远场语音识别关键:噪声抑制与声源定位技术详解
需积分: 9 144 浏览量
更新于2024-09-08
收藏 1.25MB DOCX 举报
语音前端处理在远场语音识别场景中扮演着至关重要的角色,它面对的主要挑战包括噪声抑制、声源定位、回声消除以及混响消除等。本文将重点讨论这些关键技术及其在实际应用中的解决策略。
首先,噪声抑制是前端处理的核心任务,它包括加性噪声背景噪声的减少和干扰信号的处理。环境噪声可能来自各种来源,如交通噪音、空调声等,需要通过先进的降噪算法,如谱减法、Wiener滤波等,有效地削弱这些背景噪音。同时,对于竞争性声源的干扰,如多人对话或同频设备的干扰,需要精确的信号分离技术,如深度学习的语音分离网络,以区分目标语音与其他声源。
回声消除是针对麦克风阵列设备内部或外部反射产生的声音,如语音播放后产生的回声。常见的方法有自适应滤波器和基于时延的算法,如延迟反相、RLS( Recursive Least Squares)等。通过参考信号对回声进行精确的时间延迟估计和信号合成,以消除回声对语音质量的影响。
混响消除则是针对声源停止后室内空间中的残留声音,通常通过调整声学模型,如基于物理模型的混响计算,或者采用统计建模的方法,如Non-negative Transfer Function (NTT)去混响算法(如WPE)。混响时间T60的估计至关重要,过短可能导致声音缺乏空间感,过长则可能使语音模糊不清。在实际操作中,波束形成方法结合逆滤波技术常被用于混响抑制,但逆滤波面临的困难在于混响模型的实时估计。
多通道处理模块是前端处理的重要组成部分,利用麦克风阵列的优势,通过多路信号的融合,可以提高声源定位的精度,从而更有效地执行波束形成,增强目标语音并抑制其他方向的干扰。同时,混响消除也可以先进行多通道处理,然后针对单通道进行细化,确保输出语音的清晰度。
语音前端处理的关键技术包括噪声抑制、声源定位与波束形成、回声消除以及混响消除。这些技术的进步直接影响到远场语音识别系统的性能,尤其是在复杂的环境条件下。随着深度学习和人工智能的发展,未来的研究将更加侧重于提高这些技术的鲁棒性和效率,以提供更优质的语音交互体验。
智能语音前端处理中有哪些关键问题需要解决
1. 噪声源
.来自于各种环境声源的加性噪声(background noise) ---噪声抑制(noise reducon)
.来自于其他竞争性声源的干扰信号(interference)
.由设备自身发出的回声(echo) ---回声消除(echo cancellaon)
.由遮挡物引起的多径传播所导致的混响(reverberaon) ---混响消除(de-reverberaon)
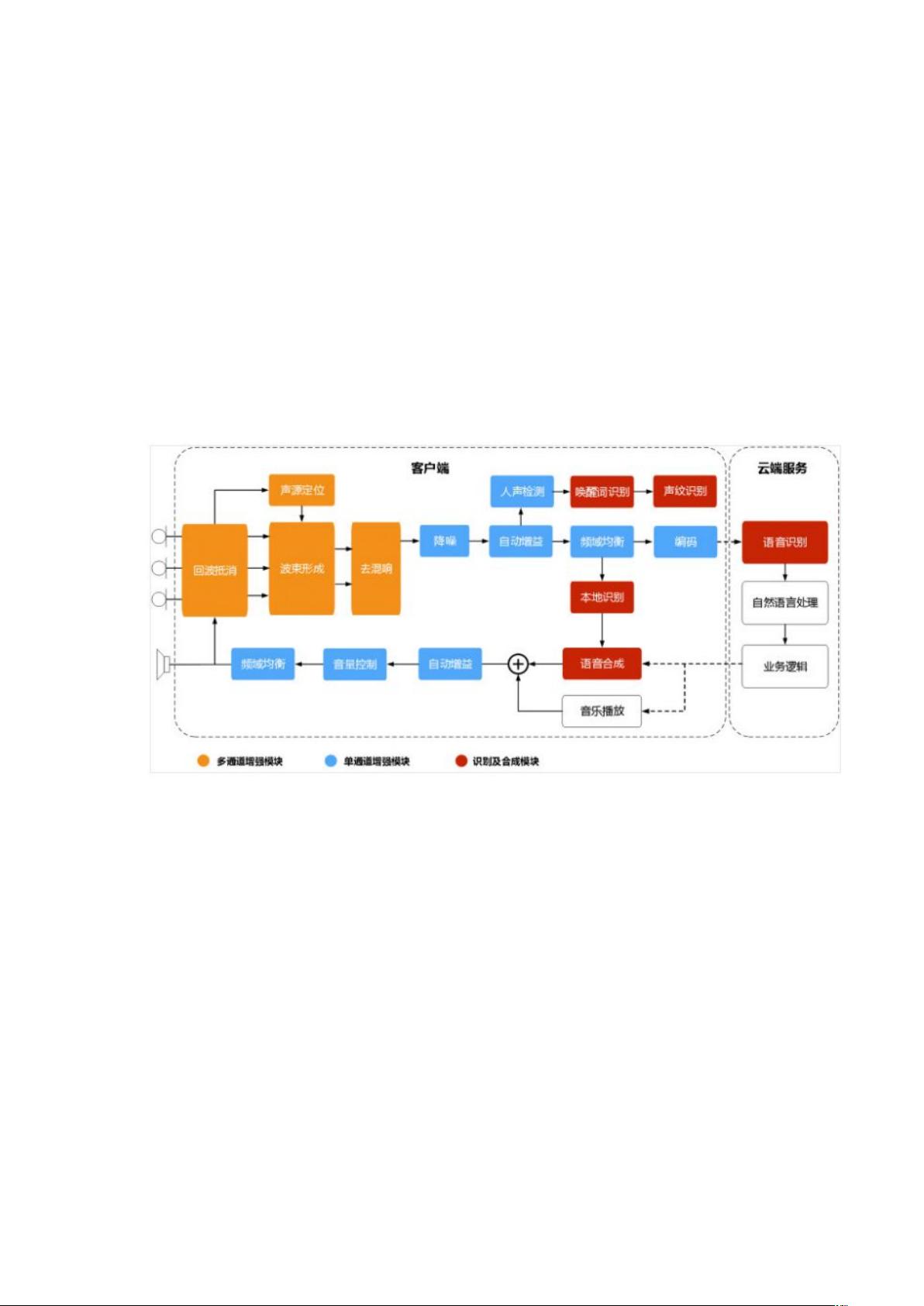
2. 语音前端处理模块 + 语音交互系统
橙色部分:多通道处理模块
蓝色部分:单通道处理模块
红色部分:后端语音识别和合成等模块
处理过程:麦克风阵列采集的语音首先利用参考源对各通道的信号进行回波消除,然后确
定声源的方向信息,进而通过波束形成算法来增强目标方向的声音,再通过混响消除方法
抑制混响;需要强调的是可以先进行多通道混响消除再进行波束形成,也可以先进行波束
形成再进行单通道混响消除。经过上述处理后的单路语音进行后置滤波消除残留的音乐噪
声,然后通过自动增益算法调节各个频带的能量后作为前端处理的输出,将输出的音频传
递给后端进行识别和理解
(个人理解:波束形成可以增强目标方向的语音,抑制其他方向的干扰噪声,因此多通
道融合增强后的语音,可以分解为两部分:目标语音成分和残留噪声成分。残留噪声成分
可以通过后置滤波算法进一步处理,也可以通过改进麦克风阵列波束形成算法使这一成分
得到有效抑制。波束形成技术很依赖 DOA,DOA 估计在噪声下的鲁棒性很差,如果 DOA 估
计错会导致波束形成结果也会错。所以如果 DOA 估计在强噪声环境下的鲁棒性很好---->波
束形成起作用--->避免 NTT 去混响算法(WPE)失效)
下载后可阅读完整内容,剩余9页未读,立即下载
2018-07-27 上传
点击了解资源详情
2019-01-28 上传
177 浏览量
2020-12-10 上传
2021-08-12 上传
2023-08-31 上传

tonight1103
- 粉丝: 13
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++创建和删除快捷方式,添加程序组菜单
- BoltzmannMachinesRPlots
- 4-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- Bluebird.WkBrowser:超级基本的Web浏览器,使用WkWebView和Xamarin.Mac。 旨在作为WkWebView兼容性问题的测试工具
- ReactWebpack
- imageflow-prototype:新 WordPress Image Flow 的工作响应原型 - 不与 WordPress 数据集成
- gfg-coding-problems:解决编码问题
- Mohamed-Bengrich.com
- behrtheme:基于Susty WP的Behr Immobilien的WordPress主题
- symfony-angular-seed:基于API(symfony2)和前端(Angular)的种子项目
- VC++让程序在开机启动时就自动运行
- Gprinter_2020.4_M-2.zip
- AT89S52+AT24C010+DAC0832+MAX7128SLC84-15+按键+LCD+7805组成的原理图和PCB电路
- Frontend-01-模板
- Raw JSON Library:原始JSON库(RJL)是一种高性能JSON(符合RFC 4627)-开源
- 通俗易懂的Go语言教程第4季(含配套资料)
