基于神经网络与混沌理论的独立发声式语音识别研究
版权申诉
81 浏览量
更新于2024-06-23
收藏 618KB DOC 举报
本文主要探讨了机器人语音识别算法的改进和外文翻译,重点关注在非线性系统理论背景下对传统语音识别方法的革新。语音识别作为一项关键技术,近年来因其理论价值和实用性日益受到重视。以往的研究主要依赖于线性系统理论,如隐马尔可夫模型和动态时间规整,但随着对语音信号复杂性的深入理解,非线性系统理论,如人工神经网络、混沌理论和分形理论,逐渐成为突破的关键。
首先,文章介绍了两种类型的语音识别:独立发声式和非独立发声式。独立发声式通过多个人的训练样本,适用于识别多个个体的指令,而无需用户操作训练,应用范围更广。为了提高独立发声式系统的性能,关键在于从语音信号中有效地提取特征,这是一个基础问题。通常,语音信号通过隐马尔可夫模型表示为时间序列,并通过特征提取转化为特征向量,用于训练模型参数估计。
线性预测倒谱系数(LPCC)和梅尔频率倒谱系数(MFCC)是常见的特征提取方法,它们基于声道共振的线性模型。然而,这些方法难以捕捉语音中的非线性信息,因此引入了分形维数等非线性分析工具,用于测量语音信号的复杂度。本文采用传统的LPCC方法结合非线性多尺度分形维数进行特征提取,旨在提升语音识别系统的准确性和鲁棒性。
语音识别系统的工作流程包括训练和识别两个阶段,通过模式化的方法,如HMM(隐马尔可夫模型),将语音信号转化为可识别的特征,并优化模型参数。输入信号经过处理后,能够准确地识别成特定的词,其识别精度是衡量系统性能的重要指标。图1展示了语音识别系统的模块图,直观地展示了整个识别过程。
本文的创新之处在于将非线性系统理论应用于语音识别,尤其是通过引入分形维数这一工具,可能有助于解决语音信号的复杂性问题,从而提高机器人语音识别的效率和准确性。这种研究对于推动智能机器人技术的发展具有重要意义,使得机器人能够更好地理解和响应人类的语音指令。
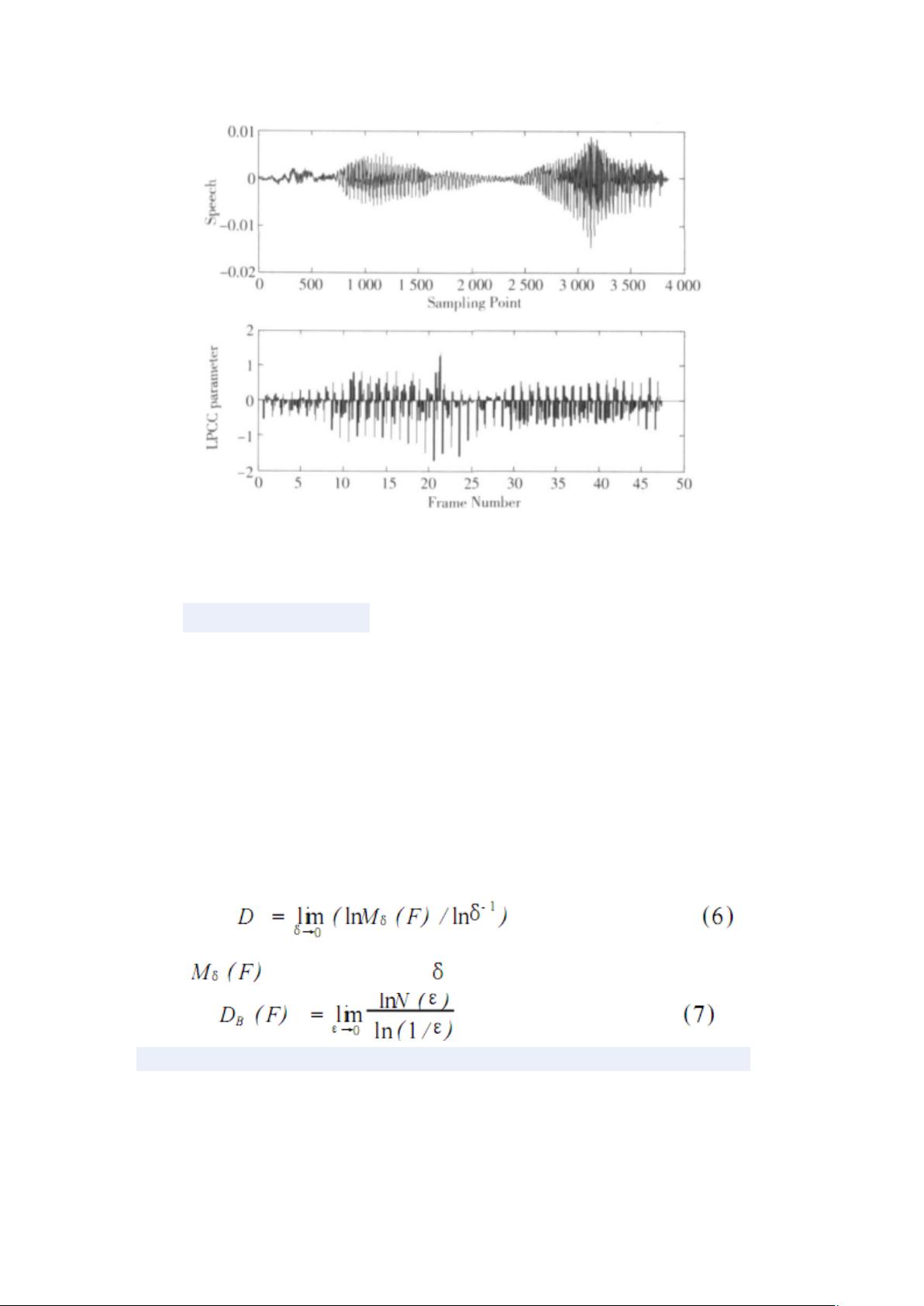
图 3 断点检测后的中文命令字“前进”语音波形和 LPCC 的参数波形
3.2 语音分形维数计算
分形维数是一个与分形的规模与数量相关的定值,也是对自我的结构相似性
的测量。分形分维测量是[6-7]。从测量的角度来看,分形维数从整数扩展到了分
数,打破了一般集拓扑学方面被整数分形维数的限制,分数大多是在欧几里得几何
尺寸的延伸。
有许多关于分形维数的定义,例如相似维度,豪斯多夫维度,信息维度,相关
维度,容积维度,计盒维度等等,其中,豪斯多夫维度是最古老同时也是最重要的,
它的定义如【3】所示:
其中, 表示需要多少个单位 来覆盖子集 F.
端点检测后,中文命令词“向前”的语音波形和分形维数波形如图 4 所示。
剩余18页未读,继续阅读
2023-07-12 上传
2023-07-13 上传
2023-07-12 上传
2023-07-12 上传
2023-07-12 上传

omyligaga
- 粉丝: 97
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- vb语言程序设计教程.zip
- sjasmplus:SJAsmPlus
- A06:作业6
- GnomeNibus-开源
- message-franking-tester:实施不同的邮件盖章方案和性能分析测试仪
- 机器学习python标记工具-Labelimg2024
- React-Portfolio:我的一小部分作品,用React重写
- MM32SPIN0x(s) 库函数和例程.rar
- goApi
- cuetools-开源
- Veni-Vidi-Voravi
- website:Terre Tropicale公共网站
- Main:基于struts2库存管理系统Android端
- Another-React-Lib:只是另一个充满可重用组件的React库
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- 原型
