正则化技术:L1、L2 regularization与防止过拟合策略
需积分: 0 52 浏览量
更新于2024-08-05
收藏 1.03MB PDF 举报
"正则化方法,包括L1和L2 Regularization,数据集扩增以及Dropout,是机器学习和深度学习中防止过拟合、提升模型泛化能力的关键技术。本文摘自《Neural Networks and Deep Learning》的概览,主要探讨了这些正则化策略,并强调了训练数据划分的重要性,即训练数据、验证数据和测试数据的区分。"
在机器学习和深度学习领域,过拟合是模型性能下降的一个常见问题,特别是在训练数据有限或模型过于复杂的情况下。过拟合发生时,模型过度学习训练数据中的噪声和特异性,导致对未见过的数据预测效果不佳。为了解决这一问题,一系列正则化技术被提出,它们的目标是限制模型的复杂性,防止过拟合,从而提高模型的泛化能力。
1. **L1 Regularization**:也称为Lasso正则化,它通过在损失函数中添加权重向量的绝对值之和作为惩罚项。L1正则化倾向于产生稀疏的权重矩阵,即许多权重参数会被压缩至零,这有助于特征选择,可以理解为一种自动的特征剔除过程。
2. **L2 Regularization**:也称为Ridge正则化,它在损失函数中添加权重向量的平方和作为惩罚项。L2正则化不会导致权重参数变为零,而是减小所有权重的大小,使得模型更加平滑,防止模型过于复杂。
3. **数据集扩增(Data Augmentation)**:这种方法通过在原始训练数据上应用各种变换,如旋转、缩放、翻转等,人为地增加数据集的大小,使模型在更广泛的数据变化上进行学习,从而提高其泛化能力。
4. **Dropout**:这是一种在训练神经网络时随机“关闭”一部分神经元的策略。每个训练迭代中,某些神经元会有一定的概率被暂时移除,迫使其他神经元学习更多的信息,减少对特定神经元的依赖,从而降低过拟合的风险。
在训练过程中,通常将数据集分为训练集、验证集和测试集。训练集用于更新模型参数,验证集用于调整超参数(如学习率、早停的epoch数等),以防止过拟合。而测试集则在模型最终确定后用于评估模型的泛化性能,不应在训练过程中使用,以保持其独立性和真实性。
通过这些正则化方法,我们可以有效地控制模型的复杂性,平衡模型的训练误差与验证误差,以达到提高模型在未知数据上的表现。在实际应用中,选择哪种正则化方式取决于具体任务和数据集的特性,可能需要通过实验比较来确定最佳策略。
2018/10/11 正则化方法:L1和L2 regularization、数据集扩增、dropout - yxwkaifa - 博客园
https://www.cnblogs.com/yxwkf/p/5268577.html 1/5
博客园 首页 新随笔 联系 订阅 管理
正则化方法:L1和L2 regularization、数据集扩增、dropout
本文是《Neural networks and deep learning》概览 中第三章的一部分。讲机器学习/深度学习算法中经常使用的正则化方法。(本
文会不断补充)
正则化方法:防止过拟合,提高泛化能力
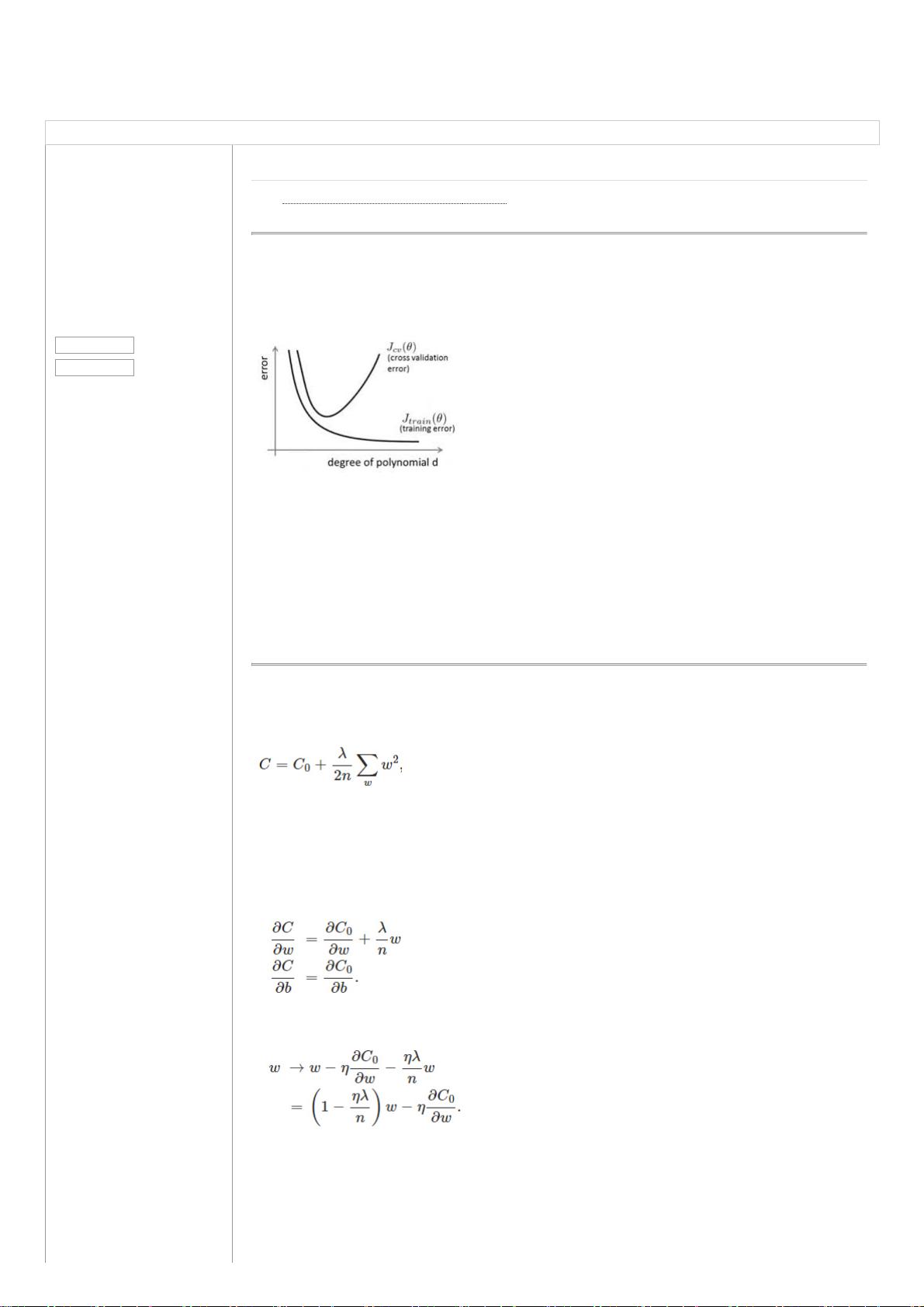
在训练数据不够多时,或者overtraining时,经常会导致overfitting(过拟合)。其直观的表现例如以下图所看到的。随着训练过程的
进行,模型复杂度添加,在training data上的error渐渐减小。可是在验证集上的error却反而渐渐增大——由于训练出来的网络过拟合
了训练集,对训练集外的数据却不work。
为了防止overfitting。能够用的方法有非常多,下文就将以此展开。有一个概念须要先说明,在机器学习算法中,我们经常将原始数据
集分为三部分:training data、validation data。testing data。这个validation data是什么?它事实上就是用来避免过拟合的。在
训练过程中。我们通经常使用它来确定一些超參数(比方依据validation data上的accuracy来确定early stopping的epoch大小、依
据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?由于假设在testing data做这些,那么随着
训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有不论什么參
考意义。因此,training data的作用是计算梯度更新权重,validation data如上所述。testing data则给出一个accuracy以推断网络
的好坏。
避免过拟合的方法有非常多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包含L1、L2(L2
regularization也叫weight decay),dropout。
L2 regularization(权重衰减)
L2正则化就是在代价函数后面再加上一个正则化项:
C0代表原始的代价函数,后面那一项就是L2正则化项。它是这样来的:全部參数w的平方的和,除以训练集的样本大小n。
λ就是正则项系数,权衡正则项与C0项的比重。另外另一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求
导会产生一个2。与1/2相乘刚好凑整。
L2正则化项是怎么避免overfitting的呢?我们推导一下看看,先求导:
能够发现L2正则化项对b的更新没有影响,可是对于w的更新有影响:
在不使用L2正则化时。求导结果中w前系数为1,如今w前面系数为 1−ηλ/n ,由于η、λ、n都是正的。所以 1−ηλ/n小于1,它的效
果是减小w。这也就是权重衰减(weight decay)的由来。
当然考虑到后面的导数项,w终于的值可能增大也可能减小。
另外。须要提一下,对于基于mini-batch的随机梯度下降,w和b更新的公式跟上面给出的有点不同:
< 2018年10月 >
日 一 二 三 四 五 六
30 1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31 1 2 3
4 5 6 7 8 9 10
搜索
找找看
谷歌搜索
常用链接
我的随笔
我的评论
我的参与
最新评论
我的标签
友情链接
i云保app使用介绍
国民重疾险上市——复星联合康乐e
生
买“尊享e生”之前,一定要搞明白这
个问题
最新评论
1. Re:嵌入式系统开发步骤
书面上的东西是很重要但是我感觉对
于一大部分朋友来说还是不够直
观,因此找到一些不错的视频资料
简单易懂一些
--华清粉丝1号
2. Re:Mozilla5.0的含义
笑尿
--Pale Life
3. Re:做高通平台安卓驱动感言
刚开始做高通 顶起
--duantao7584567
4. Re:.net web 开发平台- 表单设
计器 一(web版)
老大 能不能发一份源码给我 谢谢
351597500@qq.com
--王涌军
5. Re:Basic脚本解释器移植到
STM32
可以考虑移植我的一个项目 MY-
BASIC。
--扑来树袋熊
yxwkaifa
知识改变命运
下载后可阅读完整内容,剩余4页未读,立即下载
2022-07-14 上传
2021-09-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-15 上传
2021-05-24 上传
2021-06-01 上传
点击了解资源详情

天眼妹
- 粉丝: 29
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
