IDP-CRF:条件随机场驱动的固有无序蛋白/区域识别提升精准预测
29 浏览量
更新于2024-07-15
收藏 2.24MB PDF 举报
在生物信息学领域,准确预测内在无序蛋白质(Intrinsically Disordered Proteins, IDPs)和区域是至关重要的任务。这些蛋白因其动态结构和功能特性在生物学过程中发挥着独特作用,但传统的结构预测方法往往难以捕捉其复杂的序列模式。为了克服这一挑战,研究人员提出了利用条件随机场(Conditional Random Fields, CRFs)的模型,如IDP-CRF,这是一种序列标注模型,旨在高效地整合序列信息,以便构建出更精确的预测器。
CRFs是一种统计机器学习模型,特别适合处理具有依赖关系的数据,例如在蛋白质序列中的局部和全局顺序效应。与传统的线性模型相比,CRFs能够更好地捕捉和建模序列数据中的复杂关联,这对于识别IDPs中的无序区域至关重要。它们通过定义潜在变量来表示序列片段的标记状态,并通过概率框架计算最可能的标签配置,这有助于提高预测性能。
IDP-CRF的方法论主要包含以下几个步骤:
1. **特征工程**:首先,构建一组特征向量,这些向量反映了蛋白质氨基酸序列的局部和全局性质,如氨基酸类型、二进制编码、位置信息、以及与邻近氨基酸的相互作用等。这些特征能够捕捉到序列中潜在的无序性模式。
2. **模型训练**:利用已标注的IDP/非IDP数据集对CRF模型进行训练。训练过程中,模型学习了不同特征与IDP/非IDP标签之间的条件概率,优化模型参数以最大化似然函数。
3. **序列标注**:对于新的未标注蛋白质序列,通过应用训练好的CRF模型,根据输入特征计算每个位置的条件概率,然后选择具有最高联合概率的标签序列作为预测结果。
4. **性能评估**:通过交叉验证或独立测试集,评估模型的预测性能,如精度、召回率、F1分数等指标,以确保模型在实际应用中的有效性。
尽管CRFs已经在IDP识别中展现出优势,但IDP-CRF模型仍需不断改进,可能包括增强特征选择、考虑更复杂的序列-结构信息、以及集成其他预测算法的结果,以进一步提高预测的准确性和泛化能力。此外,随着深度学习的发展,结合卷积神经网络(Convolutional Neural Networks, CNNs)或Transformer架构可能会成为未来研究的一个方向。
总结来说,IDP-CRF作为一种基于条件随机场的序列标注方法,通过有效利用序列信息,为准确预测内在无序蛋白质/区域提供了一种有力工具,对于理解蛋白质的功能多样性以及开发针对这类蛋白的药物设计策略具有重要意义。
Int. J. Mol. Sci. 2018, 19, 2483 3 of 15
Int. J. Mol. Sci. 2018, 19, x FOR PEER REVIEW 3 of 15
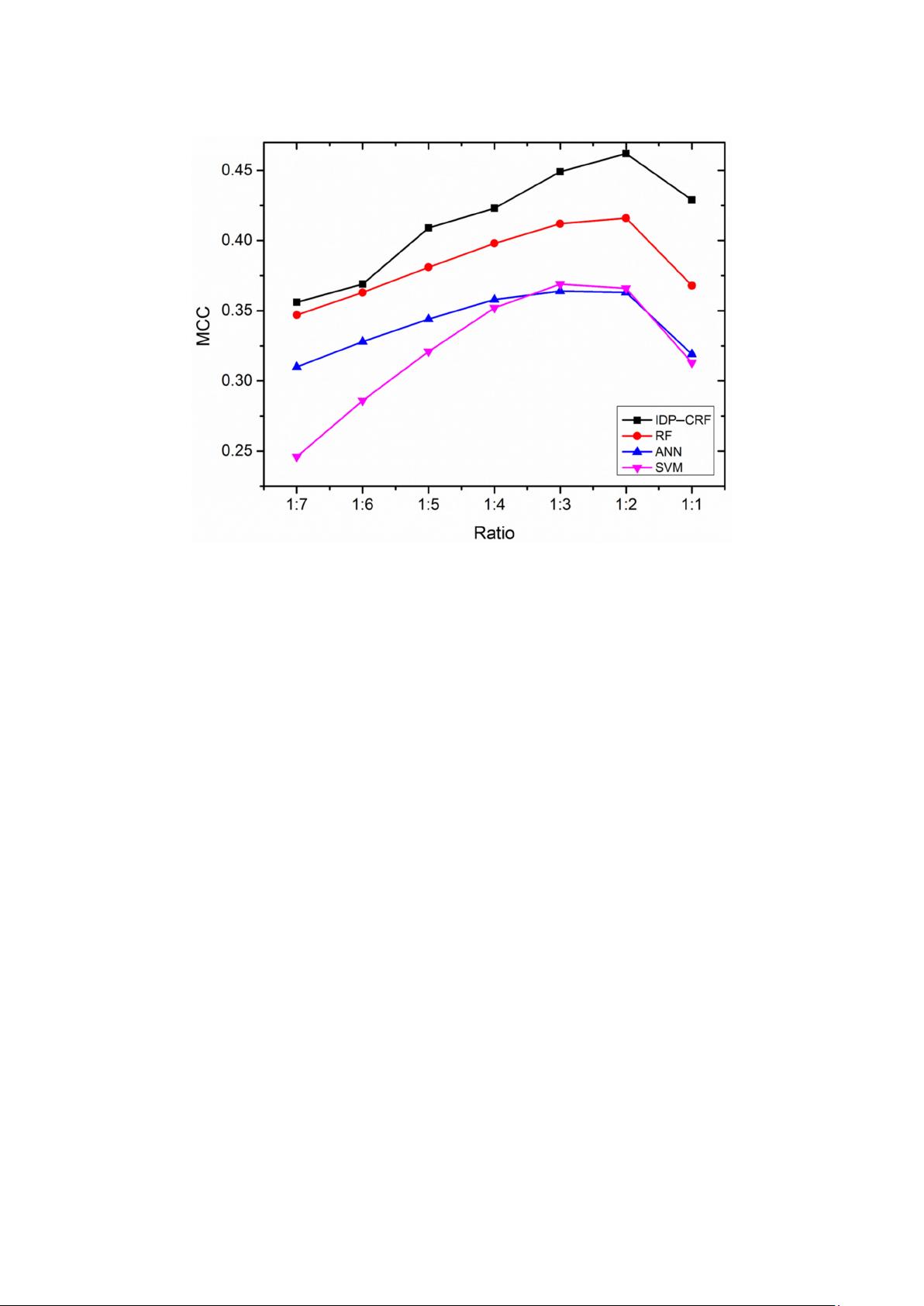
Figure 1. The performance of IDP–CRF (intrinsically disordered protein–conditional random field)
and three classification-based predictors trained with different ratios of disordered residues and
ordered residues. These three classification-based predictors include a RF (random forest) predictor,
an ANN (artificial neural network) predictor and an SVM (support vector machine) predictor. MCC
represents Matthew’s correlation coefficient performance metrics.
2.2. IDP–CRF (Intrinsically Disordered Protein–Conditional Random Field) Outperforms Classification-
Based Predictors
Sequential adjacent residues may have similar characteristics in the formation of IDPs/IDRs [18].
However, traditional classification-based predictors treat each target residue as an independent
sample, ignoring the global sequence patterns of disordered regions. To address this problem, IDP–
CRF, proposed in this study, can take the relationship between labels of sequential adjacent residues
into account. The performance of IDP–CRF and several classification-based predictors (cf. Section 3.1)
is compared by using five-fold cross-validation, and is shown in Table 1. From Table 1, we can see
that IDP–CRF obtains the highest accuracy (ACC). When the positive and negative samples are
extremely unbalanced, although ACC favors “greedy” predictions (i.e., predicting more residues as
disordered), IDP–CRF obtains the highest sensitivity (Sn) and specificity (Sp), indicating that IDP–
CRF can achieve better trade-off between Sn and Sp automatically. Besides, the highest MCC of IDP–
CRF also fully illustrates that it is an efficient predictor for identifying IDPs/IDRs. This is because
IDP–CRF can obtain more information of global sequence patterns of disordered regions compared
with classification-based predictors.
2.3. Several Examples Predicted by IDP–CRF and Three Classification-Based Predictors
In this section, three examples are used to visualize the prediction of the four predictors listed
in Table 1, including IDP–CRF, RF, SVM and ANN. These proteins are 3H2YA, 2ODKA and 4AD4A,
and their structure information is acquired from the PDB database [7]. To visualize the 3D structures
of these proteins, PyMOL [26] software is adopted to generate 3D structures of ordered regions. For
those disordered regions, their 3D structure is drawn manually.
Figure 1.
The performance of IDP–CRF (intrinsically disordered protein–conditional random field) and
three classification-based predictors trained with different ratios of disordered residues and ordered
residues. These three classification-based predictors include a RF (random forest) predictor, an ANN
(artificial neural network) predictor and an SVM (support vector machine) predictor. MCC represents
Matthew’s correlation coefficient performance metrics.
2.2. IDP–CRF (Intrinsically Disordered Protein–Conditional Random Field) Outperforms Classification-Based
Predictors
Sequential adjacent residues may have similar characteristics in the formation of IDPs/IDRs [
18
].
However, traditional classification-based predictors treat each target residue as an independent sample,
ignoring the global sequence patterns of disordered regions. To address this problem, IDP–CRF,
proposed in this study, can take the relationship between labels of sequential adjacent residues into
account. The performance of IDP–CRF and several classification-based predictors (cf. Section 3.1)
is compared by using five-fold cross-validation, and is shown in Table 1. From Table 1, we can
see that IDP–CRF obtains the highest accuracy (ACC). When the positive and negative samples are
extremely unbalanced, although ACC favors “greedy” predictions (i.e., predicting more residues
as disordered), IDP–CRF obtains the highest sensitivity (Sn) and specificity (Sp), indicating that
IDP–CRF can achieve better trade-off between Sn and Sp automatically. Besides, the highest MCC of
IDP–CRF also fully illustrates that it is an efficient predictor for identifying IDPs/IDRs. This is because
IDP–CRF can obtain more information of global sequence patterns of disordered regions compared
with classification-based predictors.
2.3. Several Examples Predicted by IDP–CRF and Three Classification-Based Predictors
In this section, three examples are used to visualize the prediction of the four predictors listed
in Table 1, including IDP–CRF, RF, SVM and ANN. These proteins are 3H2YA, 2ODKA and 4AD4A,
and their structure information is acquired from the PDB database [
7
]. To visualize the 3D structures of
these proteins, PyMOL [
26
] software is adopted to generate 3D structures of ordered regions. For those
disordered regions, their 3D structure is drawn manually.
剩余14页未读,继续阅读
2021-03-31 上传
2021-05-04 上传
789 浏览量
254 浏览量
174 浏览量
179 浏览量
239 浏览量
2025-01-03 上传
286 浏览量
139 浏览量

weixin_38606041
- 粉丝: 5
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- 3-en-raya-1era-parte-:连续3项任务San Pablo
- matlab代码sqrt-coa:用C++编写的布谷鸟优化算法(COA)
- zitiwenjian.rar
- 飞行员:我在硕士论文中创建了一个简单的项目。 它旨在显示用于移动应用程序开发的最流行的跨平台框架的异同。 还包括本机解决方案
- 兰大2018届计算机组成课程PPT
- Dollar:可在heroku中使用的单独的类似FB的应用程序,因为它已在烧瓶上完全堆满并起React
- junfai,matlab中rand的源码,matlab源码之家
- 食品饮料制造业解决方案.rar
- ElectricWow.9o51twf5ei.gahQfEe
- androidtest:android pritace
- react-native-toolbox:一组脚本来简化React Native开发
- 现代hy308手写板驱动 v9.8 官方版
- tns-template-vue:具有TypeScript,PostCSS,Tailwind,Vuex,Vue Router,Webpack等的NativeScript Vue模板
- 算折射率-计算算折射率的一款实用软件包括NK值
- 光线追踪:Projet d'imagerienumérique
- patrick-fulghum.github.io
