基于视觉注意的快速场景分析模型:贝叶斯与多尺度特征融合
本文档标题为《基于注意力的计算机视觉模型:快速场景分析》(A Model of Saliency-Based Visual Attention for Rapid Scene Analysis),作者是Laurent Itti、Christof Koch和Ernst Niebur,发表于1998年11月的IEEE Transactions on Pattern Analysis and Machine Intelligence。研究关注的是模仿灵长类动物视觉系统的行为和神经结构,开发出一种高效的视觉注意力模型,以解决复杂场景理解问题。
计算机视觉领域中的“注意模型”是研究的核心,它试图模拟人眼在处理大量视觉信息时的聚焦机制。早期的研究者注意到,灵长类动物在实时场景解析中能够迅速地选择并专注于最具显著性的区域,即使硬件速度有限。这种模型的关键在于设计一种能结合多尺度图像特征的方法,形成单一的显著性地图。
模型的核心组件包括:
1. **多尺度特征提取**:模仿大脑处理不同层次视觉信息的方式,模型通过分析图像的不同细节层次来构建特征,这些特征可能包括颜色、纹理、边缘等。
2. **单一topographical saliency map**:将这些特征整合成一个空间分布的显著性地图,地图上的每个位置表示其在当前图像中的视觉显著度,有助于指示哪些区域最吸引注意。
3. **动态神经网络**:运用动态神经网络来处理这个显著性地图,按照显著度递减的顺序动态地选择需要详细分析的位置。这不仅提高了计算效率,还确保了对最有价值信息的优先处理。
4. **视觉搜索与目标检测**:这种模型有助于实现高效的视觉搜索,帮助计算机在复杂的场景中快速找到潜在的目标或关键元素,这对于自动驾驶、视频监控等应用具有重要意义。
**关键词**:视觉注意力、场景分析、特征提取、目标检测和视觉搜索。
该论文提出了一种基于生物启发的计算机视觉模型,通过模拟大脑的注意力机制,实现了对复杂场景的有效处理,为实时场景理解和目标定位提供了新的计算策略。这种模型在提高计算机视觉任务的性能和效率方面具有潜在的广泛应用前景。
1254 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 20, NO. 11, NOVEMBER 1998
Short Papers
A Model of Saliency-Based Visual Attention
for Rapid Scene Analysis
Laurent Itti, Christof Koch, and Ernst Niebur
Abstract—A visual attention system, inspired by the behavior and the
neuronal architecture of the early primate visual system, is presented.
Multiscale image features are combined into a single topographical
saliency map. A dynamical neural network then selects attended
locations in order of decreasing saliency. The system breaks down the
complex problem of scene understanding by rapidly selecting, in a
computationally efficient manner, conspicuous locations to be analyzed
in detail.
Index Terms—Visual attention, scene analysis, feature extraction,
target detection, visual search.
————————
F
————————
1INTRODUCTION
P
RIMATES have a remarkable ability to interpret complex scenes in
real time, despite the limited speed of the neuronal hardware avail-
able for such tasks. Intermediate and higher visual processes appear
to select a subset of the available sensory information before further
processing [1], most likely to reduce the complexity of scene analysis
[2]. This selection appears to be implemented in the form of a spa-
tially circumscribed region of the visual field, the so-called “focus of
attention,” which scans the scene both in a rapid, bottom-up, sali-
ency-driven, and task-independent manner as well as in a slower,
top-down, volition-controlled, and task-dependent manner [2].
Models of attention include “dynamic routing” models, in
which information from only a small region of the visual field can
progress through the cortical visual hierarchy. The attended region
is selected through dynamic modifications of cortical connectivity
or through the establishment of specific temporal patterns of ac-
tivity, under both top-down (task-dependent) and bottom-up
(scene-dependent) control [3], [2], [1].
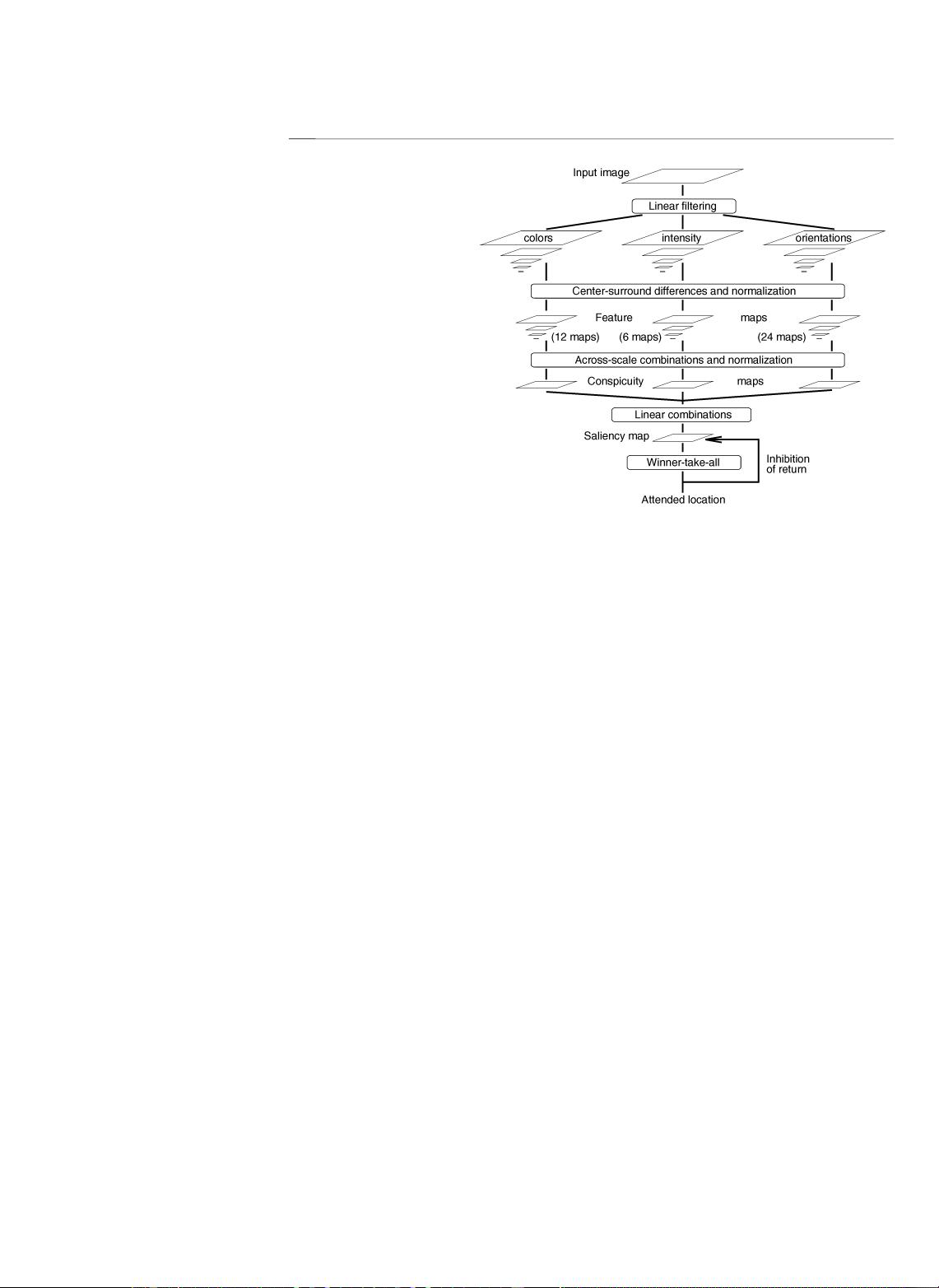
The model used here (Fig. 1) builds on a second biologically-
plausible architecture, proposed by Koch and Ullman [4] and at
the basis of several models [5], [6]. It is related to the so-called
“feature integration theory,” explaining human visual search
strategies [7]. Visual input is first decomposed into a set of topo-
graphic feature maps. Different spatial locations then compete for
saliency within each map, such that only locations which locally
stand out from their surround can persist. All feature maps feed, in
a purely bottom-up manner, into a master “saliency map,” which
topographically codes for local conspicuity over the entire visual
scene. In primates, such a map is believed to be located in the
posterior parietal cortex [8] as well as in the various visual maps in
the pulvinar nuclei of the thalamus [9]. The model’s saliency map
is endowed with internal dynamics which generate attentional
shifts. This model consequently represents a complete account of
bottom-up saliency and does not require any top-down guidance
to shift attention. This framework provides a massively parallel
method for the fast selection of a small number of interesting im-
age locations to be analyzed by more complex and time-
consuming object-recognition processes. Extending this approach
in “guided-search,” feedback from higher cortical areas (e.g.,
knowledge about targets to be found) was used to weight the im-
portance of different features [10], such that only those with high
weights could reach higher processing levels.
2MODEL
Input is provided in the form of static color images, usually digit-
ized at 640 ¥ 480 resolution. Nine spatial scales are created using
dyadic Gaussian pyramids [11], which progressively low-pass
filter and subsample the input image, yielding horizontal and ver-
tical image-reduction factors ranging from 1:1 (scale zero) to 1:256
(scale eight) in eight octaves.
Each feature is computed by a set of linear “center-surround”
operations akin to visual receptive fields (Fig. 1): Typical visual
neurons are most sensitive in a small region of the visual space
(the center), while stimuli presented in a broader, weaker antago-
nistic region concentric with the center (the surround) inhibit the
neuronal response. Such an architecture, sensitive to local spatial
discontinuities, is particularly well-suited to detecting locations
which stand out from their surround and is a general computa-
tional principle in the retina, lateral geniculate nucleus, and pri-
mary visual cortex [12]. Center-surround is implemented in the
model as the difference between fine and coarse scales: The center
is a pixel at scale c Π{2, 3, 4}, and the surround is the corresponding
pixel at scale s = c + d, with d Π{3, 4}. The across-scale difference
between two maps, denoted “*” below, is obtained by interpolation
to the finer scale and point-by-point subtraction. Using several scales
not only for c but also for d = s - c yields truly multiscale feature
extraction, by including different size ratios between the center and
surround regions (contrary to previously used fixed ratios [5]).
2.1 Extraction of Early Visual Features
With r, g, and b being the red, green, and blue channels of the in-
put image, an intensity image I is obtained as I = (r + g + b)/3. I is
0162-8828/98/$10.00 © 1998 IEEE
²²²²²²²²²²²²²²²²
• L. Itti and C. Koch are with the Computation and Neural Systems Pro-
gram, California Institute of Technology—139-74, Pasadena, CA 91125.
E-mail: {itti, koch}@klab.caltech.edu.
•
E. Niebur is with the Johns Hopkins University, Krieger Mind/Brain Insti-
tute, Baltimore, MD 21218. E-mail: niebur@jhu.edu.
Manuscript received 5 Feb. 1997; revised 10 Aug. 1998. Recommended for accep-
tance by D. Geiger.
For information on obtaining reprints of this article, please send e-mail to:
tpami@computer.org, and reference IEEECS Log Number 107349.
Fig. 1. General architecture of the model.
下载后可阅读完整内容,剩余5页未读,立即下载
174 浏览量
104 浏览量
163 浏览量
1296 浏览量
299 浏览量
283 浏览量
163 浏览量
283 浏览量

henryleexh
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
