Spark 1.4.0与Scala集成开发环境安装与运行指南
需积分: 10 21 浏览量
更新于2024-07-15
收藏 2.84MB DOCX 举报
第四章详细介绍了如何在Linux系统中集成Spark与Scala的开发环境,以便进行大数据处理。首先,确保系统已安装Java Development Kit (JDK),因为Spark通常与Java紧密关联。这里提供了升级JDK到OpenJDK 8的步骤,包括添加PPA源、更新源、安装新版本并将其设置为默认Java环境。在安装过程中,建议检查网络连接,因为安装可能因网络速度而有所不同。
在Spark版本方面,推荐使用1.4.0版本,用户需要解压它到`/usr/local/spark`目录,并对`spark-env.sh`文件进行相应配置,以确保环境变量正确。运行`spark-shell`命令时,将看到所安装的Spark版本信息,这表明环境已经准备就绪。
Scala的集成同样重要,因为它是Spark的主要编程语言。用户需要下载Scala 2.11.6版本,并将其配置到系统路径中。如果在之前的教程中已经完成了这一步,可以跳过。下载完成后,配置环境变量以确保Scala可被系统识别。
此外,章节还指导用户下载和安装Eclipse Scala IDE,这是开发Scala应用程序的常用工具。用户可以从scala-ide.org网站下载最新版本,然后将其解压至桌面。接着,用户需要创建一个工作区,例如`~/workspace/Lib`,并将Spark安装目录下的`jars`文件夹中的必要jar包,如Joda-time和jfr,复制到工作区中。
在整个过程中,确保所有依赖的库和环境都已经正确配置,这对于Spark和Scala项目的顺利运行至关重要。通过遵循这些步骤,开发者可以在Linux系统上搭建一个完整的Spark与Scala集成开发环境,从而有效地进行大数据分析和处理。
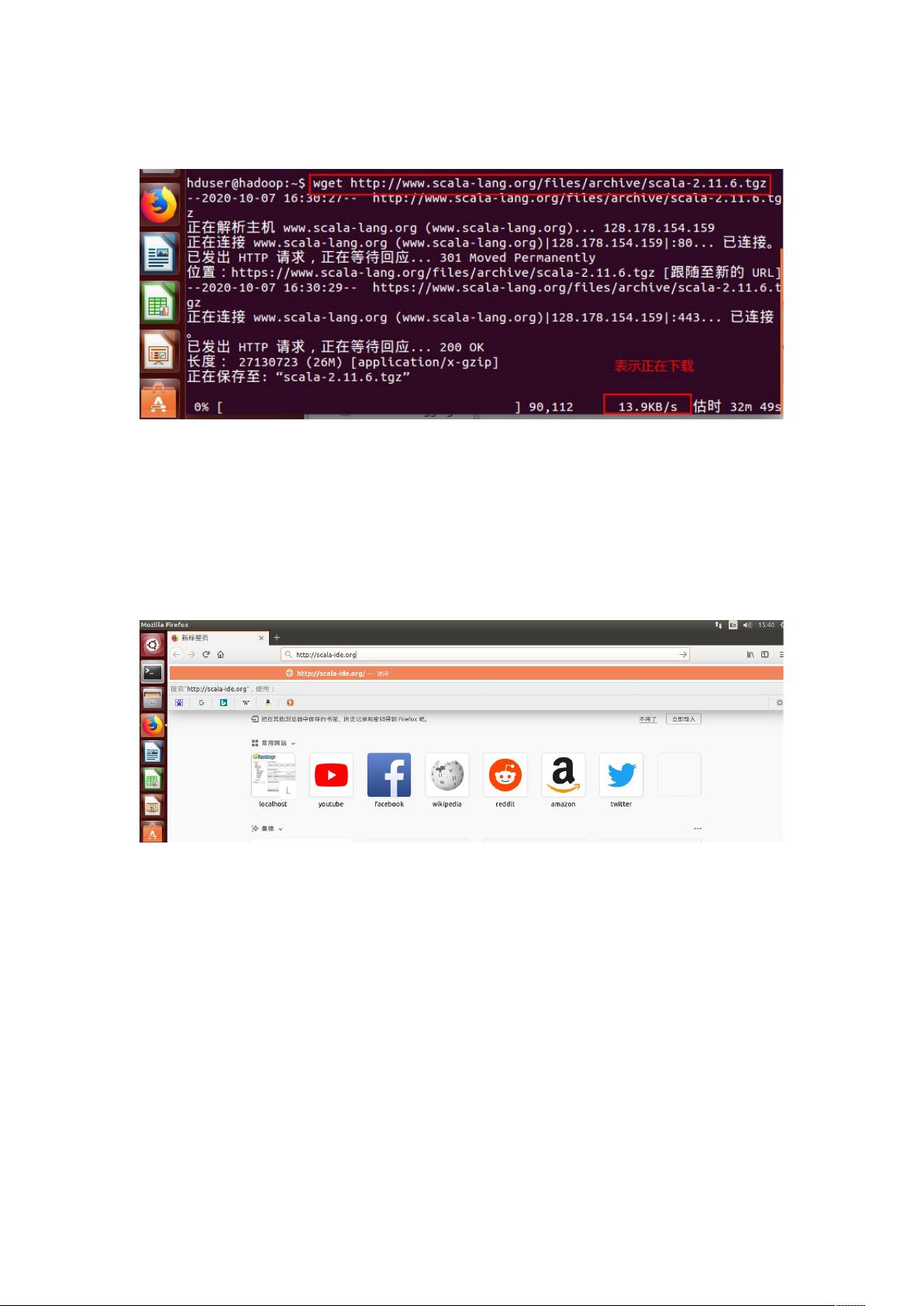
已经下载,这个步骤可以忽略
wget http://www.scala-lang.org/*les/archive/scala-2.11.6.tgz
下载完成记得配置环境变量,此步骤不再赘述。
下载与安装 Eclipse Scala IDE
http://scala-ide.org
点击“Download IDE”下载
剩余15页未读,继续阅读
2020-10-25 上传
2024-07-12 上传
2022-01-04 上传
2024-07-12 上传
2022-10-20 上传
2021-04-26 上传
2021-12-05 上传
2023-06-05 上传
2023-03-06 上传

sun_com1984
- 粉丝: 15
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
