Python爬虫:解析中国大学排名网页
39 浏览量
更新于2024-08-30
1
收藏 232KB PDF 举报
"中国大学排名定向爬虫实例"
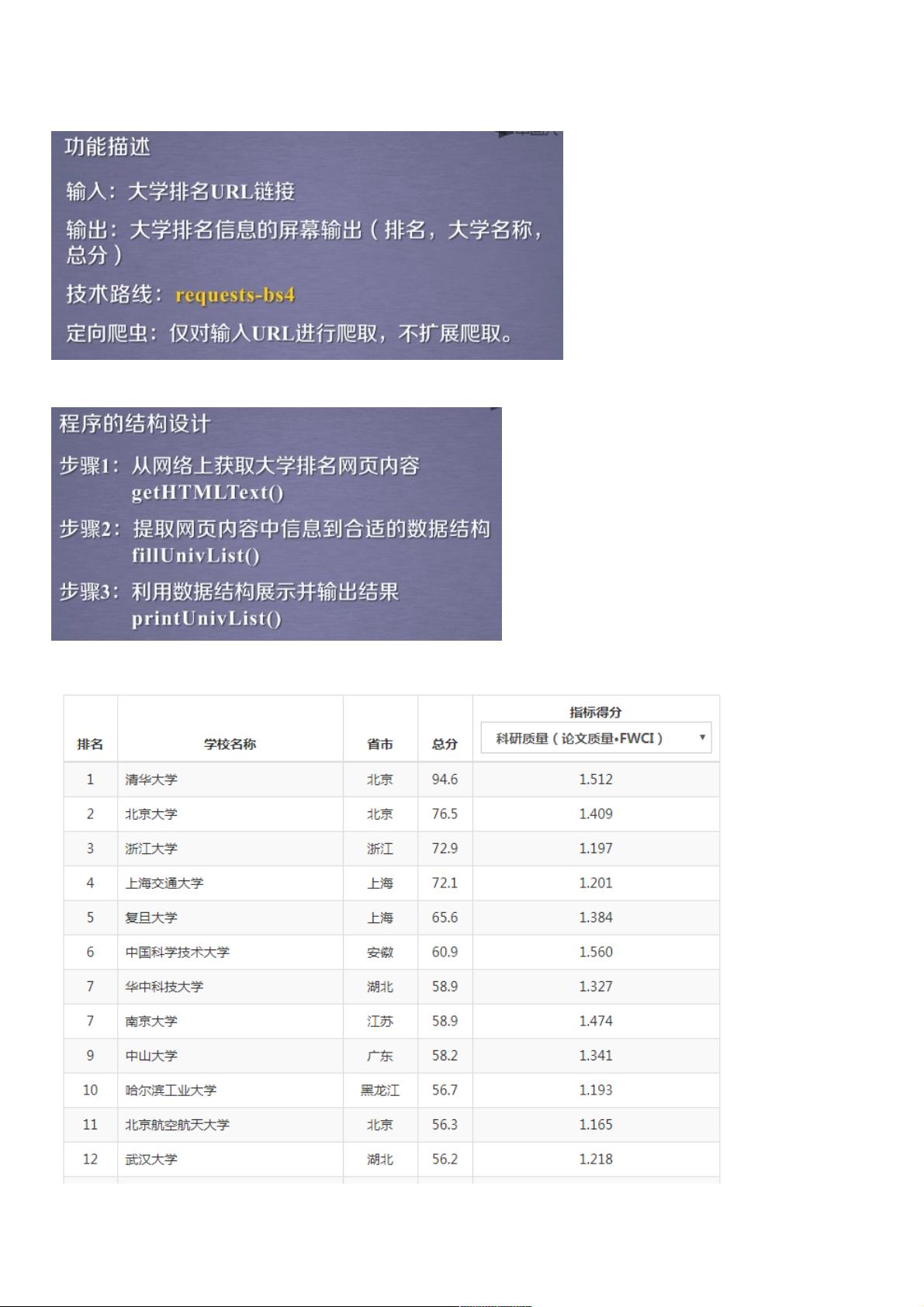
这个实例主要展示了如何使用Python进行网络爬虫,以获取中国大学的排名信息。爬虫程序的主要目的是从特定网页抓取大学的排名、学校名称、所在省市以及总分等数据,并将这些信息以格式化的形式输出。
程序的结构设计分为以下几个部分:
1. **网页结构**:网页通常包含表格结构来展示大学排名信息,每个大学作为一个表格行(tr)存在,行内包含大学的排名、名称、所在地区和总分等信息,这些信息存储在td标签中。
2. **网页代码框架**:在示例中,`#第一个大学`和`#第N个大学`是用于表示每个大学信息的占位符,实际的HTML代码中会有多个这样的tr元素,每个代表一个大学的数据。
3. **爬虫代码**:主要由以下函数组成:
- `getHTMLText(url)`:这是获取网页HTML内容的函数,通过requests库发送HTTP GET请求到指定URL,如果请求成功则返回HTML文本,否则返回"爬取失败"。
- `fillUnivList(ulist, html)`:此函数负责解析HTML并填充列表`ulist`。它使用BeautifulSoup库解析HTML,遍历tbody下的所有tr元素,将每个tr的td子元素内容(即大学信息)添加到ulist列表中。
- `printUnivList(ulist, num)`:用于打印ulist列表中的大学信息,按照特定格式排列。这里默认打印前20所大学的信息。
- `if __name__ == "__main__":`:这是程序的主入口,定义了执行逻辑,包括获取HTML,填充列表,然后打印大学信息。
4. **输出格式优化**:原始的`printUnivList`函数可能没有很好地对齐输出,因此可以优化输出格式,使数据更清晰易读。这可以通过调整字符串格式化的方式实现,例如增加制表符(\t)的使用或使用更现代的f-string来控制列宽。
在这个实例中,我们学习到了如何利用Python的requests库进行网页请求,使用BeautifulSoup库解析HTML,以及如何处理和展示爬取的数据。这为初学者提供了一个基础的网络爬虫实践案例,可以帮助理解网络爬虫的基本工作流程。同时,这个例子也强调了数据格式化的重要性,以提高数据的可读性。
中国大学排名定向爬虫实例中国大学排名定向爬虫实例
功能描述:功能描述:
程序的结构设计:程序的结构设计:
网页结构:网页结构:
网页代码框架:网页代码框架:
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
2020-10-06 上传
2021-11-13 上传
2021-11-13 上传
2018-11-13 上传

weixin_38728183
- 粉丝: 5
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
