Spark大数据技术详解:从基础到实战
需积分: 9 96 浏览量
更新于2024-07-17
收藏 45.87MB DOCX 举报
"这份文档详细介绍了大数据技术中的Spark框架,涵盖了Spark的基本概念、集群安装步骤以及如何执行Spark程序。文档适合学习和教学使用,旨在帮助读者深入理解Spark的特性和应用。"
Spark作为一款强大的大数据处理框架,由Apache基金会维护,自2010年开源以来,因其高效的内存计算和丰富的生态组件而受到广泛关注。Spark的特点主要包括:
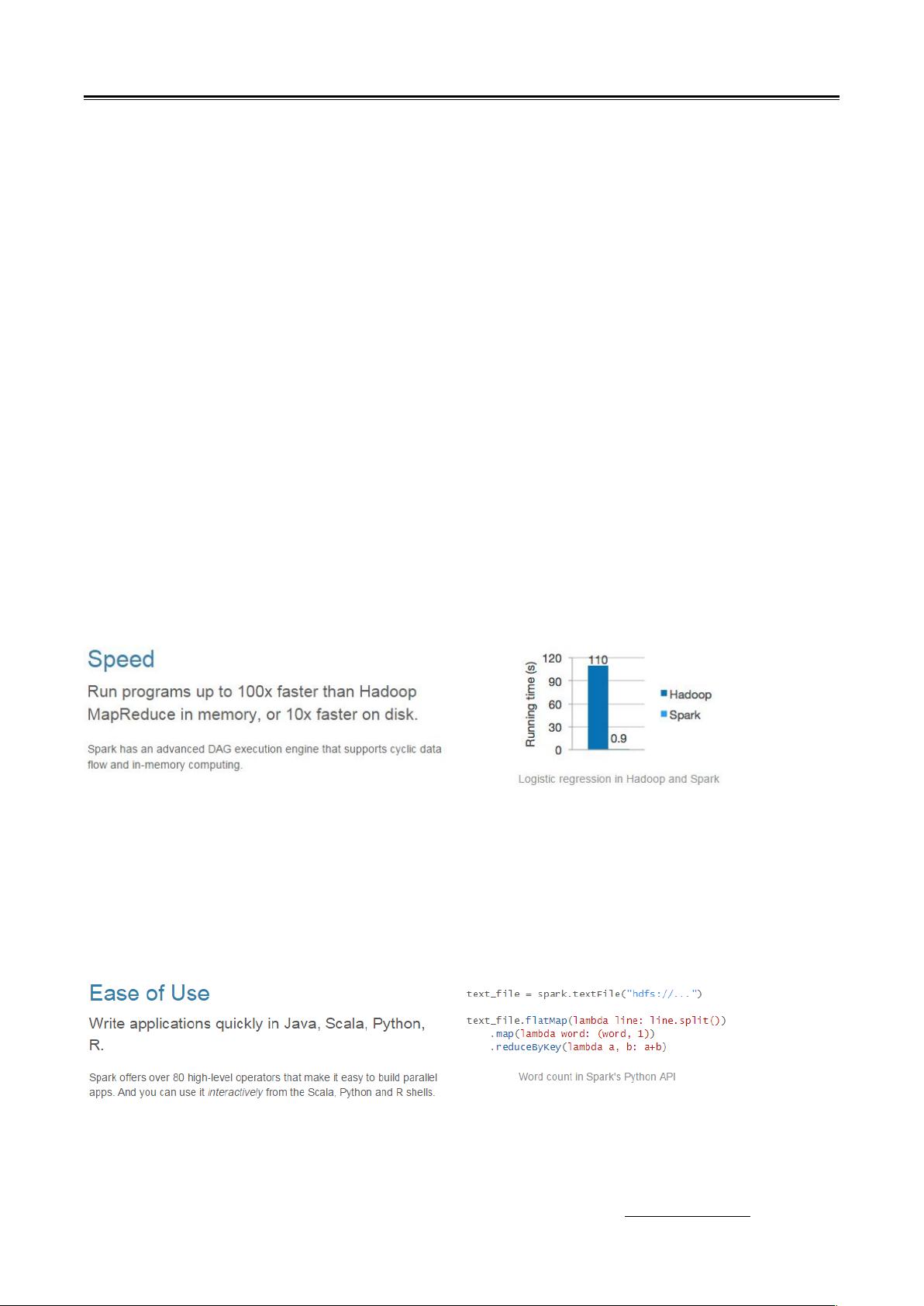
1. **快速**:Spark通过内存计算大幅度提高了数据处理速度,比传统的Hadoop MapReduce快上100倍。
2. **通用性**:Spark不仅支持批处理,还支持实时流处理(Spark Streaming)、图形计算(GraphX)、机器学习(MLlib)和SQL查询(Spark SQL)等多种数据处理任务。
3. **易用性**:Spark提供了一个统一的API,允许开发人员使用Scala、Java、Python和R语言进行编程,同时提供了交互式的SparkShell,便于快速测试和调试。
Spark集群安装部分详细阐述了在两种模式下(Standalone和YARN)的部署步骤:
1. **Standalone模式**:介绍了集群的角色划分,机器准备,安装包下载,以及配置包括Standalone模式下的Spark、JobHistoryServer和高可用性(HA)设置。
2. **YARN模式**:展示了如何在YARN资源管理器上配置和运行Spark作业,使得Spark可以利用Hadoop集群的资源。
执行Spark程序章节详细说明了如何在不同环境下运行Spark程序:
1. **Standalone和YARN模式**:给出了执行第一个Spark程序的步骤,包括如何提交应用程序。
2. **SparkShell**:详述了如何启动SparkShell,并在Shell中编写和运行WordCount示例。
3. **IDEA集成**:演示了如何在IntelliJ IDEA(IDEA)中编写、本地调试和远程调试WordCount程序,这对于开发人员来说非常实用。
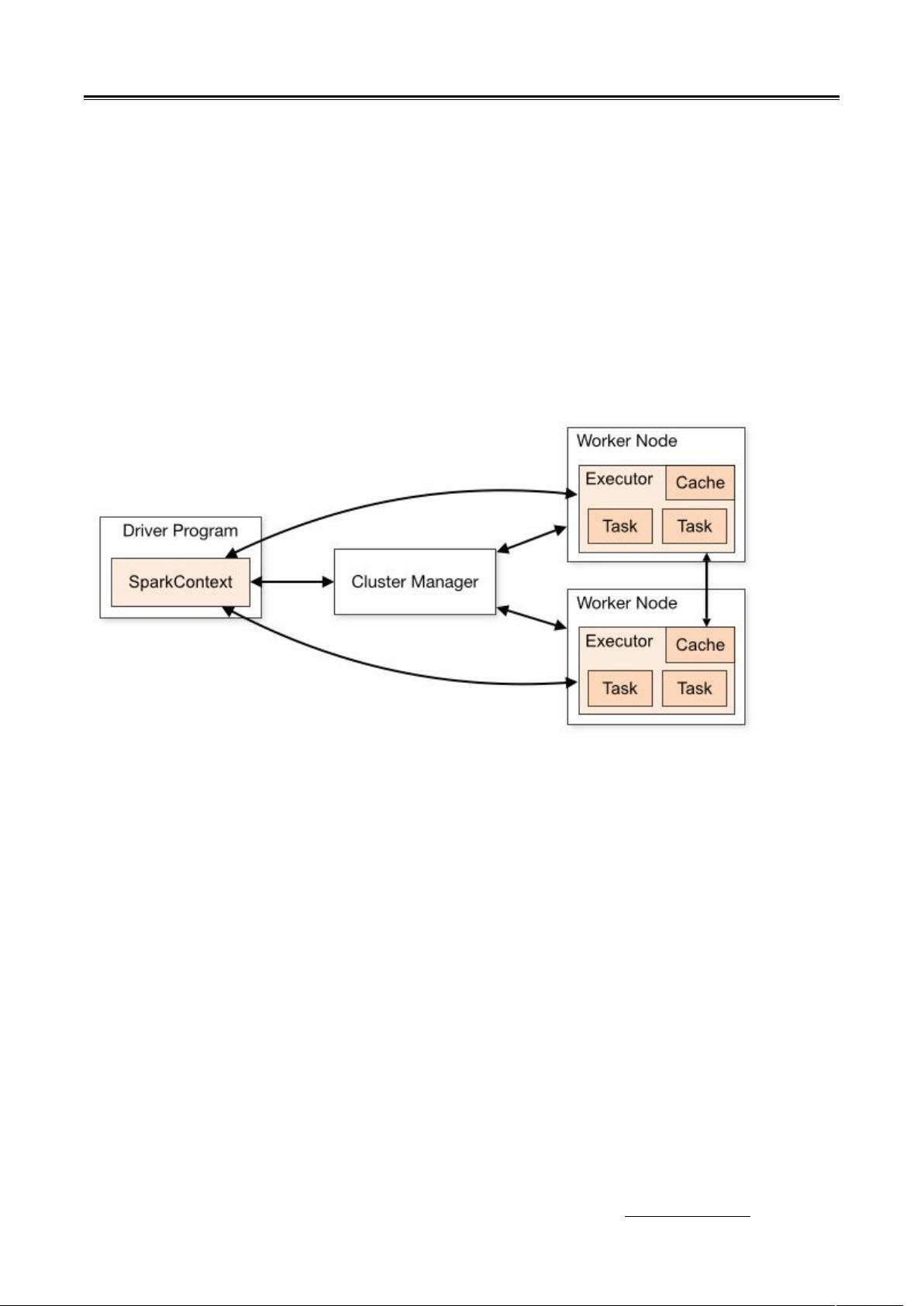
Spark的核心概念包括RDD(弹性分布式数据集)、DataFrame、Dataset以及Spark Job的生命周期,这些都是理解和使用Spark的关键。RDD是Spark的基础数据结构,提供了容错性和并行计算的能力。DataFrame和Dataset是Spark SQL引入的概念,它们提供了更高级的数据操作和优化的查询性能。
这份文档全面覆盖了Spark的基础知识,从理论到实践,对于初学者或希望深入了解Spark的开发者来说,是一份极好的学习资料。通过学习,读者不仅可以了解Spark的基本原理,还能掌握实际部署和编程的技能。
教程
器,叫作独立调度器。
得 到 了 众 多 大 数 据 公 司 的 支 持 , 这 些 公 司 包 括
4+:、;、+&、1&0/、.、#*5&、百度、阿里、腾讯、京东、携程、
优酷土豆。当前百度的 已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里
利用 ,- 构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾
讯 集群达到 <!!! 台的规模,是当前已知的世界上最大的 集群。
1.2.2Spark 特点
快
与 4/ 的 ./0 相比, 基于内存的运算要快 !! 倍以上,基于硬盘的
运算也要快 ! 倍以上。 实现了高效的 , 执行引擎,可以通过基于内存来高效处
理数据流。计算的中间结果是存在于内存中的。
易用
支持 75、#=+ 和 & 的 #,还支持超过 <! 种高级算法,使用户可以
快速构建不同的应用。而且 支持交互式的 #=+ 和 & 的 &&,可以非常方便
地在这些 && 中使用 集群来验证解决问题的方法。
通用
【更多 、、、、大数据 ,可访问尚硅谷(中国)官网 !"下载区】

剩余63页未读,继续阅读
2020-02-13 上传
2020-01-19 上传
2021-08-22 上传
2020-10-10 上传
2020-10-10 上传

javafanwk
- 粉丝: 173
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业分类-设备装置-可移动平台的观测设备.zip
- study:学习
- trivia_db:琐事数据库条目
- SampleNetwork:用于说明数据源与模型之间的链接的示例网络
- commons-wrap:包装好的Apache Commons Maven存储库
- rdiot-p021:适用于Java的AWS IoT核心+ Raspberry Pi +适用于Java的AWS IoT设备SDK [P021]
- 测试工作
- abhayalodge.github.io
- 行业分类-设备装置-可调分辨率映像数据存储方法及使用此方法的多媒体装置.zip
- validates_existence:验证 Rails 模型belongs_to 关联是否存在
- 26-grupe-coming-soon
- aquagem-site
- cpp_examples
- Scavenge:在当地的食品储藏室中搜索所需的食物,进行预订,并随时了解最新信息! 对于食品储藏室管理员,您可以在此处管理食品储藏室信息和库存
- Hels-Ex7
- 行业分类-设备装置-可调式踏板.zip
