豆瓣爬虫教程:抓取多页面内容解析
下载需积分: 33 | PDF格式 | 453KB |
更新于2024-09-07
| 71 浏览量 | 举报
"实现不同页面抓取的爬虫教程"
在进行网络爬虫开发时,经常遇到一个问题:网站上的信息分布在多个不同的页面上,如目录、书籍详情和评论等。要抓取这些分散的信息,我们需要设计一个能够处理不同页面结构的爬虫。本教程将以豆瓣网为例,讲解如何构建一个爬虫,维护URL队列,并针对不同类型的页面使用适当的解析函数。
首先,理解网页结构至关重要。前端开发者通常会为同一类型的内容使用相同的HTML模板,这意味着我们可以通过识别这些模板来设计通用的解析策略。例如,在豆瓣网中,书籍的目录页、书籍详情页和评论页虽然内容各异,但它们的HTML结构有共通之处。
为了实现爬虫,我们首先需要建立一个URL列表,这个列表将包含所有我们想要抓取的页面链接。在示例中,给出了几个书籍详情页的URL,它们都以“details”作为关键词。我们可以通过编写一个函数,从豆瓣的目录页获取更多此类URL,然后将其添加到列表中。
```python
def get_book_urls(category):
base_url = 'https://book.douban.com/subject/'
response = requests.get(f'https://book.douban.com/tag/{category}/')
soup = BeautifulSoup(response.text, 'html.parser')
book_links = soup.find_all('a', class_='title')
for link in book_links:
url = base_url + link['href']
urls_list.append(('details', url))
```
这个`get_book_urls`函数通过访问指定分类的目录页(这里以“互联网”标签为例),找到书籍标题的链接,并将其转换为详情页的URL。这样,我们就有了一个URL队列,可以依次处理每个页面。
对于每个URL,我们需要一个对应的解析函数。比如,解析书籍详情页,我们需要提取书名、作者、评分等信息;解析评论页,我们需要提取评论内容和用户评价。可以定义如下的解析函数:
```python
def parse_details(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 解析书籍详情页的逻辑,如提取书名、作者等
pass
def parse_comments(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 解析评论页的逻辑,如提取评论内容、用户评价等
pass
```
在实际爬虫中,我们还需要考虑错误处理、速率限制、反爬策略等问题。例如,可以使用`try-except`块处理请求异常,使用`time.sleep()`控制请求间隔,以及使用代理或模拟登录来应对反爬机制。
最后,我们可以通过循环遍历URL列表,调用相应的解析函数来抓取数据:
```python
for url_type, url in urls_list:
if url_type == 'details':
parse_details(url)
elif url_type == 'comments':
parse_comments(url)
```
通过这样的方式,我们可以高效地抓取并处理分布在不同页面上的信息。然而,请务必遵守网站的robots.txt规则,并尊重网站的使用条款,避免对服务器造成过大的负担。
以
豆
瓣
为
例
的
爬
虫
说
明
在昨天的作业中,有很多人问了我同样的问题,目录,书籍,评论不在同一个页面啊,怎么进行爬取,今天
我以豆瓣为例,教导大家如何维护一个爬虫的url队列,对不同结构的网页分别解析并获取内容
我们必须知道,同样类型的网页结构是相同的,前端工程师,一般在同类型的页面会使用同一个模板,因此我们对
于同一个模板的网页可以使用同一个解析函数,我们将以豆瓣互联网标签下的高排名书籍举例来解决同时爬取不同结
构网页
分
析
网
页
结
构
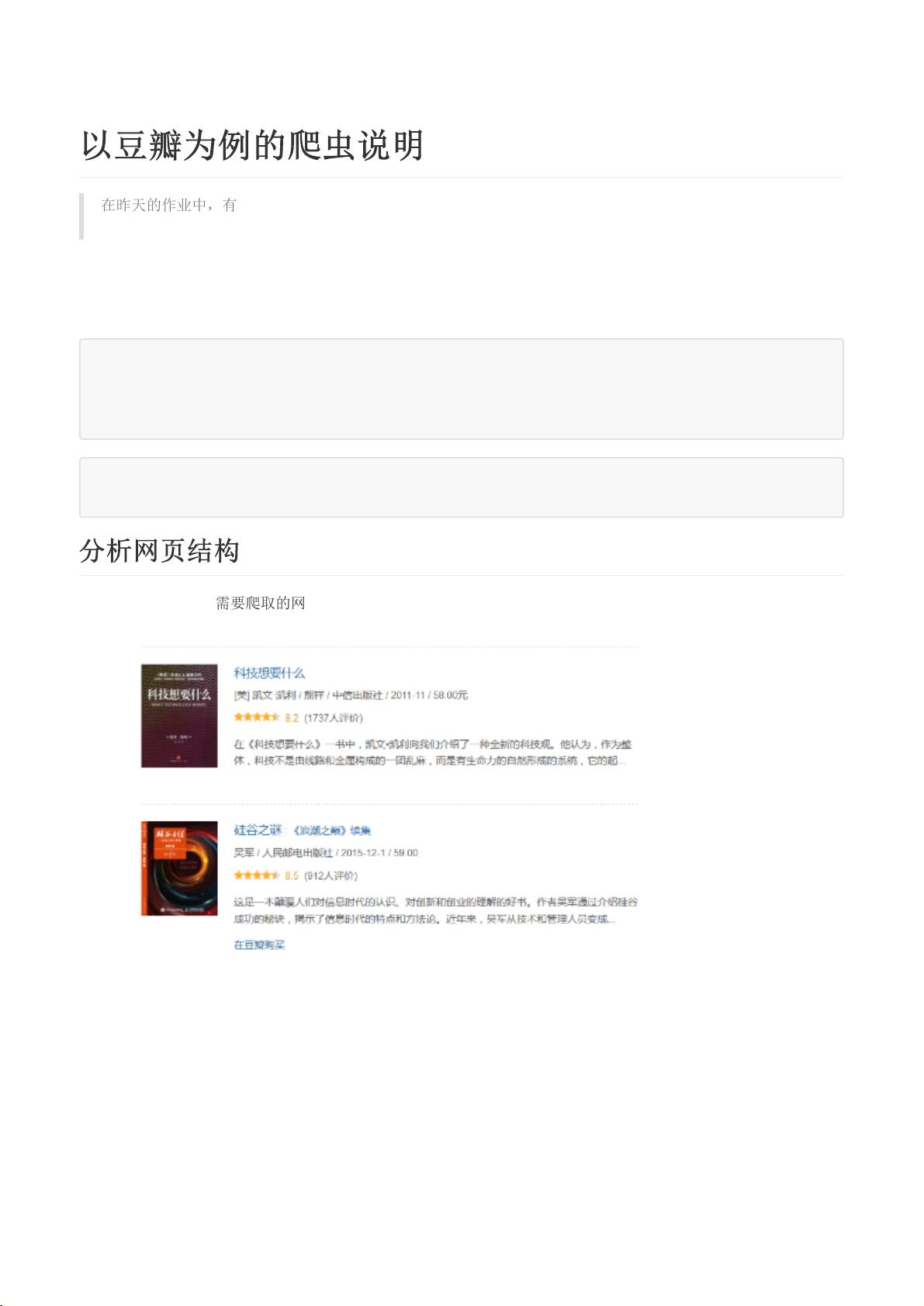
我们首先来看看我们需要爬取的网页,分别是目录页,书籍信息页,书籍评论页
importmatplotlib.pyplotasplt
importrequests
frombs4importBeautifulSoup
%matplotlibinline
#建立一个url列表,我们将从其中取url,并根据不同的关键词进行解析
urls_list=[]
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐


199 浏览量



XGF的碎碎念
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- SmartGit最新版本18.1.1,Git可视化操作更简单
- 探索环境公平:团队项目与可视化研究
- Deno分支的grammy_i18n:本地化支持与TypeScript集成
- EditPlus文本编辑器:Windows平台的好替代
- Code Compare:VS代码比较工具的官方免费安装版
- 全屏秒表倒计时工具:美观易用的计时软件
- 实现教育系统批处理与UI交互的EDUC-PEN-REG-BATCH-API
- IntelliJ Protobuf插件:高效支持Protobuf语言的开发工具
- 海康DS-8632N-E8固件20171211升级指南
- 手机联系人数据通过Service加载至缓存技术解析
- 像素小秘书V1.03绿色免费版:RPG游戏辅助工具
- 创新设计:防折书弹性书夹的原理与应用
- 代码构建的浪漫表白网页 - 学习新技术的项目展示
- 贝基·班伯里·摩根分析全球森林生产力趋势
- CyJsonView v2.3.1: 强大JSON处理与格式化工具
- Java基础入门到进阶全面提升指南
