人类偏好驱动的自然语言模型微调:应用与实证研究
版权申诉
"Fine-Tuning Language Models from Human Preferences" 是一篇由 Daniel Ziegler、Nisan Stiennon 等来自 OpenAI 的研究者共同撰写的论文,他们专注于探索如何将人类偏好应用于语言模型的微调过程,以增强人工智能在现实世界任务中的实用性和安全性。该研究主要集中在利用强化学习(RL)的奖励学习机制,因为自然语言中蕴含了复杂的价值判断,这对于将RL扩展到真实环境至关重要。
传统上,奖励学习的研究大多集中在模拟环境中,然而,自然语言提供了表达价值观的独特途径。作者们提出,通过利用生成式预训练语言模型的进展,可以直接针对自然语言任务进行奖励学习。他们选择了四个具体的任务来进行实验:一是风格化的文本续写,要求模型生成积极或具象的语言;二是基于 TL;DR 和 CNN/DailyMail 数据集的文本摘要,要求模型能准确提炼关键信息。
在风格化文本续写任务中,研究人员展示了即使只使用了5,000个经人类评估的比较,模型也能展现出良好的性能,这表明了即使少量的人类反馈也能有效指导模型学习。对于文本摘要,他们进行了更为深入的训练,使用了60,000次人类对比,使得模型能够学会更准确地复制原文的主要观点,从而实现高质量的总结。
这篇论文的核心贡献在于展示了如何通过结合大规模语言模型和人类偏好,让AI系统在处理自然语言时更加贴近人类的理解和期望,从而提升其在实际应用中的表现。这种方法不仅有助于强化学习在语言处理领域的拓展,也为确保AI系统的决策安全性和道德合理性提供了一种新的可能。通过细致的实验设计和分析,研究者们为我们理解如何在实际场景中有效利用人类知识来指导AI学习开辟了新的路径。
Fine-Tuning Language Models from Human Preferences
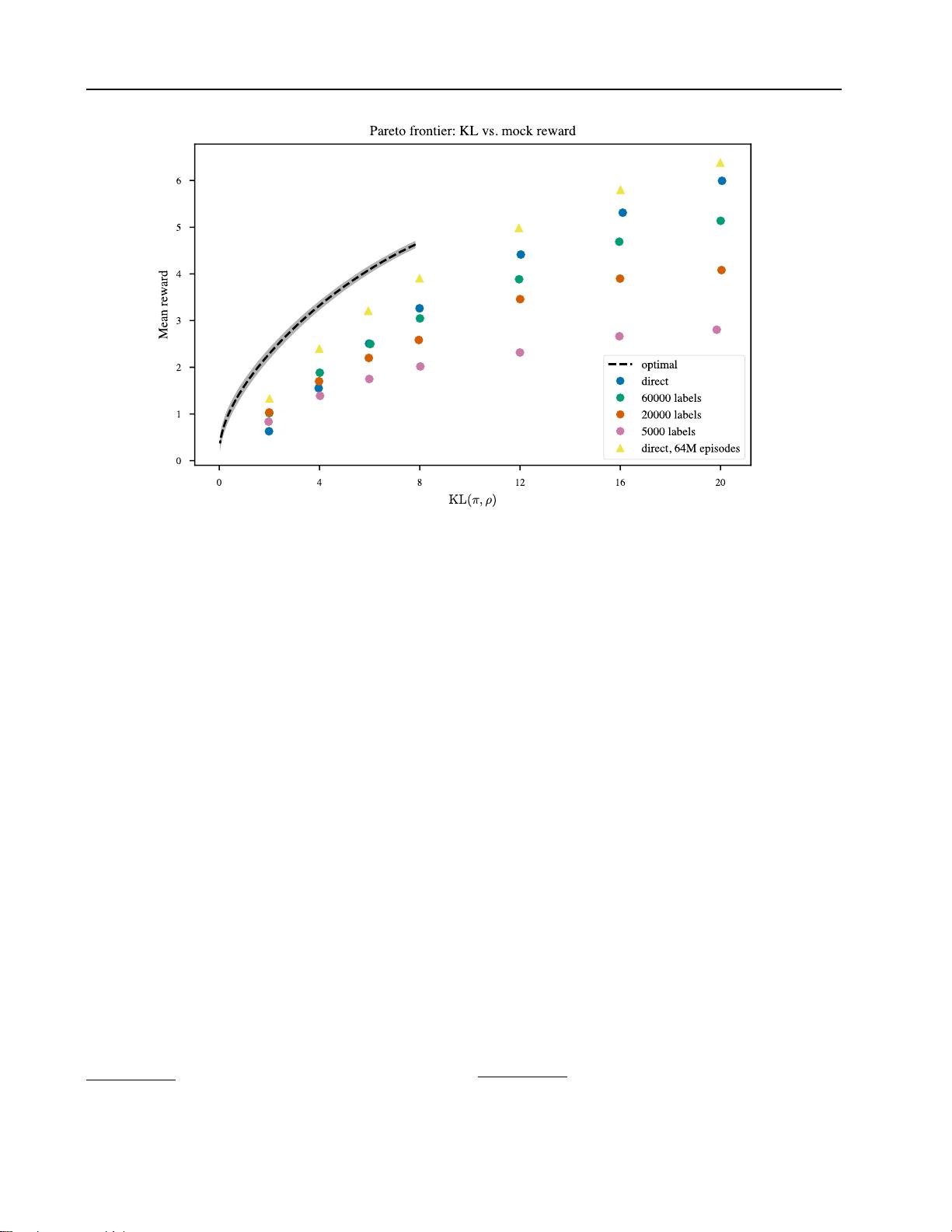
Figure 3: Allowing the policy
π
to move further from the initial policy
ρ
as measured by
KL(π, ρ)
achieves higher reward at
the cost of less natural samples. Here we show the optimal KL vs. reward for 124M-parameter mock sentiment (as estimated
by sampling), together with results using PPO. Runs used 2M episodes, except for the top series.
We release code
2
for reward modeling and fine-tuning in
the offline data case. Our public version of the code only
works with a smaller 124M parameter model with 12 layers,
12 heads, and embedding size 768. We include fine-tuned
versions of this smaller model, as well as some of the human
labels we collected for our main experiments (note that these
labels were collected from runs using the larger model).
3.1. Stylistic continuation tasks
We first apply our method to stylistic text continuation tasks,
where the policy is presented with an excerpt from the Book-
Corpus dataset (Zhu et al., 2015) and generates a continu-
ation of the text. The reward function evaluates the style
of the concatenated text, either automatically or based on
human judgments. We sample excerpts with lengths of 32
to 64 tokens, and the policy generates 24 additional tokens.
We set the temperature of the pretrained model to
T = 0.7
as described in section 2.1.
3.1.1. MOCK SENTIMENT TASK
To study our method in a controlled setting, we first apply it
to optimize a known reward function
r
s
designed to reflect
some of the complexity of human judgments. We construct
2
Code at https://github.com/openai/lm-human-preferences.
r
s
by training a classifier
3
on a binarized, balanced subsam-
ple of the Amazon review dataset of McAuley et al. (2015).
The classifier predicts whether a review is positive or nega-
tive, and we define
r
s
(x, y)
as the classifier’s log odds that
a review is positive (the input to the final sigmoid layer).
Optimizing
r
s
without constraints would lead the policy
to produce incoherent continuations, but as described in
section 2.2 we include a KL constraint that forces it to stay
close to a language model ρ trained on BookCorpus.
The goal of our method is to optimize a reward function
using only a small number of queries to a human. In this
mock sentiment experiment, we simulate human judgments
by assuming that the “human” always selects the continu-
ation with the higher reward according to
r
s
, and ask how
many queries we need to optimize r
s
.
Figure 2 shows how
r
s
evolves during training, using either
direct RL access to
r
s
or a limited number of queries to train
a reward model. 20k to 60k queries allow us to optimize
r
s
nearly as well as using RL to directly optimize r
s
.
Because we know the reward function, we can also ana-
lytically compute the optimal policy and compare it to our
learned policies. With a constraint on the KL divergence
3
The model is a Transformer with 6 layers, 8 attention heads,
and embedding size 512.
http://chat.xutongbao.top
剩余25页未读,继续阅读
175 浏览量
点击了解资源详情
599 浏览量
2024-06-13 上传
2022-06-14 上传
2024-06-13 上传
2022-05-13 上传
2022-01-31 上传

普通网友
- 粉丝: 1283
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
