成本敏感大余量分布机:不平衡数据分类的解决方案
114 浏览量
更新于2024-08-26
1
收藏 917KB PDF 举报
"大型成本敏感型利润分配机,用于不平衡数据分类"
在当前的机器学习领域,尤其是在分类问题中,处理不平衡数据集是一项重大挑战。不平衡数据指的是不同类别的样本数量差异悬殊,例如,一个类别可能有大量样本,而另一个类别只有少量样本。这种情况在现实世界的数据集中很常见,比如医疗诊断中的罕见疾病识别或信用卡欺诈检测。标题提到的“大型成本敏感型利润分配机”(LCSDM)就是针对这种问题的一种解决方案。
大型边距分配机(LDM)是基于边缘理论的分类器,它试图通过增大分类边界(即边缘)来提高分类性能和泛化能力。然而,当面临不平衡训练数据时,LDM可能会导致多数类别与少数类别之间的边际分布失衡,进而影响到少数类别的检测率,这对那些需要高检测率的少数类别应用来说是个问题。
为了解决这个问题,文章提出了“成本敏感的边际分布学习”方法。这种方法考虑了分类错误的成本,使得模型能够更关注那些错误分类代价高的样本,尤其是少数类别样本。通过调整和优化成本敏感参数,可以实现两类之间的边际分布平衡,从而提高少数类别的检测率,达到“平衡检测率”的目标。
成本敏感学习是一种机器学习策略,它允许我们根据错误分类的后果来调整模型的训练过程。在不平衡数据集上,将更高的权重赋予少数类别的样本,可以帮助提升其在模型中的影响力,从而改善分类效果。文章中,作者推导了成本敏感参数与同类检测率之间的关系,这对于理解和优化LCSDM的性能至关重要。
实验结果显示,LCSDM能够逐步增加少数类别的边际分布,这意味着模型在处理不平衡数据时能更好地识别和处理这些类别,从而实现更加均衡的检测率。这项工作不仅在理论上有所贡献,还为实际应用提供了有效的方法,特别是对于那些需要处理不平衡数据的分类任务,如金融欺诈检测、医学图像分析等。
这篇论文提出了一种新的机器学习方法——LCSDM,它结合了成本敏感学习和边际分布理论,解决了在不平衡数据集上提高少数类别检测率的问题。这一方法通过调整边际分布,可以实现各类别间的检测率平衡,对于提高分类器的性能和实用性具有重要意义。
minimum margin (the intersection of the curve and the margin-axis) of
H
LD
M
is less than that of
H
SV
M
, but
H
LD
M
lies on the right side. This
illustrates that SVM has a larger minimum margin, and LDM has a
larger margin distribution. Then a natural question is which one is
more important. Gao and Zhou [8] gave the answer and revealed that
the margin distribution instead of a single margin is critical to the
generalization performance. In the following, an implement of large
margin distribution learning will be introduced.
2.2. Large margin distribution machine
LDM proposed by Zhang and Zhou [10] tries to get a strong
generalization performance by maximizing the margin distribution.
The margin distribution is characterized by the first- and second-order
statistics (the margin mean and margin variance). The margin mean is
formulated as
∑
ωω
γ
yϕ
m
Xxy=()=
1
(),
i
m
i
TT
i
=1
where
Xϕ ϕxx=[ ( ),…, ( )
]
1m
represents the example matrix. The margin
variance is formulated as
l
∑∑
ωω ωωωωγ
m
yϕ yϕ
m
mXX X Xxx yy=
1
(()− ()),=
2
(−
)
.
i
m
j
m
i
T
j
TTTTTT
ij
2
=1 =1
2
2
LDM maximizes the margin mean and minimizes the margin variance
simultaneously. The optimal object function of LDM is formulated as
l
∑
ωω ωλγ λγ C ξs t y ϕ ξ ξ i Lxmin
1
2
+ − + .. . ( )≥1− , ≥0, ∈ ,
wξ
T
i
m
i
i
T
iii
,
12
=1
(4)
where λ
1
, λ
2
and C are the trade-off parameters for the model
complexity, margin variance, margin mean and training error.
Though LDM performs well on many data sets compared with SVM
and other out-of-the-art methods [10], it generally has an imbalanced
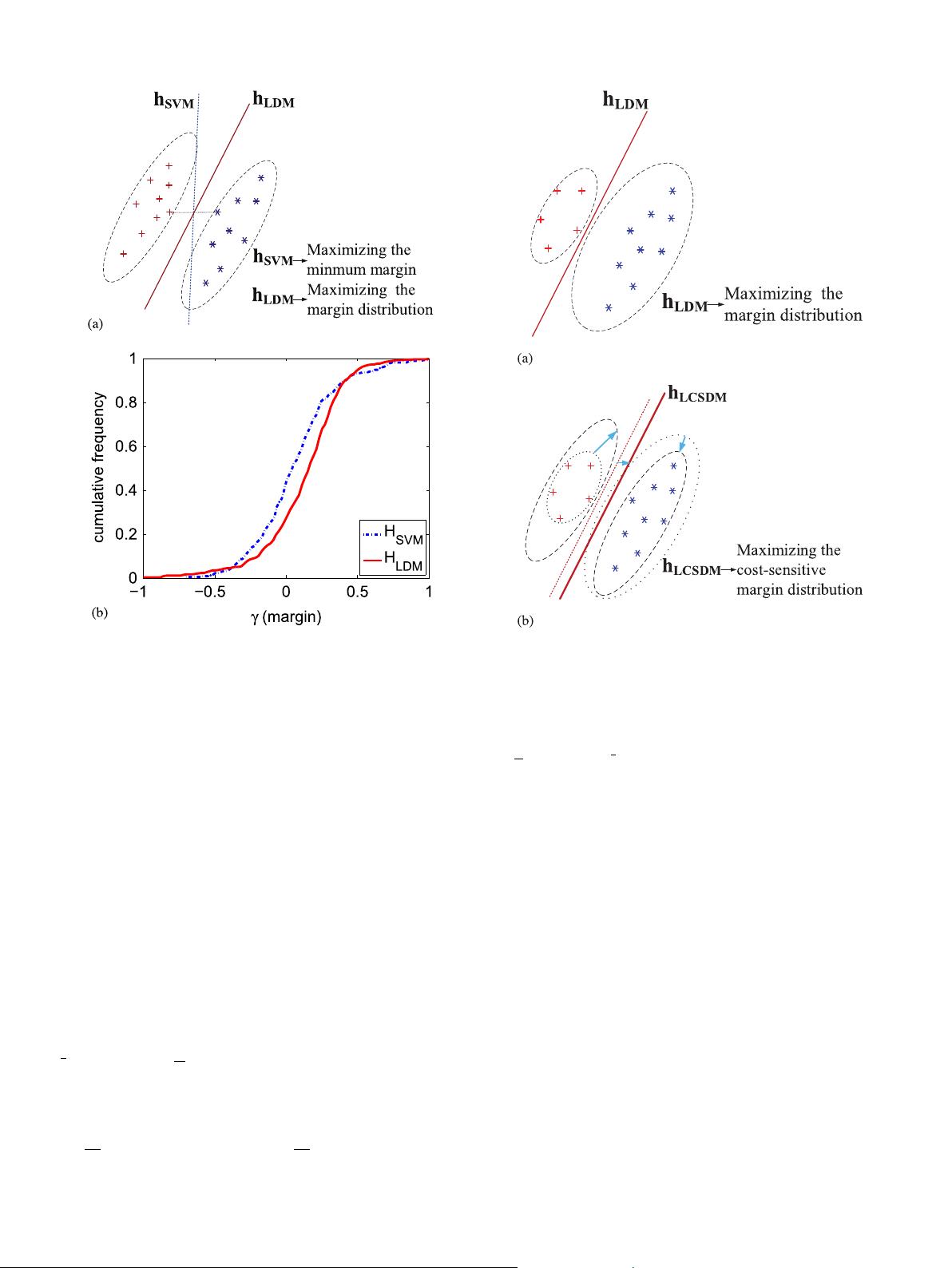
margin distribution between two classes on imbalanced training set. As
shown in Fig. 2(a), LDM generally forces the separator
h
LD
M
to get close
to the positive class (the minority class) and shrinks the encirclement
of the positive support hyperplane described by left dashed ellipse to
increase the margin mean and decrease the margin variance on
imbalanced training data. This imbalanced problem can be effectively
solved by cost-sensitive learning [29]. Therefore cost-sensitive margin
distribution learning is proposed based on margin distribution theory
to address imbalanced binary-classification on imbalanced training
data.
3. Cost-sensitive margin distribution learning
The idea of cost-sensitive margin distribution learning is that the
margin weight of the positive class in the margin mean should be
increased, the margin weight of the positive class in the margin
variance should be decreased and the misclassification penalty of the
positive class should be heightened to increase the margin distribution
of the positive class. As shown in Fig. 2(b), cost-sensitive margin
Fig. 1. (a) Simple illustration of the separators. The red pluses represent positive
examples and the blue stars represent negative examples.
h
SV
M
represents the separator
of SVM and
h
LD
M
represents the separator of LDM. Examples located on di fferent sides
of the separator will be classified to different categories. (b) Simple illustration of the
margin distributions.
H
SVM
is cumulative frequency curve of SVM, and
H
LDM
is
cumulative frequency curve of LDM. The more right the cumulative frequency curve is,
the larger the margin distribution is. (For interpretation of the references to color in this
figure legend, the reader is referred to the web version of this article.)
Fig. 2. (a) Simple illustration of the LDM separator on imbalanced training data. (b)
Simple illustration of the LCSDM separator on imbalanced training data.
h
LD
M
represents the separator of LDM and
h
LCSD
M
represents the separator of LCSDM.
F. Cheng et al.
Neurocomputing 224 (2017) 45–57
47
剩余12页未读,继续阅读
2021-11-10 上传
2021-09-30 上传
点击了解资源详情
2024-11-18 上传
2024-11-18 上传

weixin_38716590
- 粉丝: 4
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
