理解SVM:支持向量机入门与解析
需积分: 10 91 浏览量
更新于2024-07-28
收藏 541KB PDF 举报
"这篇资源是关于SVM(支持向量机)的入门教程,适合想要学习SVM的人群。文章介绍了SVM的基本概念、理论基础和应用优势,并对其核心思想进行了详细解读。"
支持向量机(Support Vector Machine,简称SVM)是一种强大的监督学习算法,主要用于分类和回归分析。由Cortes和Vapnik于1995年提出,SVM在处理小样本、非线性和高维度数据时展现出优越性能。它不仅在模式识别领域有广泛应用,还能扩展到函数拟合等其他机器学习任务。
SVM的理论基础主要建立在统计学习理论的VC维理论和结构风险最小化原则。VC维是衡量一个函数类复杂度的指标,较高的VC维意味着问题更复杂。SVM的独特之处在于,它不受样本维数限制,即使面对高维数据也能有效处理,这得益于其引入的核函数技术,使其在处理如文本分类等问题时特别高效。
结构风险最小化是SVM优化目标的核心。在机器学习中,由于无法直接获取真实模型,我们只能找到一个近似模型,即假设。结构风险最小化就是在未知真实模型的情况下,寻找最接近理想解的假设,平衡模型的复杂度和泛化能力。这一理念有助于避免过拟合,提高模型在新数据上的预测能力。
传统的机器学习方法往往缺乏理论指导,而SVM基于统计学习理论,为模型选择和评估提供了明确的框架。通过选择最优的决策边界(称为最大间隔超平面),SVM确保了对未知数据的良好泛化性能。
在实际应用中,SVM通过核函数将低维数据映射到高维空间,寻找能够最好分离各类别的超平面。常见的核函数有线性核、多项式核、高斯核(RBF)等,不同的核函数适用于不同的数据分布。
SVM是一种强大且灵活的机器学习工具,它的理论严谨性、泛化能力和处理高维数据的能力使其在众多机器学习算法中脱颖而出。对于初学者,理解SVM的基础概念、核心思想以及如何选择合适的核函数是掌握SVM的关键。通过深入学习SVM,可以为解决实际问题提供有力的算法支持。
那么 wxi+b<0,而 yi 也小于 0,这意味着 yi(wxi+b)总是大于 0 的,而且它的值就等 于|wxi+b|!
(也就是|g(xi)|)
现在把 w 和 b 进行一下归一化,即用 w/||w||和 b/||w||分别代替原来的 w 和 b,那么间隔
就可以写成
这个公式是不是看上去有点眼熟?没错,这不就是解析几何中点 xi 到直线 g(x)=0 的距
离公式嘛!(推广一下,是到超平面 g(x)=0 的距离, g(x)=0 就是上节中提到的分类超平面)
小Tips:||w||是什么符号?||w||叫做向量 w 的范数,范数是对向量长度的一种度量。我
们常说的向量长度其实指的是它的 2-范数,范数最一般的表示形式为 p-范数,可以写成如
下表达式
向量w=(w1, w2, w3,…… wn)
它的p-范数为
看看把 p 换成 2 的时候,不就是传统的向量长度么?当我们不指明 p 的时候,就像||w||
这样使用时,就意味着我们不关心 p 的值,用几范数都可以;或者上文已经提到了 p 的值,
为了叙述方便不再重复指明。
当用归一化的 w 和 b 代替原值之后的间隔有一个专门的名称,叫做几何间隔,几何间
隔所表示的正是点到超平面的欧氏距离,我们下面就简称几何间隔为“距 离”。以上是单个
点到某个超平面的距离(就是间隔,后面不再区别这两个词)定义,同样可以定义一个点的
集合(就是一组样本)到某个超平面的距离为此集合中 离超平面最近的点的距离。下面这
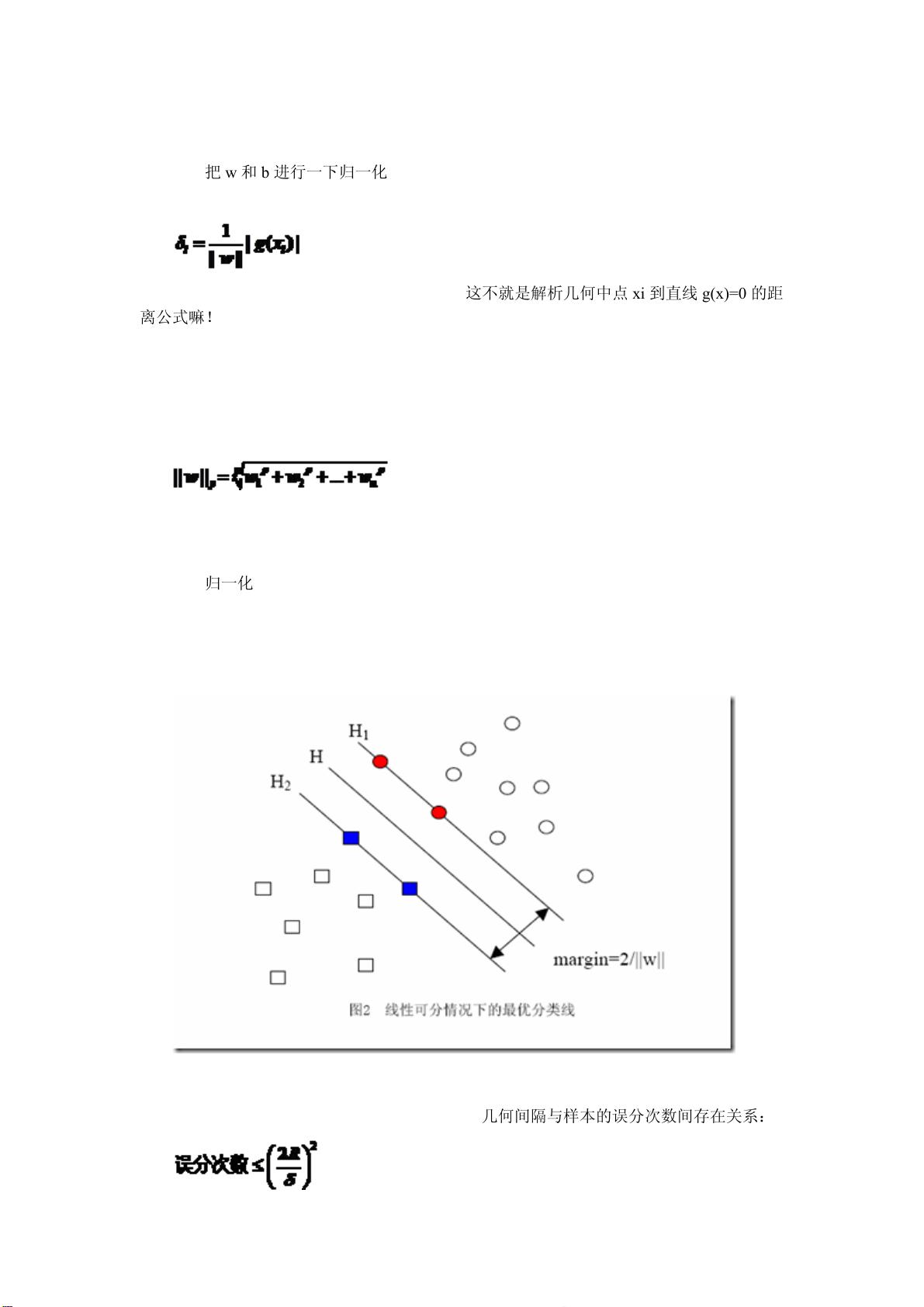
张图更加直观的展示出了几何间隔的现实含义:
H 是分类面,而 H1 和 H2 是平行于 H,且过离 H 最近的两类样本的直线,H1 与 H,
H2 与 H 之间的距离就是几何间隔。
之所以如此关心几何间隔这个东西,是因为几何间隔与样本的误分次数间存在关系:
剩余19页未读,继续阅读
2022-07-08 上传
2010-12-15 上传
点击了解资源详情
2009-09-14 上传

lcplj123
- 粉丝: 3
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
