"小白实践Hadoop伪分布式安装:Linux环境配置与步骤指南"
需积分: 11 149 浏览量
更新于2024-01-21
收藏 4.76MB DOCX 举报
Hadoop是一个开源的分布式计算框架,被广泛用于大规模数据集的存储和处理。本文将介绍Hadoop的伪分布式安装过程,并提供一些步骤和心得供小白参考。
第一部分是Linux的安装。为了搭建Hadoop的伪分布式环境,首先需要在一台计算机上安装Linux操作系统。Linux是一种常用的开源操作系统,具有稳定、安全和高效的特点。在安装过程中,需要注意选择适合你设备的Linux发行版,并按照安装向导的步骤进行操作。安装好Linux系统后,可以进入下一步的配置。
第二部分是Linux的配置。在Linux系统中,需要进行一些配置以便顺利安装和运行Hadoop。首先是创建新用户。为了安全起见,不建议使用root用户直接搭建Hadoop环境。可以通过以下命令创建一个新用户,并为其设置密码和权限:
```shell
$ sudo adduser hadoop
```
接下来是软件源的更换以及更新。在安装Linux系统后,系统会自动配置好默认的软件源,但由于网络原因或者其他因素,可能需要更换为国内的软件源。可以通过编辑 `/etc/apt/sources.list` 文件来更换软件源。在更换完成后,可以使用以下命令更新软件包列表:
```shell
$ sudo apt-get update
```
第三部分是Hadoop的安装。在完成Linux的配置后,可以开始安装Hadoop。Hadoop的安装过程相对复杂,需要下载Hadoop的安装包,并解压到指定的目录。在安装过程中,需要注意Hadoop的版本和兼容性。可以从Hadoop官方网站上下载最新版本的安装包,并按照官方文档中的指导进行安装。
安装完成后,需要进行一些配置以使Hadoop能够正常运行。首先是修改Hadoop的配置文件。Hadoop的配置文件位于Hadoop安装目录下的`/etc/hadoop`文件夹中。可以使用编辑器打开配置文件,按照官方文档中的指导修改配置参数。主要需要注意的是配置Hadoop的核心参数、HDFS参数和YARN参数。
接下来是格式化HDFS。在Hadoop中,HDFS是用于存储和管理数据的文件系统。在使用HDFS之前,需要对其进行格式化,以创建初始化的目录结构和配置信息。可以使用以下命令对HDFS进行格式化:
```shell
$ hdfs namenode -format
```
最后是启动Hadoop集群。在完成以上配置后,可以使用以下命令启动Hadoop集群:
```shell
$ start-dfs.sh
$ start-yarn.sh
```
启动成功后,可以通过Web界面访问Hadoop管理界面,查看集群的运行状态和任务执行情况。
在进行Hadoop的伪分布式安装过程中,可能会遇到一些问题和挑战。对于小白来说,可以参考以下一些建议来解决问题。
首先是查看错误日志。在配置和启动Hadoop的过程中,如果遇到错误,可以查看Hadoop的日志文件,如`hadoop-hadoop-namenode-<hostname>.log`和`hadoop-hadoop-datanode-<hostname>.log`。这些日志文件通常位于Hadoop安装目录下的`/logs`文件夹中。
其次是检查网络配置。由于Hadoop是一个分布式计算框架,其正常运行需要网络的支持。在进行伪分布式安装时,需要保证网络配置的正确性,如IP地址、主机名和端口等。可以使用`ifconfig`命令查看网络接口配置,在修改配置文件前,可以先备份原配置文件。
此外,还可以参考Hadoop官方文档和社区论坛等资源。Hadoop拥有庞大的用户社区和活跃的开发团队,可以在官方文档中找到详尽的安装和配置指南,也可以在社区论坛上提问和分享经验。通过学习和借鉴他人的经验,可以更好地解决问题和优化Hadoop的安装和配置。
总之,Hadoop的伪分布式安装是一个相对复杂的过程,需要进行一系列的配置和调试。本文提供了一些步骤和心得供小白参考,希望能够帮助到他们顺利地搭建Hadoop的伪分布式环境,并为后续的数据分析和处理工作打下基础。同时,也希望小白们能够继续扩展自己的知识和技能,深入学习和理解分布式计算的原理和应用。
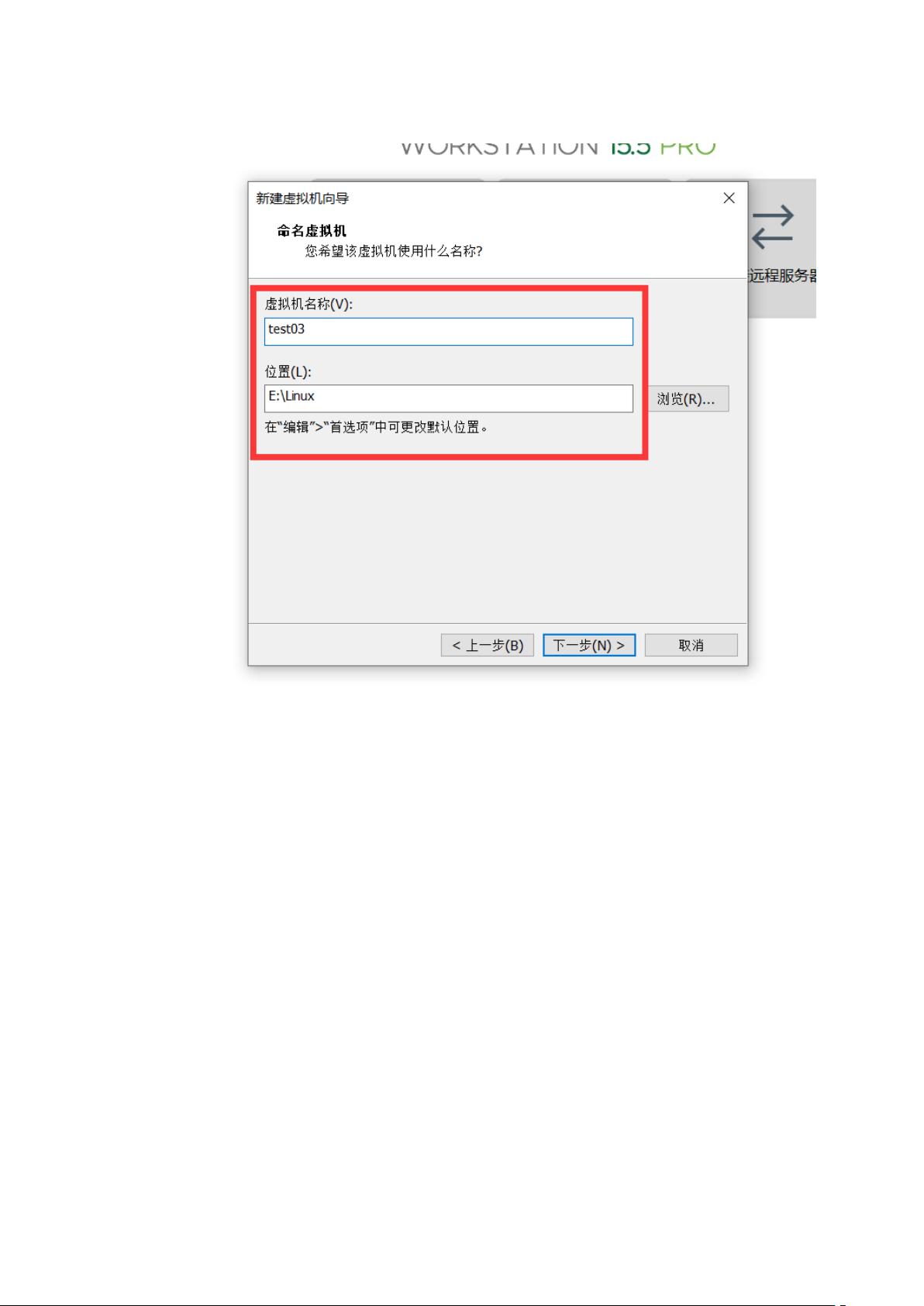
虚拟机名称也是看自己取就行,位置也是看个人喜好,尽量选大一点空间
剩余22页未读,继续阅读
2024-06-24 上传
点击了解资源详情
2024-09-06 上传

渔舟唱晚hr
- 粉丝: 3
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
