Python爬虫基础与应用
需积分: 0 23 浏览量
更新于2024-06-22
收藏 1.14MB PDF 举报
"python爬虫详解-01c1cfe90608763231126edb6f1aff00bed570cc.pdf"
Python爬虫是一种自动化技术,用于从互联网上抓取大量信息。网络爬虫按照预设规则遍历互联网,通常以网页为单位,收集所需数据。这些程序或脚本可以模拟人类用户的行为,以获取网页内容。网络爬虫的出现是因为通用搜索引擎虽然广泛,但往往不能满足特定信息需求,因此定向抓取特定网页变得重要。
Python之所以适合爬虫开发,主要得益于其易用性和丰富的库支持。Python作为脚本语言,配置简单,处理字符串和文本数据非常灵活。在Python中,像urllib2这样的内置库提供了访问网页文档的API,使得抓取工作变得简单。同时,Python有如Requests和mechanize这样的第三方库,可以模拟浏览器行为,如设置useragent、处理session和cookie,以便应对网站的反爬策略。
此外,Python的BeautifulSoup库则在网页解析方面大显身手,它能方便地处理HTML和XML文档,提取所需文本。这使得Python在处理复杂网页结构时效率高且代码简洁。
Python爬虫通常由五个核心组件构成:
1. 调度器(Scheduler):调度器是整个爬虫系统的“大脑”,它负责协调URL管理器、下载器和解析器的工作流程,确保爬取的有序进行。
2. URL管理器(URL Manager):管理待爬取和已爬取的URL列表,防止重复和循环抓取。URL管理可以通过内存或数据库来实现,以保存和检查URL状态。
3. 网页下载器(Web Page Downloader):这部分负责实际的网络请求,从服务器下载网页内容。它可能需要处理各种HTTP响应,如重定向、错误处理等。
4. 网页解析器(Page Parser):解析器对下载的网页内容进行处理,如去除HTML标签,提取有用信息。BeautifulSoup等库就是在这个环节发挥作用。
5. 应用程序(Application):这是爬虫的核心目标,即从解析后的数据中提取有价值的信息,可能涉及数据清洗、存储或进一步分析。
通过以上组件,Python爬虫可以高效地抓取、解析和利用互联网上的信息,满足特定的业务需求或研究目的。无论是初学者还是经验丰富的开发者,Python都能提供强大的工具来构建定制化的网络爬虫系统。
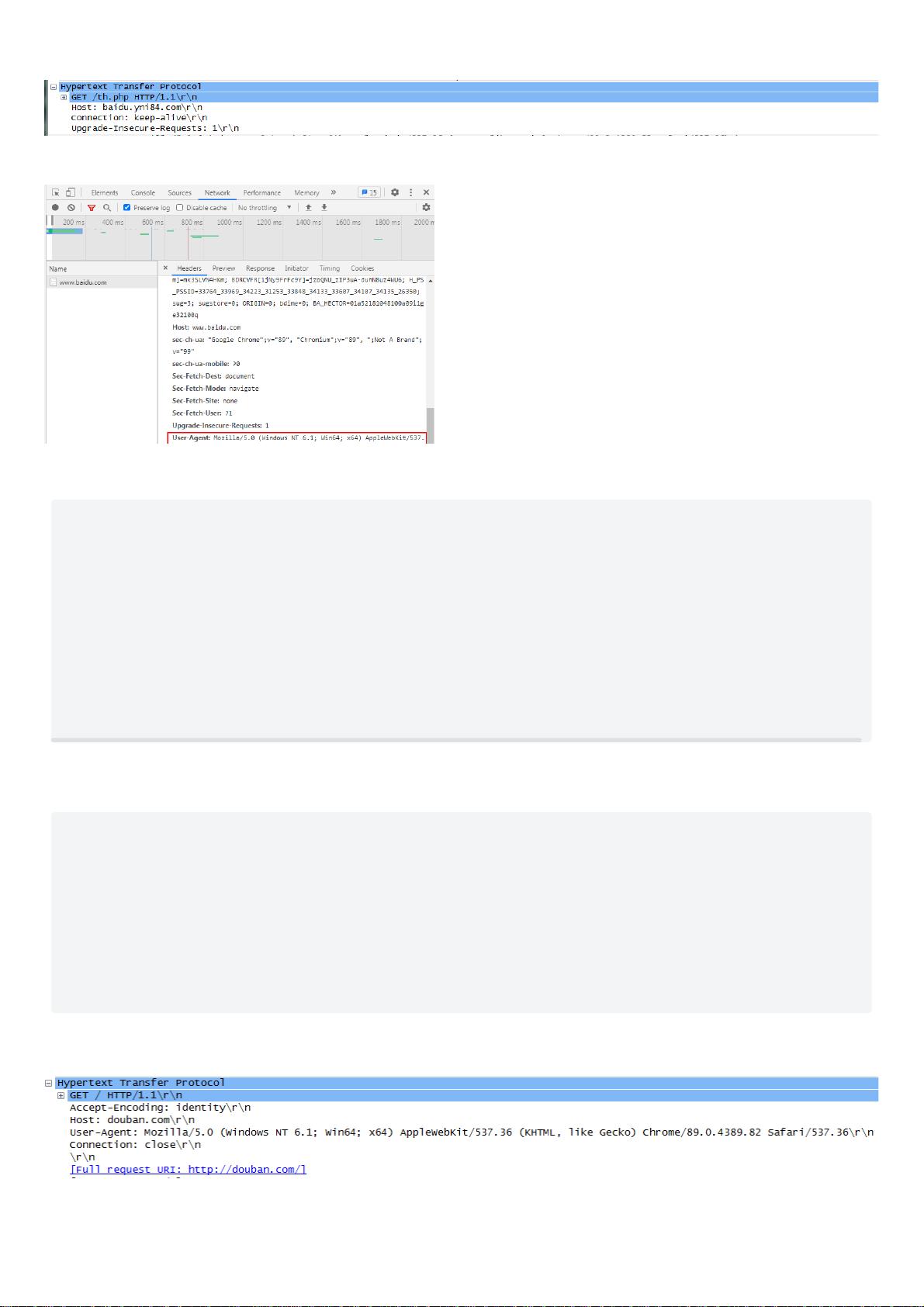
⽽我直接使⽤⾕歌浏览器时,使⽤抓包⼯具获取到的User-Agent如下:
当然也可以直接在浏览器中查看:
例如:我去爬取⾖瓣⽹时:
import urllib.request
url = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))
返回错误:反爬⾍
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418:
HTTP 418 I'm a teapot客户端错误响应代码表⽰服务器拒绝煮咖啡,因为它是⼀个茶壶。这个错误是对1998年愚⼈节玩笑的超⽂本咖啡壶控制协议的引⽤。
⾃定义Headers:
import urllib.request
url = "http://douban.com"
# ⾃定义headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# urlopen(也可以是request对象)
print(urllib.request.urlopen(req).read().decode('utf-8')) # 获取字符串内容,需要指定解码⽅式
当我再次使⽤抓包⼯具,抓取指定请求头的get请求,结果如下:
案例五:设置请求超时时间
我们在爬取⽹页时,难免会遇到请求超时,或者⽆法响应的⽹址,为了提⾼代码的健壮性,我可以设置请求超时时间。
剩余33页未读,继续阅读
2023-03-03 上传
2023-01-30 上传
2023-06-04 上传
2023-05-19 上传
2023-06-02 上传
2023-05-24 上传
2023-06-10 上传
2023-04-20 上传

WTGX_Link
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
