pandas入门:十分钟理解Series和DataFrame
需积分: 0 181 浏览量
更新于2024-06-30
收藏 1015KB DOCX 举报
"十分钟搞定pandas1"
在学习Python数据分析领域,pandas库是不可或缺的工具。这篇摘要介绍了如何快速上手pandas,包括创建数据对象、查看数据和选择数据等基本操作。首先,我们导入所需的包,通常会使用`import pandas as pd`。
**一、创建对象**
1. 创建Series:通过传递一个list,pandas会自动创建一个Series,并赋予整型索引。
2. 创建DataFrame:可以使用numpy数组,结合时间索引和列标签来构建DataFrame。
3. 字典创建DataFrame:通过一个能够转换为序列结构的字典对象,能够创建具有特定列名的DataFrame。
4. 检查数据类型:使用`dtypes`属性查看DataFrame中各列的数据类型。
5. IPython自动补全:在IPython环境中,使用Tab键可以查看DataFrame的所有属性和列名。
**二、查看数据**
1. 查看头尾:`head()`和`tail()`方法用于查看DataFrame的前几行或后几行。
2. 显示信息:`info()`展示DataFrame的索引、列和底层数据的类型。
3. 数据统计:`describe()`提供快速的统计概览,包括计数、平均值、标准差等。
4. 转置:`T`属性或`.transpose()`用于转置DataFrame。
5. 排序:可以按照轴排序,如`df.sort_index(axis=0)`(按行)或`df.sort_values(by='column_name')`(按值)。
**三、选择数据**
pandas提供了多种选择数据的方式,包括标签选择和位置选择,以及布尔索引。
- **标签选择**
1. 选择单个列:返回Series,例如`df['column_name']`。
2. 通过标签切片多轴选择。
3. 列表索引:如`df.loc['label1', 'label2']`。
4. 索引降维:返回一个标量或Series。
5. 获取标量:`df.at['row_label', 'col_label']`。
- **位置选择**
1. 通过数值索引行,如`df.iloc[row_index, col_index]`。
2. 切片操作类似于numpy。
3. 通过数值列表选择,如`df.iloc[[0, 2], :]`。
4. 切片行和列。
5. 选择特定值。
- **布尔索引**
1. 使用列值筛选,如`df[df['column'] > value]`。
2. `where()`操作:根据条件选择数据。
3. `isin()`方法:根据提供的列表筛选数据。
这些基本操作构成了pandas数据处理的核心,它们使得数据清洗、分析和探索变得更加高效。掌握这些技能,将大大提升你在数据分析领域的效率。为了更深入的学习,可以参考pandas的官方文档和Cookbook,那里有更多关于pandas的详细信息和高级用法。
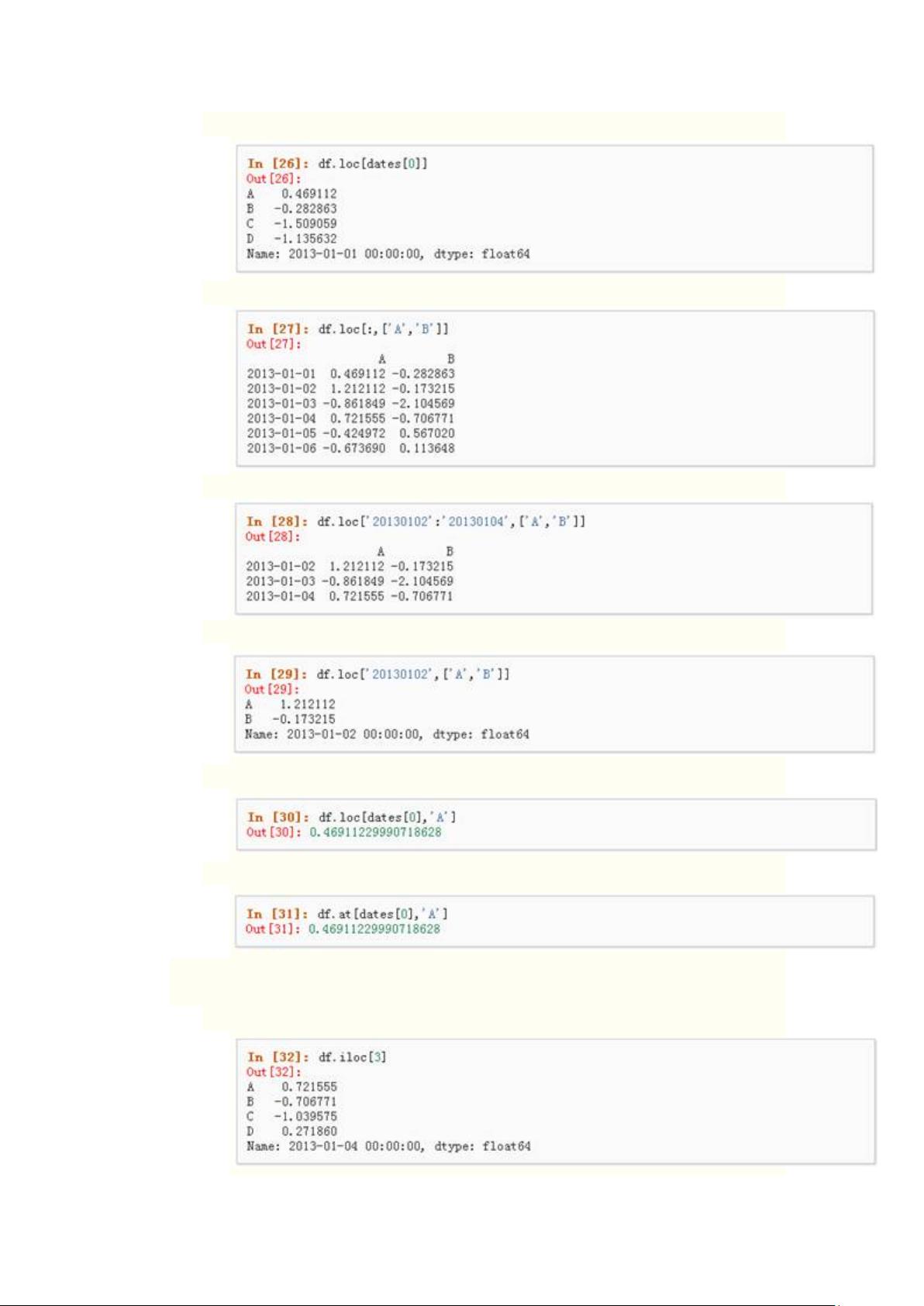
1、 使用标签来获取一个交叉的区域
2、 通过标签来在多个轴上进行选择
3、 标签切片
4、 对于返回的对象进行维度缩减
5、 获取一个标量
6、 快速访问一个标量(与上一个方法等价)
通过位置选择
1、 通过传递数值进行位置选择(选择的是行)
剩余21页未读,继续阅读
230 浏览量
576 浏览量
653 浏览量
208 浏览量
230 浏览量
2022-08-29 上传
208 浏览量
2020-02-27 上传
110 浏览量

经年哲思
- 粉丝: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 揭开JDK与JRE的区别:开发环境与运行环境详解
- Java数组特性与基础用法详解
- Java实现经典递归算法:汉诺塔
- Java字符集详解:从ISO8859-1到Unicode
- Java编程:深入理解static、this、super和final
- uVision2入门:8051微控制器开发教程
- JSP2.0技术手册:深入JavaWeb开发
- JavaScript基础教程:函数与常用操作详解
- 高校医院管理信息系统需求分析
- Oracle SQL基础教程:数据操作与管理
- C#编程基础教程:从入门到精通
- 使用JavaScript创建动态鼠标指针
- 人事管理系统开发与测试实验报告
- 理解计算机系统:信息与程序的核心原理
- JAVA RMI:远程调用的核心技术与应用
- jQuery入门指南:轻松掌握前端开发
