"大数据处理技术Spark-SQL:厦门大学计算机系课程PPT总结"
需积分: 0 142 浏览量
更新于2023-12-26
收藏 1.23MB PDF 举报
本章节介绍了大数据处理技术Spark中的Spark SQL。Spark SQL是一种用于处理结构化数据的模块,它提供了用于处理结构化数据的高级API,并将结构化数据与分布式数据处理引擎Spark相结合,使用户能够使用SQL语句来查询和分析大规模数据集。本课程由厦门大学计算机科学系林子雨教授授课,旨在帮助研究生了解和掌握大数据处理技术Spark中的Spark SQL。
在本章节中,我们首先介绍了Spark SQL的概述和特点。Spark SQL支持多种数据源,包括Parquet、JDBC、Avro等,能够对多种格式的数据进行处理和分析。同时,Spark SQL的优化器能够对查询进行优化,提高查询效率。此外,Spark SQL还与Hive整合,可以直接访问Hive存储和执行Hive的查询语句。通过对Spark SQL的特点和优势的介绍,我们让学生们了解了Spark SQL的重要性和适用场景。
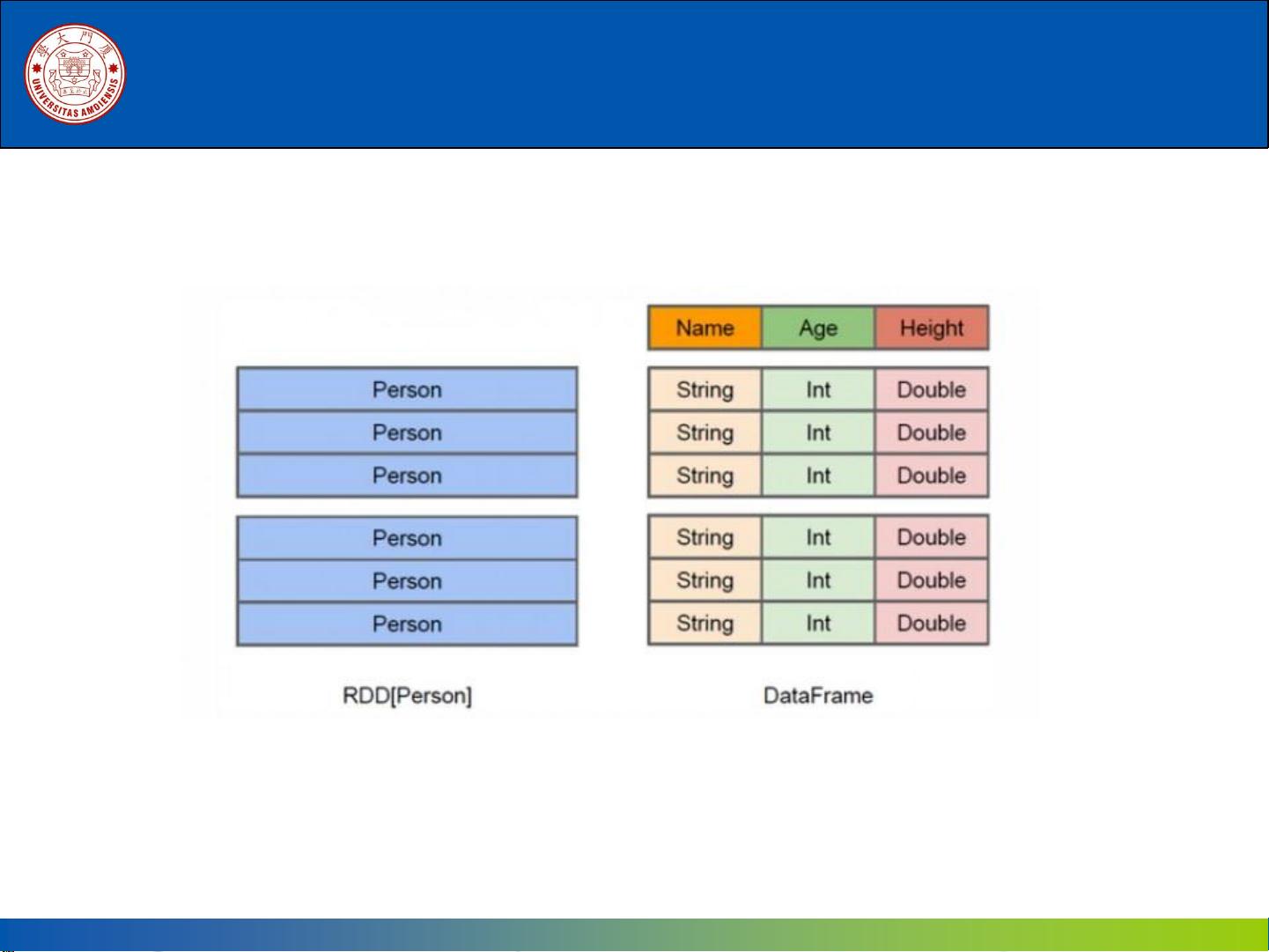
接着,我们详细讲解了Spark SQL的基本概念和架构。我们介绍了DataFrame和DataSet这两种分布式数据集的概念,并介绍了它们与传统RDD的关系和区别。我们还讲解了Spark SQL的逻辑架构和执行架构,通过图文并茂的讲解,学生们能够更直观地理解Spark SQL的内部原理和工作机制。
随后,我们深入探讨了Spark SQL的应用和实践。我们介绍了如何在Spark中使用Spark SQL进行数据分析和处理,并通过示例代码演示了Spark SQL的基本用法和常见操作。我们还介绍了Spark SQL与数据可视化工具的整合,以及与Hive、HBase等其他大数据组件的集成。通过实际操作和案例分析,学生们能够更深入地理解Spark SQL的实际应用和潜在的挑战。
最后,我们着重讲解了Spark SQL的性能调优和最佳实践。我们介绍了如何通过合理的数据分区和缓存策略来提高Spark SQL的性能,以及如何通过合理的SQL查询语句和索引设计来提高查询效率。我们还介绍了一些常见的性能优化技巧和注意事项,帮助学生们在实际应用中避免常见的性能陷阱。
通过本章节的学习,学生们不仅能够了解和掌握Spark SQL的基本概念和技术特点,还能够通过实际操作和案例分析,掌握Spark SQL的应用和性能调优技巧。这将有助于他们更好地应用Spark SQL来处理和分析大规模数据,为企业和组织提供更加高效和可靠的数据处理解决方案。



1048 浏览量
124 浏览量
点击了解资源详情
2022-08-03 上传
135 浏览量
295 浏览量
136 浏览量
2021-03-25 上传
2022-11-13 上传

山林公子
- 粉丝: 32
 我的内容管理
展开
我的内容管理
展开







最新资源
- HTC G22刷机教程:掌握底包刷入及第三方ROM安装
- JAVA天天动听1.4版:证书加持的移动音乐播放器
- 掌握Swift开发:实现Keynote魔术移动动画效果
- VB+ACCESS音像管理系统源代码及系统操作教程
- Android Nanodegree项目6:Sunshine-Wear应用开发
- Gson解析json与网络图片加载实践教程
- 虚拟机清理神器vmclean软件:解决安装失败难题
- React打造MyHome-Web:公寓管理Web应用
- LVD 2006/95/EC指令及其应用指南解析
- PHP+MYSQL技术构建的完整门户网站源码
- 轻松编程:12864液晶取模工具使用指南
- 南邮离散数学实验源码分享与学习心得
- qq空间触屏版网站模板:跨平台技术项目源码大全
- Twitter-Contest-Bot:自动化参加推文竞赛的Java机器人
- 快速上手SpringBoot后端开发环境搭建指南
- C#项目中生成Font Awesome Unicode的代码仓库
