Hadoop上HBase详细部署教程:从安装到理解工作原理
需积分: 7 151 浏览量
更新于2024-08-04
收藏 147KB DOCX 举报
"Hbase数据库在Hadoop上的部署详细过程"
HBase是一个专为大数据设计的分布式列式存储数据库,它构建在Hadoop的HDFS之上,提供高效、实时的数据读写能力。HBase的设计灵感来源于Google的Bigtable论文,特别适合处理海量非结构化数据。在Hadoop生态系统中,HBase位于结构化存储层,与HDFS和MapReduce紧密协作,同时依赖ZooKeeper来确保服务的稳定性和故障切换。
HBase的架构由几个关键组件组成,其中包括HBase Master和HRegionServer。HBase Master主要负责HRegion的分配和管理工作,但它不存储实际数据。数据存储在HRegionServer上,每个HRegionServer管理着一部分HBase表,这些表被逻辑地划分为多个HRegion。HRegion是HBase的存储单位,它们在物理上分布在集群的不同节点上,确保负载均衡。
HBase的数据模型基于列族(Column Family),而不是传统的行模式。每个表由多个列族构成,每个列族又包含多个列(Column Qualifiers)。这种设计允许数据按需存储和检索,降低了存储开销,并且在处理大规模稀疏数据时效率较高。
在读写操作中,HBase使用HLog记录所有更新,确保数据一致性。读操作首先检查内存中的BlockCache,如果数据不在缓存中,则查询磁盘上的HStoreFile。HStoreFile采用B树结构,优化了数据的查找速度。每个列族都有一个HStore集合,由多个HStoreFile组成,这些文件在磁盘上组织成高效的索引结构。
在部署HBase时,首先需要一个已安装的Hadoop环境作为基础。在Ubuntu 14.04上,我们需要JDK 7,Hadoop 2.6.0-cdh5.4.5版本,以及HBase的相应安装包。部署步骤包括创建数据目录,下载HBase安装包,解压并配置环境变量,修改HBase的配置文件如`hbase-site.xml`,设置Hadoop相关路径和ZooKeeper地址。最后,启动HBase Master和HRegionServer服务,完成部署。
安装配置过程中,需要注意的是,HBase的配置文件需要根据实际的Hadoop集群情况进行调整,例如设置HDFS的 namenode 地址,以及ZooKeeper的客户端端口等。同时,为了保证高可用性,通常会配置多个HBase Master节点,以实现故障切换。
总结来说,HBase在Hadoop上的部署是一个涉及多步骤的过程,需要理解HBase的基本工作原理和架构,正确配置相关的环境参数,以实现高效、稳定的运行。通过这样的部署,用户可以充分利用Hadoop的存储和计算能力,处理大规模的实时数据需求。
HBase 安装
大
中
小
实验目的
1.了解 HBase 的安装流程
2.了解 HBase 的工作原理
实验原理
HBase 是一个分布式的,面向列的开源数据库,该技术来源于 Fay Chang 所撰写
的 Google 论文”Bigtable:一个结构化数据的分布式存储系统“。HBase 不同
于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同
的是 HBase 基于列而不是基于行模式。在需要实时读写、随机访问超大规模数据
集时,可以使用 HBase。
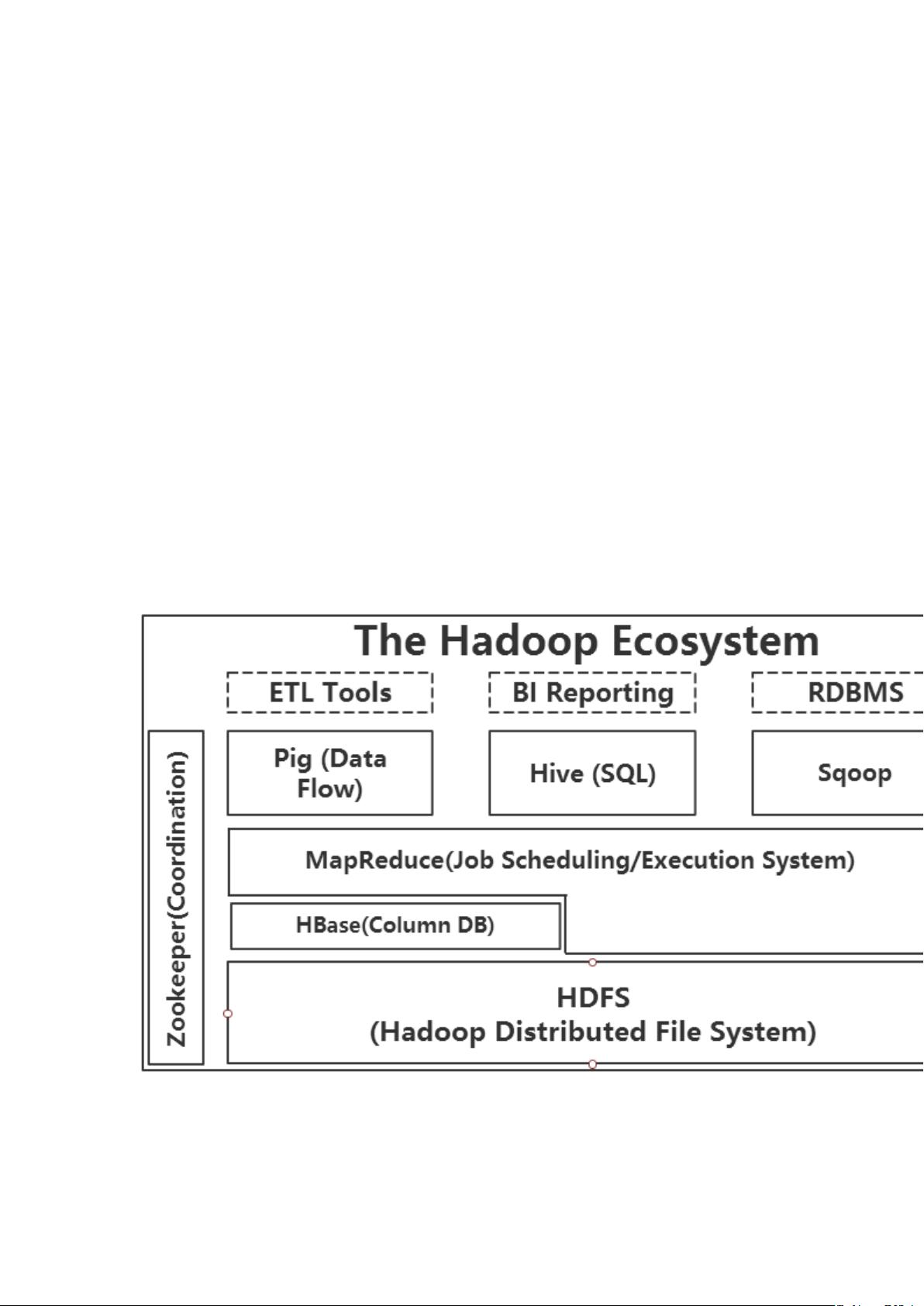
上图描述 Hadoop Ecosystem 中的各层结构。其中,HBase 位于结构化存储层,
Hadoop HDFS 为 HBase 提供了高可靠性的底层存储支持。Hadoop MapReduce 为
HBase 提供了高性能的计算能力,ZooKeeper 为 HBase 提供了稳定服务和故障切
下载后可阅读完整内容,剩余7页未读,立即下载
2015-06-17 上传
2022-04-17 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-12 上传
2014-10-12 上传
2014-06-07 上传
2019-03-21 上传

~O2
- 粉丝: 5
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyPI 官网下载 | foliantcontrib.graphviz-1.0.2.tar.gz
- Boring-Lecture
- gpgLabs:应用地球物理学的教程和示例
- AitechTest-Node-and-Mysql:使用节点和mysql的程序
- libresmartphone:此页面包含在开放式硬件智能手机(libresmartphone)中使用的软件
- franapp
- acinar-analysis-manuscript
- QHeatMap:在Qt中生成热图
- workout_share
- opencv读摄像头上传到前端.rar
- pandas_gdc_agent-0.0.1.tar.gz
- 准备好锻炼学员
- web2icq-开源
- 【IT十八掌徐培成】Java基础第02天-01.java关键字.zip
- SYST17796ABFGM:集团项目回购
- Anti-bar-crx插件
