使用维基百科语料训练Chinese word2vec模型
需积分: 0 109 浏览量
更新于2024-08-05
1
收藏 4.96MB PDF 举报
在进行中文Word2Vec模型训练时,首先需要一个大规模的中文语料库,如中文维基百科(或者搜狗新闻语料库)作为输入数据。本文档提供了一个名为`process_wiki_data.py`的Python脚本,用于处理中文维基百科的XML数据,将其转换成适合Word2Vec模型训练的文本格式。
脚本的第1行声明使用`#!/usr/bin/env python`,这表明这是一个Python可执行文件,可以直接运行。编码设定为UTF-8,确保了对中文字符的正确处理。脚本的主要功能在第9行开始,使用`gensim.corpora.WikiCorpus`模块,这是Gensim库中的一个工具,专为处理结构化的Wikipedia数据设计。
在第19-23行,脚本检查输入参数,确保至少有两个参数,一个是输入的XML文件路径,另一个是输出的文本文件路径。如果参数不足,它会打印帮助信息并退出。
从第27行起,脚本打开输出文件,并创建一个`WikiCorpus`对象,设置了lemmatize参数为False,这意味着在处理过程中不会进行词形还原,保留原始词形。`dic`参数在这里没有明确指定,可能是期望后续传递一个字典文件,以便在处理过程中进行词汇的标准化或映射。
具体操作流程如下:
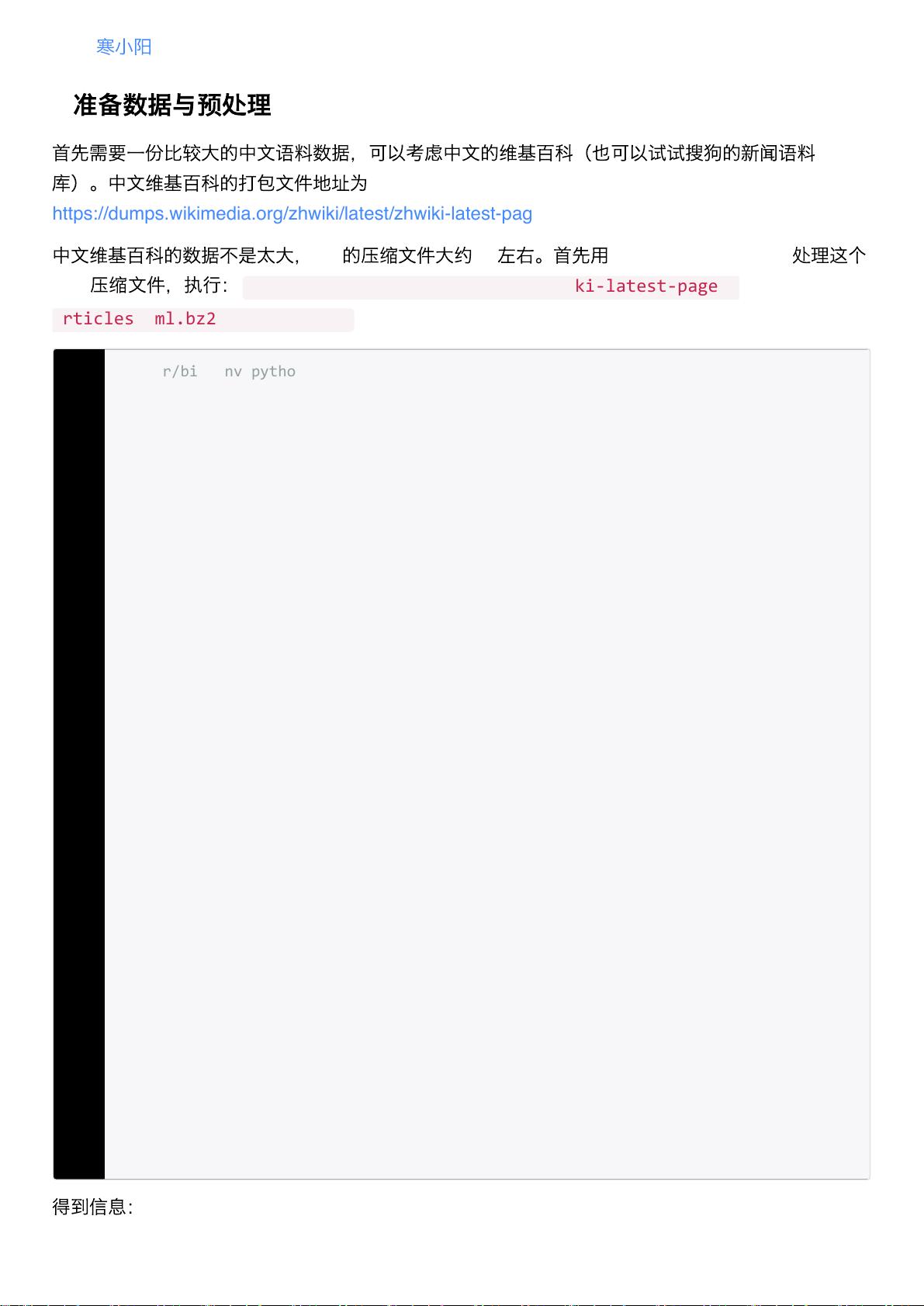
1. **数据获取与准备**:获取中文维基百科的XML文件,如`zhwiki-latest-pages-articles.xml.bz2`,通过`process_wiki_data.py`脚本处理这个压缩文件,将XML数据转换为文本格式。
2. **脚本执行**:运行脚本时,提供两个参数,一个是XML文件的路径,另一个是期望的文本输出文件名。例如:`python process_wiki_data.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text`
3. **数据处理**:脚本逐行读取XML文件,提取相关文本内容,并将其写入到输出文件中。这个过程可能会根据需要进行分词、去停用词等预处理步骤,以减少噪音和提高模型训练效率。
通过这个脚本,我们可以从大规模的中文语料中构建一个词向量模型(Word2Vec),用于学习中文词语之间的语义关系,进而应用于诸如文本分类、文本相似度计算、推荐系统等各种自然语言处理任务。在实际操作中,可能还需要根据实际需求调整参数,并结合其他工具和技术(如`gensim.models.Word2Vec`模型)来实现完整的训练流程。
by @
寒
小
阳
首
先需
要一
份
比
较
大的
中
文
语
料
数
据
,
可
以
考
虑
中
文
的
维
基
百
科
(
也
可
以
试试搜
狗
的
新
闻
语
料
库
)
。
中
文维
基
百
科
的打
包
文
件
地
址
为
https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
中
文维
基
百
科
的
数
据
不
是
太
大
,
xml
的
压
缩
文
件
大
约
1G
左
右
。
首
先
用
process_wiki_data.py
处
理
这
个
XML
压
缩
文
件
,
执
行
:
pythonprocess_wiki_data.pyzhwiki‐latest‐pages‐
articles.xml.bz2wiki.zh.text
1. #!/usr/bin/envpython
2. #‐*‐coding:utf‐8‐*‐
3. #process_wiki_data.py用于解析XML,将XML的wiki数据转换为text格式
4.
5. importlogging
6. importos.path
7. importsys
8.
9. fromgensim.corporaimportWikiCorpus
10.
11. if__name__=='__main__':
12. program=os.path.basename(sys.argv[0])
13. logger=logging.getLogger(program)
14.
15. logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s')
16. logging.root.setLevel(level=logging.INFO)
17. logger.info("running%s"%''.join(sys.argv))
18.
19. #checkandprocessinputarguments
20. iflen(sys.argv)<3:
21. printglobals()['__doc__']%locals()
22. sys.exit(1)
23. inp,outp=sys.argv[1:3]
24. space=""
25. i=0
26.
27. output=open(outp,'w')
28. wiki=WikiCorpus(inp,lemmatize=False,dictionary={})
29. fortextinwiki.get_texts():
30. output.write(space.join(text)+"\n")
31. i=i+1
32. if(i%10000==0):
33. logger.info("Saved"+str(i)+"articles")
34.
35. output.close()
36. logger.info("FinishedSaved"+str(i)+"articles")
得到
信息
:
1.
准
备
数
据
与预
处
理
下载后可阅读完整内容,剩余7页未读,立即下载
446 浏览量
点击了解资源详情
427 浏览量
717 浏览量
5461 浏览量
2037 浏览量
190 浏览量

芊暖
- 粉丝: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言实现LED灯控制的源码教程及使用说明
- zxingdemo实现高效条形码扫描技术解析
- Android项目实践:RecyclerView与Grid View的高效布局
- .NET分层架构的优势与实战应用
- Unity中实现百度人脸识别登录教程
- 解决ListView和ViewPager及TabHost的触摸冲突
- 轻松实现ASP购物车功能的源码及数据库下载
- 电脑刷新慢的快速解决方法
- Condor Framework: 构建高性能Node.js GRPC服务的Alpha框架
- 社交媒体图像中的抗议与暴力检测模型实现
- Android Support Library v4 安装与配置教程
- Android中文API合集——中文翻译组出品
- 暗组计算机远程管理软件V1.0 - 远程控制与管理工具
- NVIDIA GPU深度学习环境搭建全攻略
- 丰富的人物行走动画素材库
- 高效汉字拼音转换工具TinyPinYin_v2.0.3发布
