Linux环境下Redis集群详细部署指南
需积分: 13 148 浏览量
更新于2024-09-07
收藏 201KB DOCX 举报
"Linux Redis集群部署涉及多个方面,包括Redis Cluster的特性和架构,以及实际的安装步骤。Redis从3.0版本开始支持Cluster特性,提供了节点自动发现、主从选举、热分片、集群管理等功能,确保高可用性和数据安全性。在Redis Cluster的架构中,所有节点相互连接,通过多数节点确认来检测故障,并将数据分布到slots上。客户端可以直接连接任何节点进行操作。选举过程依赖于大多数master节点的状态,当master节点挂掉且无slave或超过半数master挂掉时,集群会进入不可用状态。安装Redis Cluster需要下载源码、编译并创建多个节点,通常会在多台服务器上部署。"
在详细说明部分,Redis Cluster是Redis实现分布式存储的一种方式,它引入了新的特性和架构设计以提高系统的可扩展性和高可用性。以下是关于Redis Cluster的详细知识点:
1. **节点自动发现**:新加入的节点可以通过Gossip协议自动发现集群中的其他节点,无需人工干预。
2. **主从选举**(slave-to-master promotion):当master节点故障时,其对应的slave节点可以被其他节点选举为新的master,以保证服务的连续性。
3. **热分片(Hotresharding)**:在不中断服务的情况下,数据可以在不同节点间迁移,实现动态扩容和负载均衡。
4. **集群管理命令**(cluster commands):如`cluster info`、`cluster nodes`等,方便用户监控和管理集群状态。
5. **基于配置的集群管理**:通过`nodes-port.conf`文件可以手动配置和调整集群设置。
6. **ASK和MOVED转向机制**:当客户端请求的键在当前节点上不存在时,节点会返回ASK或MOVED响应,指导客户端向正确的节点发送请求。
在Redis Cluster的架构中:
- 所有节点通过PING-PONG机制保持通信,使用二进制协议提升通信效率。
- 节点失效的判断基于多数原则,当超过半数节点认为某个节点失效,该节点才会被标记为失效。
- 数据分布在16384个槽(slots)上,每个节点负责一部分槽,保证数据分散存储。
- 客户端可以连接集群中的任意一个节点进行读写操作,集群会自动处理数据路由。
安装Redis Cluster通常包括以下步骤:
1. **下载Redis源码**:从官方网站获取最新稳定版本。
2. **解压并编译**:在Linux环境下,使用`tar`解压缩,然后使用`make`和`make install`命令编译并安装。
3. **创建Redis节点**:在多台服务器上分别启动Redis实例,配置集群参数,如`cluster-enabled yes`和`cluster-config-file nodes.conf`。
实际部署时,需要考虑网络配置、数据同步策略、故障恢复计划以及监控体系的建立,以确保Redis Cluster的稳定运行。同时,对于Java开发者来说,理解如何在Java应用中集成和使用Redis Cluster也至关重要,这可能涉及到Jedis或Lettuce等客户端库的配置和操作。
一、概述介绍
版本之后支持
、 的现状
目前 支持的 特性:
节点自动发现
选举集群容错
在线分片
进群管理!!!
"基于配置#$%的集群管理
&'()转向*+,-./转向机制
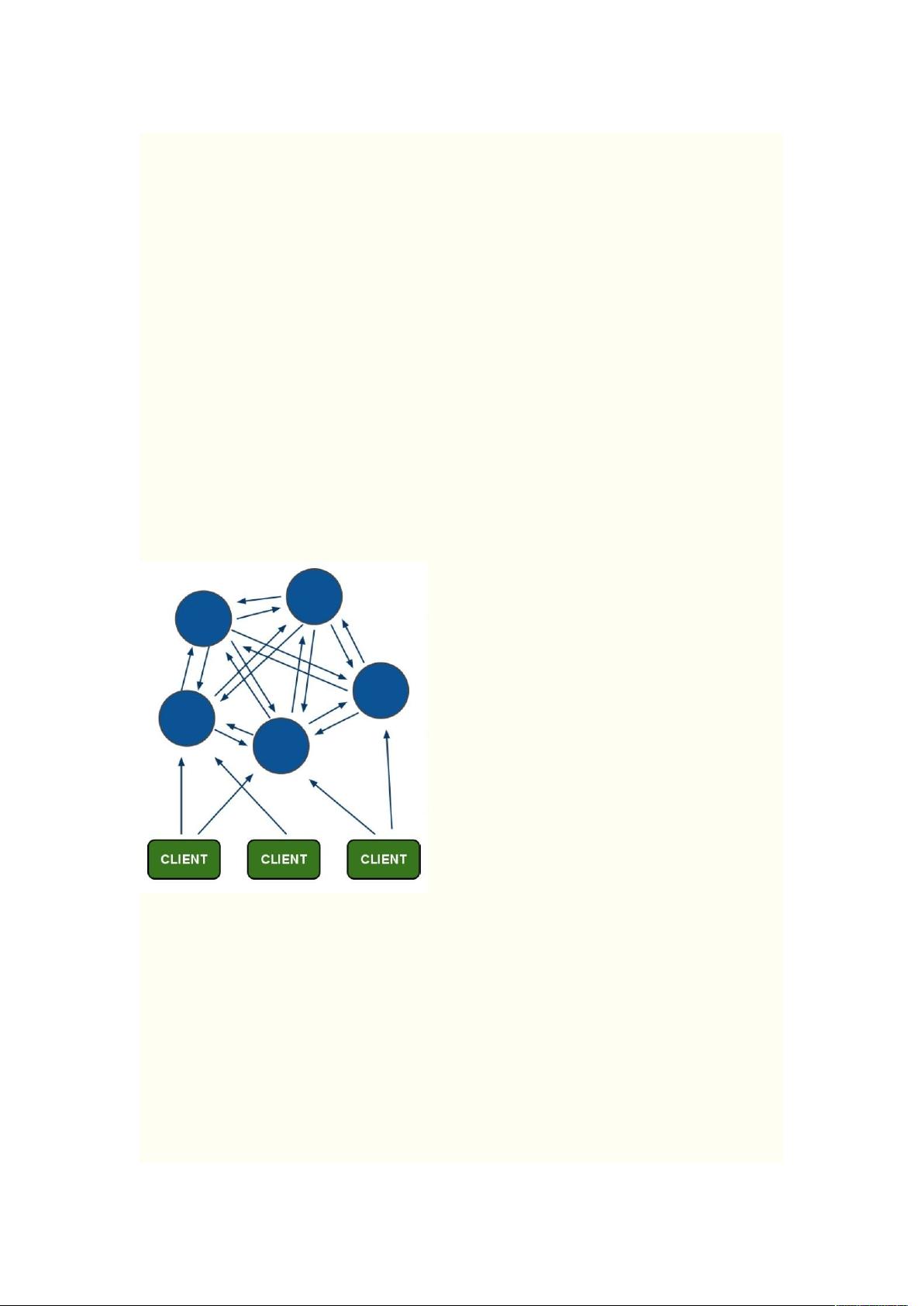
、架构
架构图
架构细节
#所有的 节点彼此互联#01230,23 机制内部使用二进制协议优化传输速度和带宽
#节点的 % 是通过集群中超过半数的节点检测失效时才生效
#客户端与 节点直连不需要中间 $!4 层客户端不需要连接集群所有节点连接集群中
任何一个可用节点即可
# 把所有的物理节点映射到5&67 上负责维护 8
8
下载后可阅读完整内容,剩余7页未读,立即下载
2019-09-18 上传
2018-06-19 上传
2018-05-31 上传
2018-03-30 上传
2020-07-15 上传
2019-05-21 上传
点击了解资源详情

whb_lff
- 粉丝: 17
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
