Cachecloud自动化运维:Redis-Cluster故障与数据迁移实战
需积分: 9 27 浏览量
更新于2024-07-18
收藏 2.07MB DOCX 举报
本文主要探讨了Cachecloud自动化运维中的Redis Cluster应用运维,涵盖了节点上下线、故障迁移和数据迁移的关键步骤。在Cachecloud平台中,应用运维对于保持服务的高可用性和稳定性至关重要。以下是对这些主题的详细说明:
一、应用实例管理
1-节点运维
在Redis Cluster中,节点分为master和slave节点。对节点的操作直接影响到集群的正常运行。
(1)master节点
- 下线实例:下线主节点会导致槽位(slots)丢失,进而使集群不可用。但是,集群内部会自动进行故障迁移,选择一个从节点晋升为主节点,从而恢复服务。
- 添加slave:可以通过添加新的从节点来增加冗余,提高主节点的容错性。添加后,新从节点将与主节点建立复制关系。
(2)slave节点
- 下线实例:从节点的下线会影响主节点的复制,但不会导致服务中断。集群会在从节点恢复在线后自动重新建立复制关系。
2-故障转移
Redis Cluster提供了手动故障转移的三种方案:Manual、Force和Takeover。这些操作需谨慎使用,因为它们可能短暂阻塞客户端请求,并消耗大量CPU和网络资源。
- Manual:适用于计划内的主节点迁移,例如将节点从旧机器迁移到新机器。它确保在选举新主节点之前,主从节点的数据同步完成。
- Force:用于主节点宕机且无法自动恢复的情况。在这种模式下,从节点将立即发起选举,可能导致部分数据丢失。
- Takeover:未在提供的内容中详细介绍,通常可能是自动故障转移的过程。
二、数据迁移
在Cachecloud中,数据迁移通常伴随着节点的上下线或故障转移。例如,当主节点下线时,其槽位会分配给新的主节点,实现数据的无缝过渡。添加或删除从节点也可能涉及数据的重新分布。
总结:
Cachecloud的自动化运维强调了高效、安全地管理Redis Cluster的重要性。通过正确处理节点的上下线、故障迁移和数据迁移,可以确保服务的稳定性和数据的一致性。在实际操作中,应遵循最佳实践,避免不必要的数据丢失和服务中断,同时充分利用Cachecloud提供的自动化工具来简化运维流程。
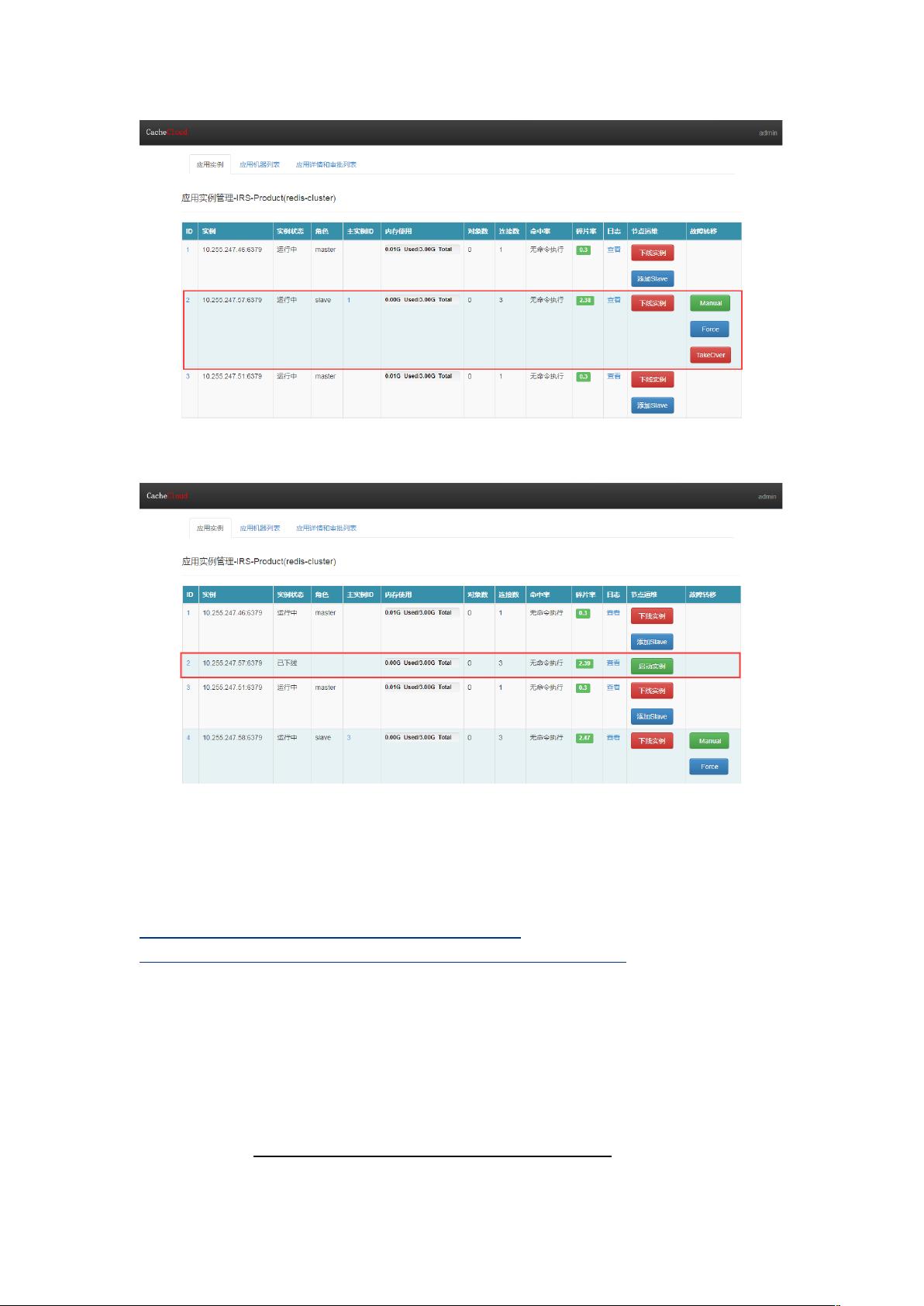
_从节点下线后_
2-故障转移
网上介绍:Manual / Force / TakeOver 的区别
https://my.oschina.net/zhiyonghe/blog/994741
http://wiki.jikexueyuan.com/project/redis/cluster-down.html
(1)手动故障转移 3 种方案介绍:Manual / Force / Takeover
··
注:默认情况下转移期间客户端请求会有短暂的阻塞;
当节点包含大量数据时会严重消耗
CPU
和网络资源,线上不要频繁操作;
<1>Manual
适用场景:主节点迁移,如节点所在的老机器迁移到新机器等
迁移流程:
剩余22页未读,继续阅读
2018-04-28 上传
2016-11-11 上传
2021-05-14 上传
2021-04-12 上传
2021-01-27 上传
2021-06-17 上传

ccall248
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
