视觉CIRL:自动驾驶模拟器中的高效率策略学习
22 浏览量
更新于2024-06-20
收藏 770KB PDF 举报
本文主要探讨了一种名为"CIRL"(Controlled Imitation Reinforcement Learning)的方法,它在基于视觉的自动驾驶领域展现出了显著的性能。CIRL作为一种创新的学习策略,旨在解决自动驾驶面临的主要挑战,即学习复杂的多智能体动力学和制定有效的驾驶策略。传统的方法往往依赖于手工设计的规则和预处理感知系统,而这些在处理真实世界动态和多样化的驾驶场景时显得力有不逮。
CIRL的核心理念是将模仿学习与强化学习相结合。在模仿阶段,通过大规模的监督学习,系统首先利用人类驾驶数据来训练一个基础模型,学习如何理解和响应驾驶环境。这一步骤借鉴了大规模视觉感知任务的研究成果,如目标检测和车道定位,但重点在于构建一个能够理解并适应复杂交通规则和动态交互的策略。
强化学习阶段则是CIRL的关键部分,它在高保真的汽车模拟器中进行。通过引入合理的动作空间约束,这个阶段限制了模型的探索范围,使其能更有效地在大动作空间中学习。模仿人类驾驶的编码经验被用来指导这一过程,使用深度确定性策略梯度(DDPG)算法,进一步提升学习效率和性能。
文章强调了对不同控制信号(如跟随、直行、右转、左转)的专门设计,目的是增强模型处理各种驾驶情境的能力,这对于自动驾驶在实际应用中的适应性和灵活性至关重要。实验结果在CARLA驾驶基准上显示,CIRL在完成目标导向驾驶任务的百分比上明显优于先前的所有方法,显示出其在复杂环境中的优异性能和泛化能力。
值得一提的是,CIRL是首个在高保真模拟器中通过强化学习成功学习驾驶策略且表现优于监督模仿学习的案例。这标志着在自动驾驶领域,混合模仿和强化学习方法正在逐步突破传统的局限,朝着更加智能、灵活和自适应的方向发展。
CIRL方法在视觉自动驾驶中的成功,不仅证明了它在解决实际驾驶问题上的有效性,也对未来自动驾驶技术的发展方向提供了新的思考视角。它的优势在于结合了模仿学习的稳定性和强化学习的灵活性,为复杂道路环境下的智能驾驶提供了强有力的支持。
4
X. Liang,T.王湖,加-地Yang和E.邢
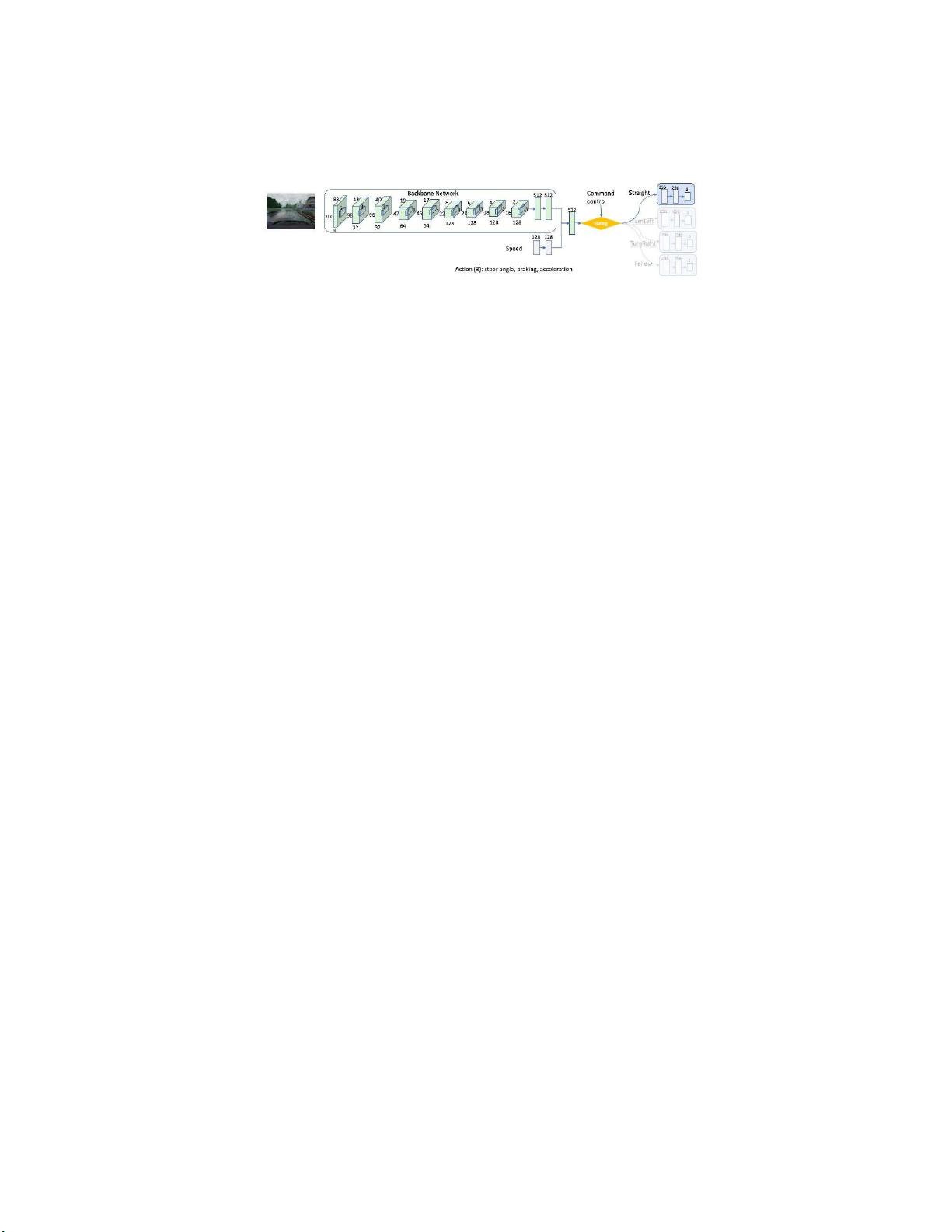
图二. CIRL的Actor网络体系结构。门控功能选择性地激活不同的分支,以预测“直行”、
“左转”、“右转”和“跟随”命令的三个动作。
narios和dynamic需要大量的人的参与,并且是不切实际的,因为我们不能覆盖
可能发生的所有可能的情况。从技术方面来看,与这些作品不同,我们的CIRL
旨在学习先进的政策,通过与模拟器的交互,由模仿学习引导,面向更多和一
般复杂的城市驾驶场景。此外,不同的异常转向角奖励定义为每个控制信号,
使模型学习连贯的专门政策与人类常识。
自动驾驶的强化学习。强化学习通过试错的方式学习,不需要人类的明确监
督。Deep-RL或RL算法已被应用于各种各样的任务,例如ob-RL。 物体识别
[19,14,9,3,18],计算机游戏[23],机器人运动[7],场景导航[40]和模拟器
中的自动驾驶[1,30,37]。现实世界应用中最关键的学习使用这样的穷举探索
的最优策略往往是非常耗时的,并且容易陷入局部最优后,许多事件。因此,
期望找到可以帮助加速探索的可行的行动空间我们的CIRL解决了这个问题,利
用模仿学习的经验来指导强化驱动代理。
有一些以前的工作也研究了模仿学习的力量。生成对抗模仿学习(GAIL
[12])构建了一个生成模型,这是一种随机策略,产生与专家演示类似的行为。
In-foGAIL [17]将GAIL扩展为一种策略,其中可以通过更抽象的高级潜变量来控
制低级操作。与我们最相似的工作是DQfD [11],[16]和DDPGfD [34],它们结合
了Deep Q Networks(DQN)和从演示中学习。然而,DQfD仅限于具有离散动作
空间的域,DQfD [16]和DDPGfD不适用于具有显著不同的行动者-批评者、动作
空间和奖励定义的自动驾驶。此外,与将演示转换加载到重放缓冲区的DDPGfD
不同,我们直接使用演示中的知识来指导强化探索,通过模仿学习用预训练的模
型参数初始化演员网络。实验结果表明,该策略在自动驾驶模拟器中的应用效果
优于DDPGfD。
剩余15页未读,继续阅读
2021-02-25 上传
2021-04-24 上传
2024-01-12 上传
2023-08-27 上传
2023-06-12 上传
2024-10-13 上传
2024-10-13 上传
2024-10-13 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
