优化支持向量机:目标函数与决策边界解析
需积分: 10 37 浏览量
更新于2024-07-16
收藏 1.55MB PDF 举报
本资源是一份名为《Support_Vector_Machines.pdf》的文档,主要内容涵盖了支持向量机(Support Vector Machines, SVM)这一强大的机器学习算法的基础理论和实践应用。文档由讲师Dr. Bo Yuan撰写,其电子邮箱为yuanb@sz.tsinghua.edu.cn。
首先,文档从线性分类器开始,阐述了如何通过线性函数w·x + b来判断样本点的类别,其中w是权重向量,b是偏置项。根据符号,样本被分为三个区域:w·x + b > 0,w·x + b < 0 和 w·x + b = 0,分别对应正例、负例和决策边界。决策边界(或称为超平面)与数据点之间的距离,即距离超平面最近的数据点到超平面的距离,被称为间隔(Margin),这对于SVM模型的泛化能力至关重要。
在第4部分,文档详细解释了间隔的概念,它衡量了模型对未知样本的预测能力。一个具有较大间隔的模型意味着它能更好地避免过拟合,即在训练集上表现很好但在新数据上的表现也强。支持向量(Support Vectors)是定义间隔的关键,因为它们位于边界两侧,且决定了超平面的位置。实际上,模型主要由这些支持向量决定,其他远离超平面的样本对模型的影响较小。
接着,第5节讨论了选择最佳分类器的问题。虽然所有分类器在训练集上的错误率可能相同,但考虑泛化性能时,选择具有更大间隔(更宽的“安全区”)的模型更为重要。这意味着模型不仅对已知数据点分类准确,还能处理未知数据。
文档的最后一部分深入探讨了支持向量的选择过程,强调了在众多数据点中,只有少数关键的支持向量对模型起决定作用。理解和支持向量的性质有助于优化模型,提高其稳健性和准确性。
《Support_Vector_Machines.pdf》提供了对支持向量机工作原理的深入分析,包括目标函数的优化、参数求解策略、线性和非线性SVM的区别,以及如何通过选择具有大间隔的模型来提升机器学习模型的性能。这份文档对于理解和支持向量机在实际问题中的应用具有很高的价值。
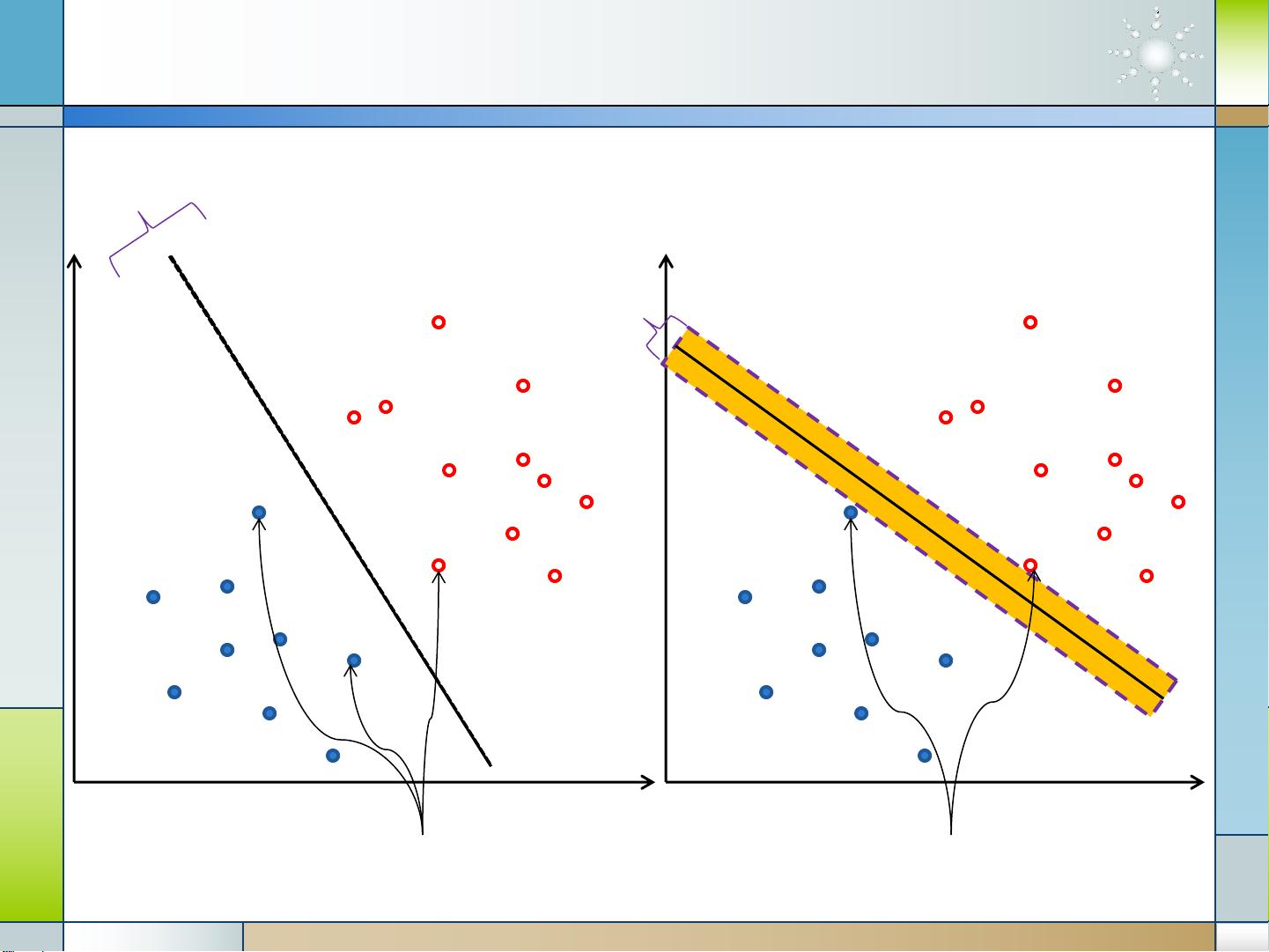
Margins
7
Support Vectors Support Vectors
margin
剩余35页未读,继续阅读
2009-04-25 上传
2015-05-31 上传
2024-12-28 上传
2024-12-28 上传
2024-12-28 上传
2024-12-28 上传

呆小呆_
- 粉丝: 178
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- reva-cplusplus:C ++ Rev.a示例
- flamedfury.com:在neocities.org上托管的flamedfury.com静态网站
- EPCOS铝电解电容规格书.rar
- dzpzy98.github.io:投资组合网站
- SDRunoPlugin_drm:SDRuno的实验性DRM插件
- 职称考试模拟系统asp毕业设计(源代码+论文).zip
- DatingApp
- tokenize:用于身份验证的通用令牌格式。 旨在安全、灵活且可在任何地方使用
- Heart Disease UCI 心脏病UCI-数据集
- A5Orchestrator-1.0.3-py3-none-any.whl.zip
- PyDoorbell:基于Micropython微控制器的门铃
- ohr-point-n-click:OHR社区点击冒险游戏
- 仿ios加载框和自定义Toast带动画效果
- sqlalchemy挑战
- 西门子S7300的十层电梯程序.rar
- tabletkat:KitKat 的真正平板电脑用户界面
