能监控,即 latency tracking state、此功能不局限于 State
Backend 的类型,自定义实现的 State Backend 也可以复用此功能。
下载后可阅读完整内容,剩余6页未读,立即下载
2022-06-06 上传
2022-07-10 上传
2021-02-19 上传
2018-12-25 上传
2020-01-18 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- RPMA回传+ Arduino Yun –第3部分-项目开发
- easy-redux:简化redux api
- BarreOutils:锻炼巴雷特迪尔斯
- copylight:jQuery 插件为内容许可证提供视觉强化
- 2021最新孜然导航系统 v1.0
- 微信小程序-小厨房
- visibl:通过React HOC进行视口内检测
- canvasinvaders:HTML Canvas 上的太空入侵者(有点)
- clickhousewriter.zip
- 西门子PLC工程实例源码第637期:转速PID控制程序(双脉冲).rar
- 洗剂
- 物理和云Cayenne交换机-项目开发
- fit-text-to-screen:
- CSYE6220:CSYE6220的分配
- ChatBot
- FJLRS:费·琼斯实验室请求系统
