Hadoop集群部署详解:4节点安装与配置
需积分: 9 19 浏览量
更新于2024-07-23
收藏 1.26MB PDF 举报
Hadoop安装配置教程深入解析了Apache软件基金会开发的开源分布式计算平台Hadoop的部署和配置。Hadoop主要由两个核心组件组成:Hadoop分布式文件系统(HDFS)和MapReduce。HDFS负责提供分布式存储和文件系统服务,NameNode作为主服务器管理命名空间和客户端访问,而DataNode则负责数据的存储。另一方面,MapReduce框架通过JobTracker和TaskTracker实现分布式计算,前者作为调度器监控任务执行,后者在各个从节点上执行分配的任务。
在这个教程中,我们关注的是一个包含1个Master节点和3个Slave节点的Hadoop集群环境。这些节点都通过局域网相连,确保彼此可以互相通信。为了成功安装和配置,网络连通性和节点间的可达性是关键,这一点在早期的Hadoop集群设置中尤为重要。
集群配置的具体步骤可能包括以下环节:
1. **软件准备**:下载Hadoop的最新版本,根据操作系统(如Linux或Windows)安装Hadoop和相关依赖库。
2. **环境配置**:设置JAVA_HOME环境变量,配置Hadoop配置文件(core-site.xml, hdfs-site.xml, mapred-site.xml),定义NameNode和DataNode的地址,以及JobTracker和TaskTracker的地址。
3. **Master节点设置**:在Master节点上启动NameNode和JobTracker服务,通常是通过运行`start-dfs.sh`和`start-yarn.sh`命令。
4. **Slave节点配置**:在Slave节点上配置DataNode和TaskTracker,运行`hadoop-daemon.sh`启动服务。
5. **验证与测试**:通过命令行工具(如`hadoop fs -ls`)检查HDFS是否正常工作,通过提交简单MapReduce任务验证MapReduce的运行。
此外,集群规模和性能可以通过调整参数如块大小、副本数等来优化。Hadoop的设计目标是容错性和高可用性,所以在配置过程中要注意备份和故障恢复机制。
整个Hadoop安装配置过程需要仔细阅读官方文档,遵循最佳实践,并在实际环境中逐步调试,确保每个组件都能协同工作。由于篇幅限制,这里并未详述具体的命令行步骤,但读者可以通过参考相关教程、文档或者在线资源来完成这些操作。

创建时间:2012/2/26 修改时间:2012/3/17 修改次数:1
2、SSH无密码验证配置
Hadoop 运行过程中需要管理远端 Hadoop 守护进程,在 Hadoop 启动以后,NameNode
是通过 SSH(Secure Shell)来启动和停止各个 DataNode 上的各种守护进程的。这就必须在
点之间执行指令的时候是不需要输入密码的形式,故我们需要配置 SSH 运用无密码公钥
登录并启动 DataName 进程,同样原理,
ataNode 上也能使用 SSH 无密码登录到 NameNode。
节
认证的形式,这样 NameNode 使用 SSH 无密码
D
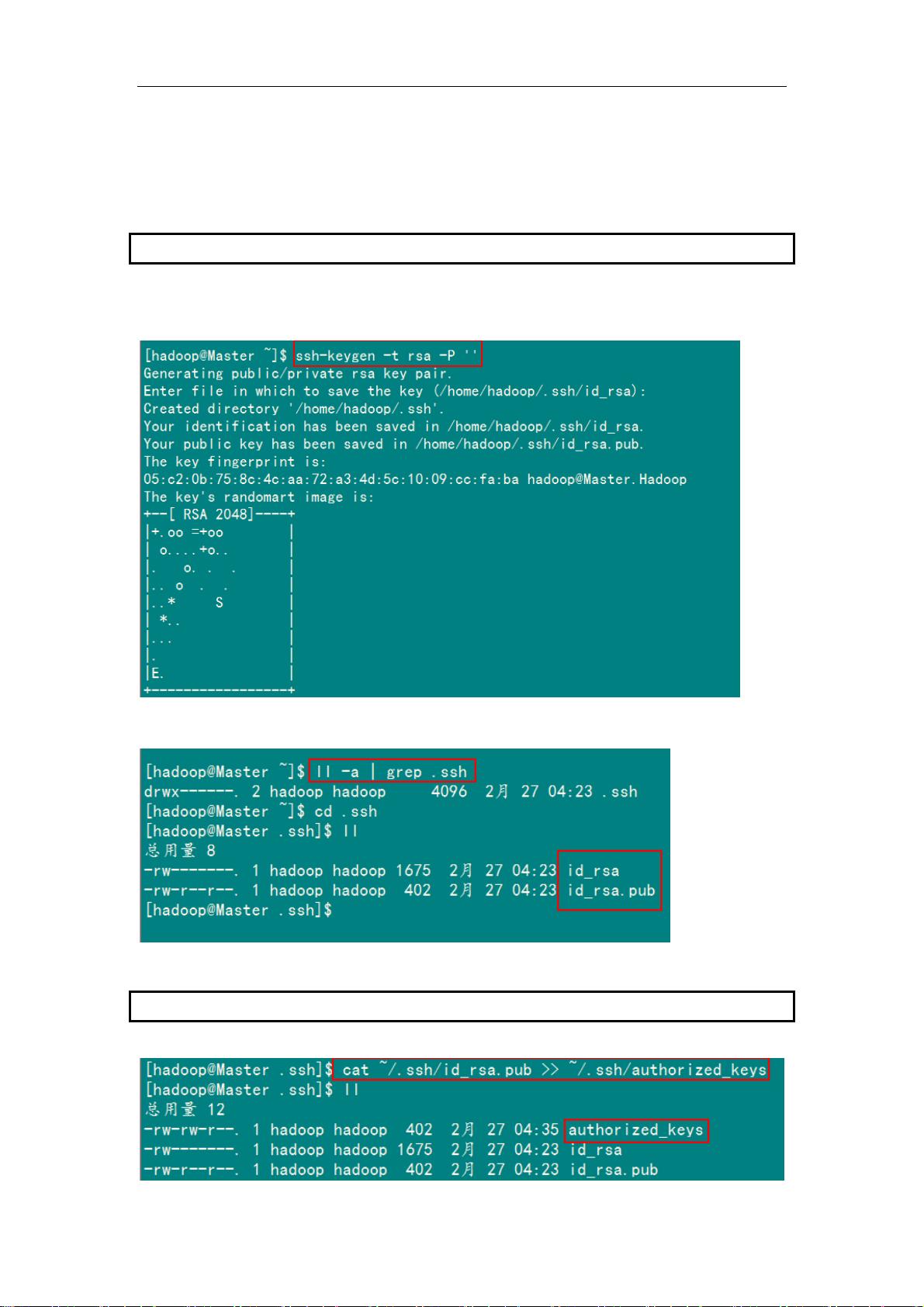
2.1 安装和启动SSH协议
在“Hadoop 集群(第 1 期)”安装 CentOS6.0 时,我们选择了一些基本安装包,所以我
们需要两个服务:ssh 和 rsync 已经安装了。可以通过下面命令查看结果显示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假设没有安装 ssh 和 rsync,可以通过下面命令进行安装。
yum install ssh 安装 SSH 协议
yum install rsync (rsync 是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机间
的文件)
service sshd restart 启动服务
确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登。
.2 配置Master无密码登录所有Salve
r(Nam
eNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器
时,需要在 Master 上生成一个密钥对,包括一个公钥和一
私钥,而后将公钥复制到所有的 Slave 上。当 Master 通过 SSH 连接 Salve 时,Salve 就会
数之后再用私钥解密,并将解密数回传给 Slave,Slave 确认解密数无误之后就允许 Master
2
1)SSH 无密码原理
Maste
Salve(DataNode | Tasktracker)上
个
生成一个随机数并用 Master 的公钥对随机数进行加密,并发送给 Master。Master 收到加密
河北工业大学——软件工程与理论实验室 编辑:虾皮
7
剩余43页未读,继续阅读
2013-07-07 上传
2012-01-31 上传
2024-03-31 上传
2020-11-13 上传
点击了解资源详情
2023-05-04 上传
2024-12-19 上传

zhou_zlun
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
