Google文件系统架构解析
需积分: 9 78 浏览量
更新于2024-07-28
收藏 1.15MB PDF 举报
"Google File System (GFS)是Google公司设计的一种分布式文件系统,用于支撑大规模数据处理的应用。本资源是一份来自北航云计算课程的课件,详细讲解了GFS的设计理念、架构以及功能。内容由邓侃、朱小杰和李小吉撰写,并在SmartClouder.com上分享。"
GFS,全称Google File System,是Google为解决海量数据存储和处理而创建的一个高性能、可扩展的分布式文件系统。GFS的设计目标是支持大规模的并行计算任务,如MapReduce,它为大规模数据处理提供了高效的数据访问机制。
在GFS的架构中,文件系统的元数据(包括文件名、大小、类型、时间戳等)以树形结构进行组织。文件和目录通过一个自定义的数据结构表示,这个结构包含目录ID、子目录ID和文件ID。每个节点包含元数据和存储块ID,用于定位文件的实际存储位置。
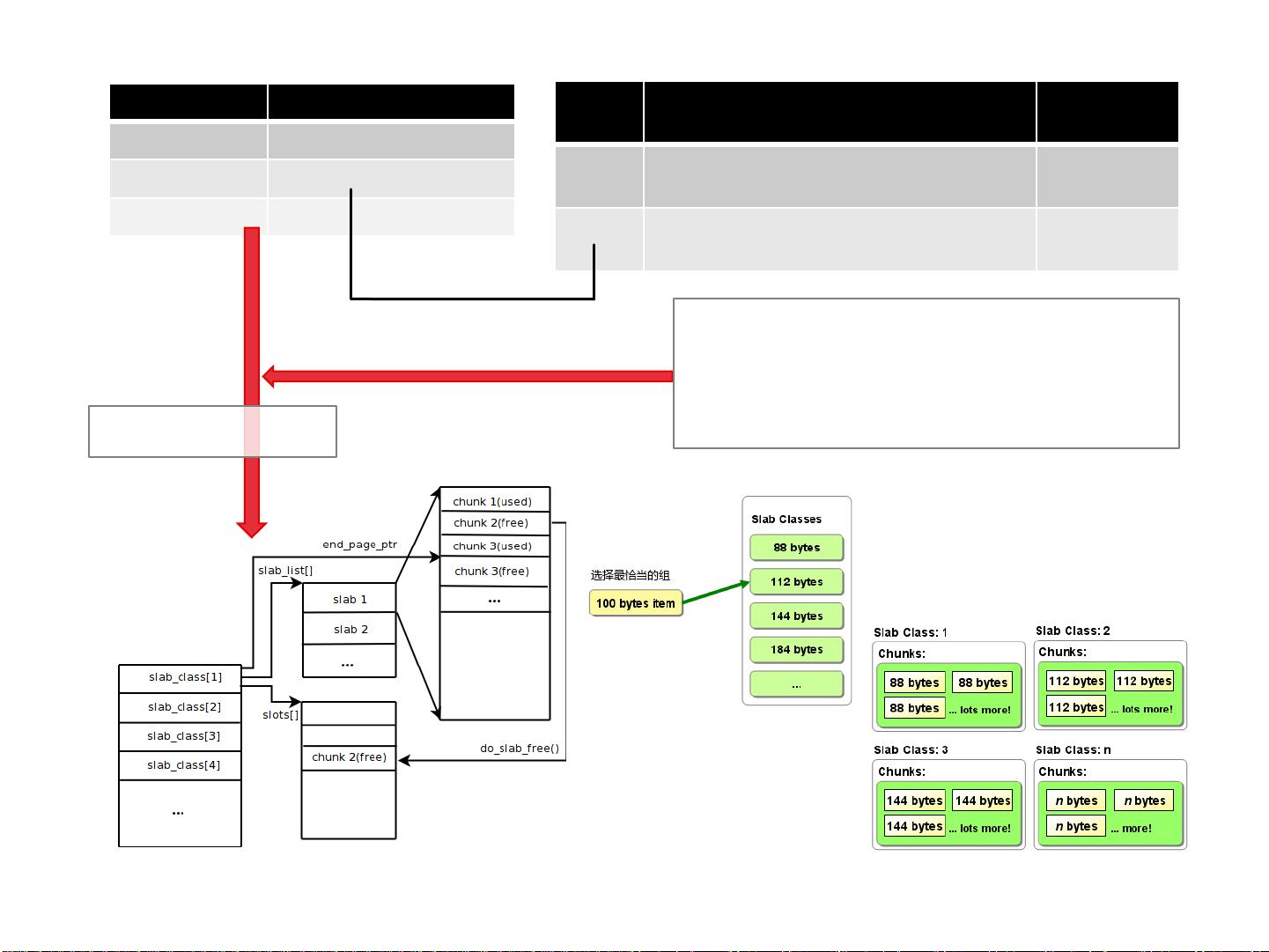
GFS的关键设计之一是将存储空间划分为固定大小的Slabs。Slab类是一组相同大小的Slabs集合,每个Slab可以分割成多个相同大小的Chunks。Chunks是文件数据的基本单位,便于分布和复制。此外,每个Slab还有一个Slots列表,用于记录可重用的Chunks地址。这种设计简化了存储空间的管理和回收,但可能导致存储空间的浪费。
系统架构师在设计GFS时遵循三个基本步骤:首先定义数据结构,然后确定工作流程,最后设计模块及其部署位置。文件系统的基础数据结构包括目录和文件的树形结构,以及元数据和物理存储地址。
在功能方面,GFS支持常见的文件操作,如创建、截断、删除、读取、写入、寻址、打开和关闭。其分布式特性允许数据的多副本存储,增强了容错性和可用性。每个文件被分割成多个Chunks,每个Chunk通常在多个机器上复制,确保即使部分硬件故障,数据仍然可以被访问。
GFS的工作流程包括主服务器(Master)和Chunk服务器(Chunkserver)。主服务器负责元数据管理,包括文件到Chunk的映射,Chunk的位置信息,以及Chunk的复制策略。Chunk服务器则实际存储Chunks,并处理来自客户端的读写请求。主服务器和Chunk服务器之间的通信保证了文件系统的协调和一致性。
通过这种方式,GFS能够在大型集群中高效地处理PB级别的数据,为Google的各类服务提供强大的后端支持,如搜索引擎、数据分析等。其设计思想和实现方式对后来的分布式文件系统,如Hadoop的HDFS,产生了深远影响。
Node
ID
Metadata
Storage
Chunk ID
22
theNameOfADir|20120306|24(Number of
subdirs and files)
NIL
32
theNameOfAFile|20120306|1024 (File
Size)
3A28C329, …
Directory ID
Subdir IDs & File IDs
1
21,22,
21
31,32,33,…
22
34, 35, …
/ 30
6
% fappend
/home/user/test.txt
“content added to the tail …”
Workflow
剩余29页未读,继续阅读
2011-06-30 上传
2021-03-29 上传
2021-01-28 上传
2024-03-22 上传
2018-08-20 上传
2018-12-27 上传
2017-11-09 上传
2021-09-29 上传

buaacloud
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
