

计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term
weight),因而在计算文档之间的相关性中将发挥更大的作用。
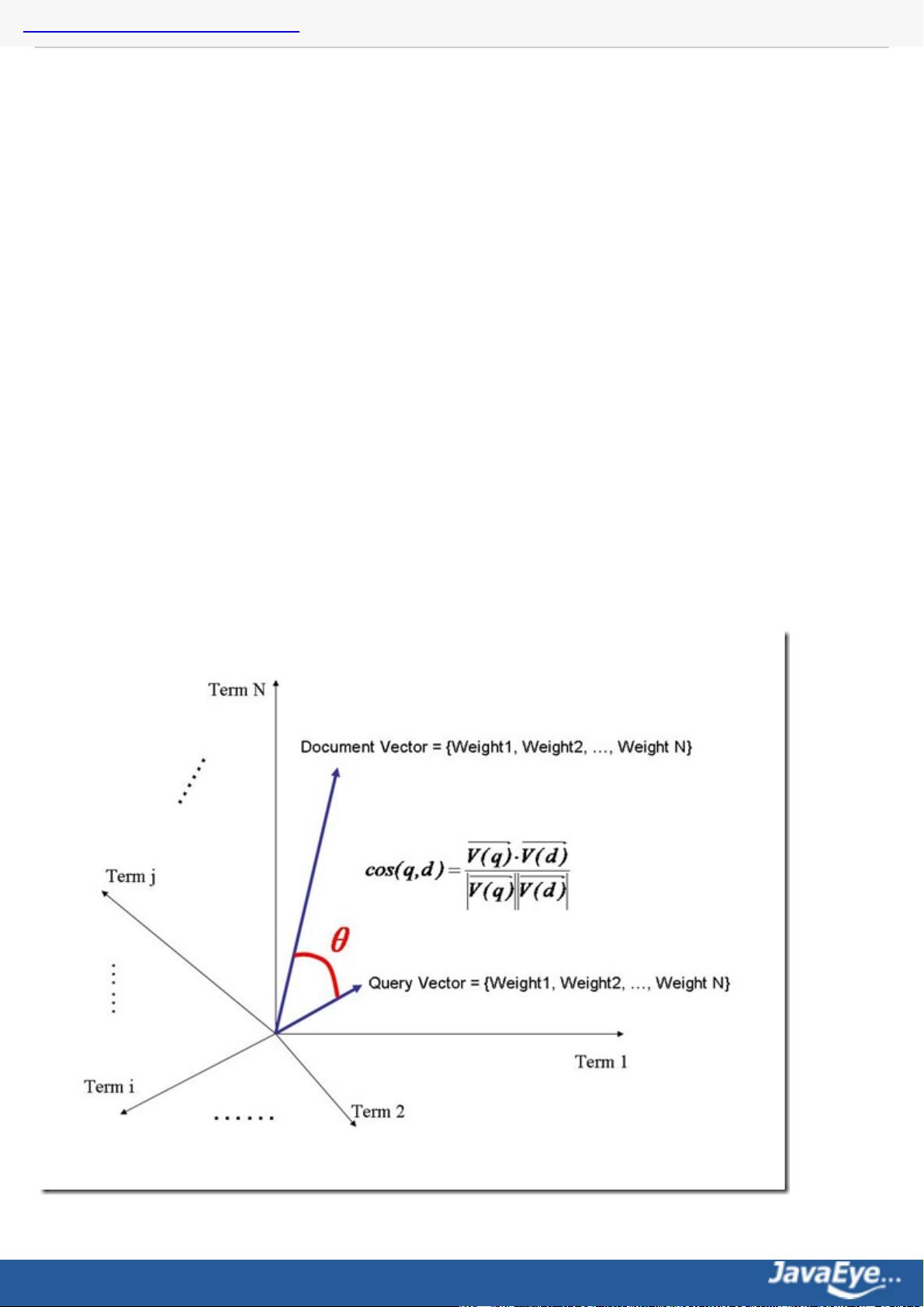
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space
Model)。
下面仔细分析一下这两个过程:
1. 计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
• Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
• Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本
文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,
就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明
此词(Term)太普通,不足以区分这些文档,因而重要性越低。
这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越
多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df
小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
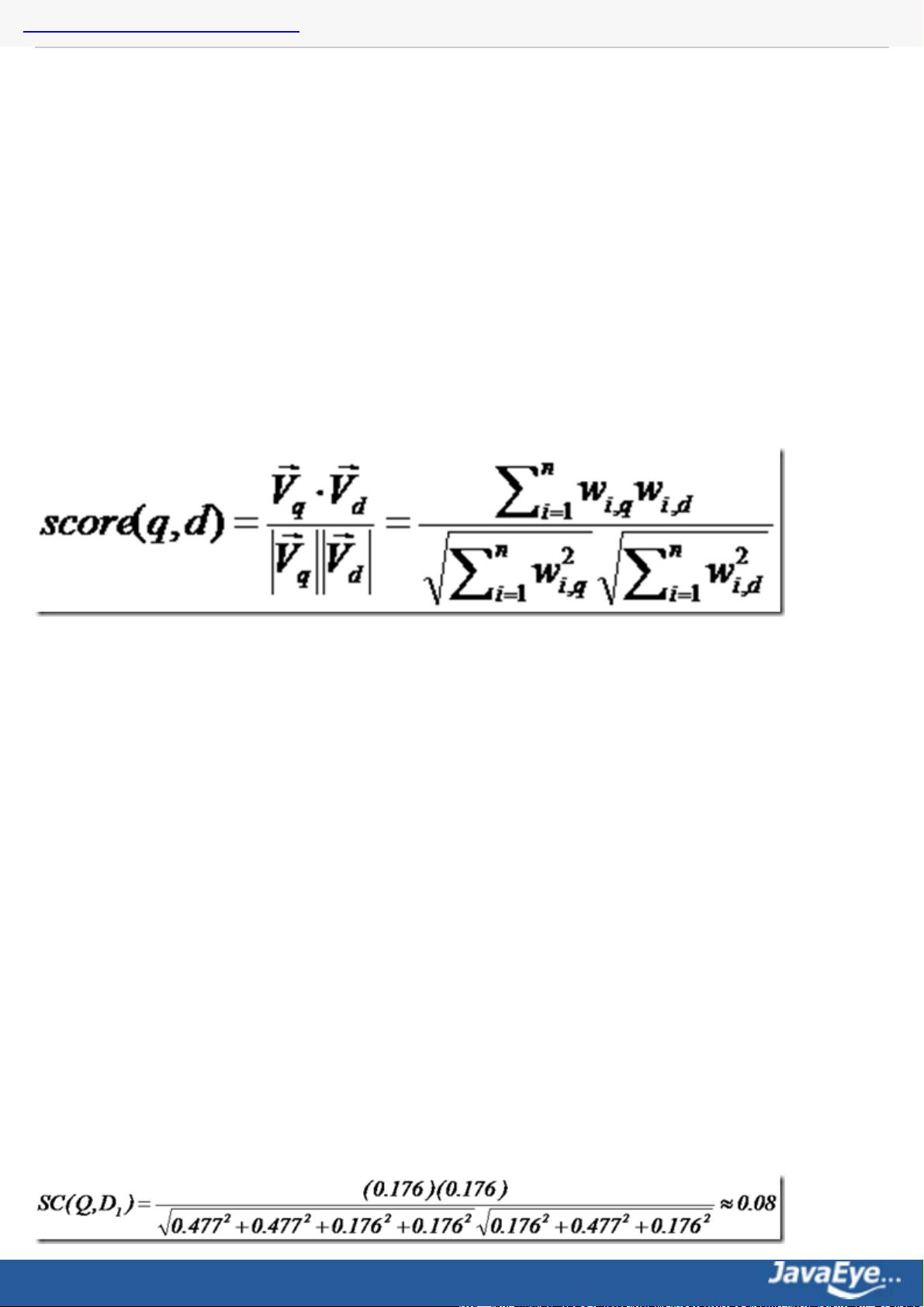
道理明白了,我们来看看公式:
这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有
不同。
http://forfuture1978.javaeye.com
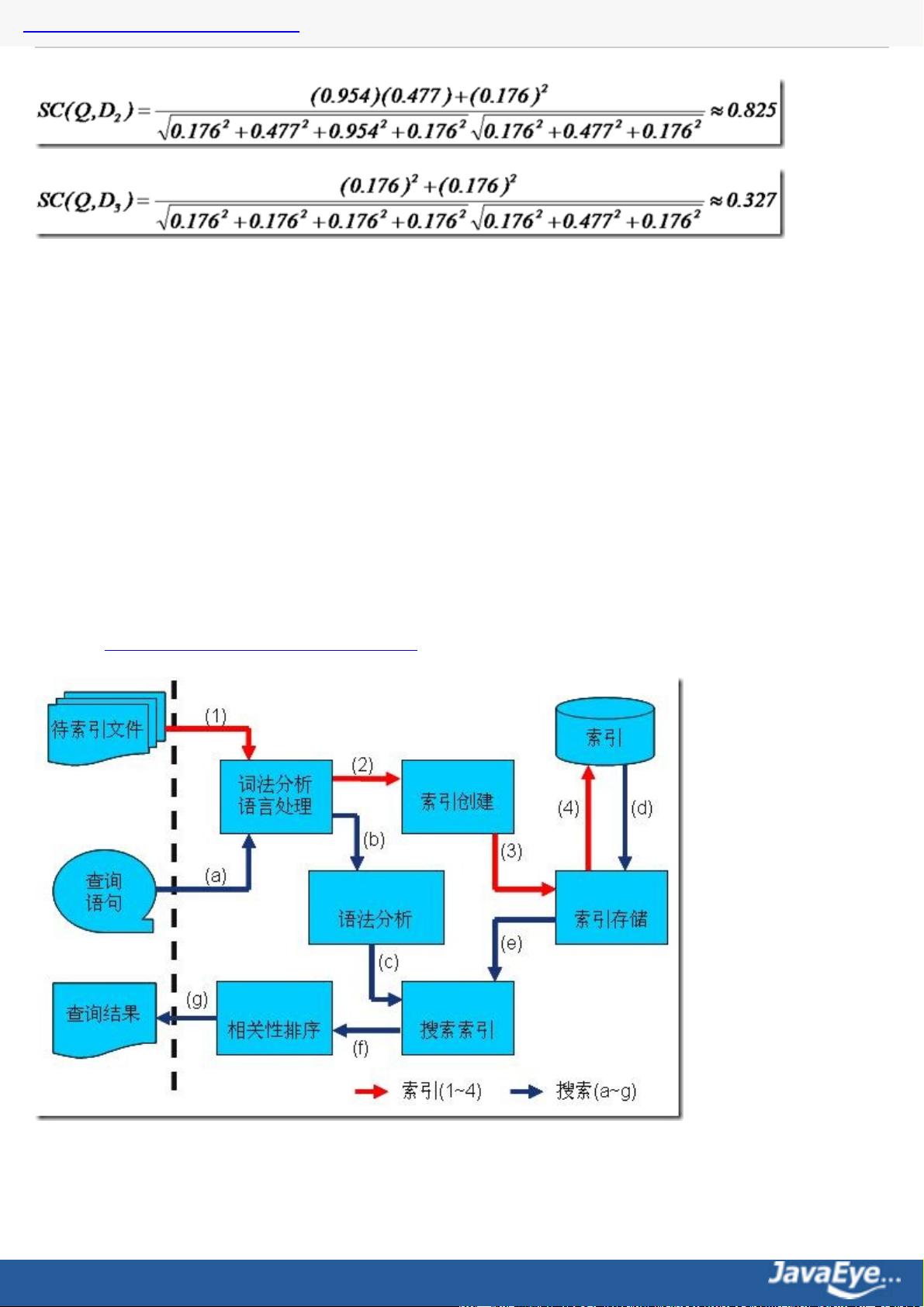
1.1 Lucene学习总结之一:全文检索的基本原理
第 16 / 199 页

剩余198页未读,继续阅读

love0852
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


