awk:强大的文本格式化与数据抽取工具详解
awk是一款强大的文本数据处理工具,特别是在Linux系统中广泛应用于数据抽取、转换和格式化操作。它的工作原理基于文本文件的行分割,并通过编程式的命令语法执行各种条件判断和数据提取。awk的核心命令格式包括:
1. **命令格式**:
- `-F分隔符`:用于指定输入文件中的字段分隔符,默认为空格,可以自定义如`awk -F: '...'`。
- `-f script-file`:使用预编写的awk脚本文件来处理数据。
2. **处理原理**:
awk通过读取输入文件(如/etc/passwd),将每一行分割成多个域(默认用分隔符分隔),域可以通过变量如`$1`, `$2`等访问。用户可以在`{'command'}`部分编写规则,例如选择性打印、替换、计算等,`BEGIN`和`END`块用于执行在处理开始和结束时的特定操作。
3. **示例应用**:
- 输出特定格式的视图信息:使用`BEGIN`和`END`关键字定义文件头部和尾部,如输出学生ID和姓名的表头和结束标记。
- 正则表达式操作:
- 匹配以28开头的行:`awk '/28/{print $0}'`
- 打印匹配行的特定列:`awk '/28/{print $1 "\t" $2 "\t" $3}'`
- 搜索特定值:查找第二列为"Liulu"的行:`awk '$2 == "Liulu" {print $0}'` 或 `awk '$2 !~ /[Ll]iulu/ {print $0}'`(排除匹配)
- 特定模式匹配:输出第一列以3或4结尾的行:`awk '$1 ~ /^\..[3,4]/{print "..."}`
awk的强大之处在于它的灵活性,不仅能够进行基本的数据提取,还支持复杂的逻辑判断和数据转换。熟练掌握awk对于Linux运维、数据分析和脚本编写都极其重要,因为它能够简化大量的文本处理任务,提高效率。在实际操作中,结合使用正则表达式和关系运算符,awk能够实现高效的数据筛选和格式化,成为数据处理的得力助手。
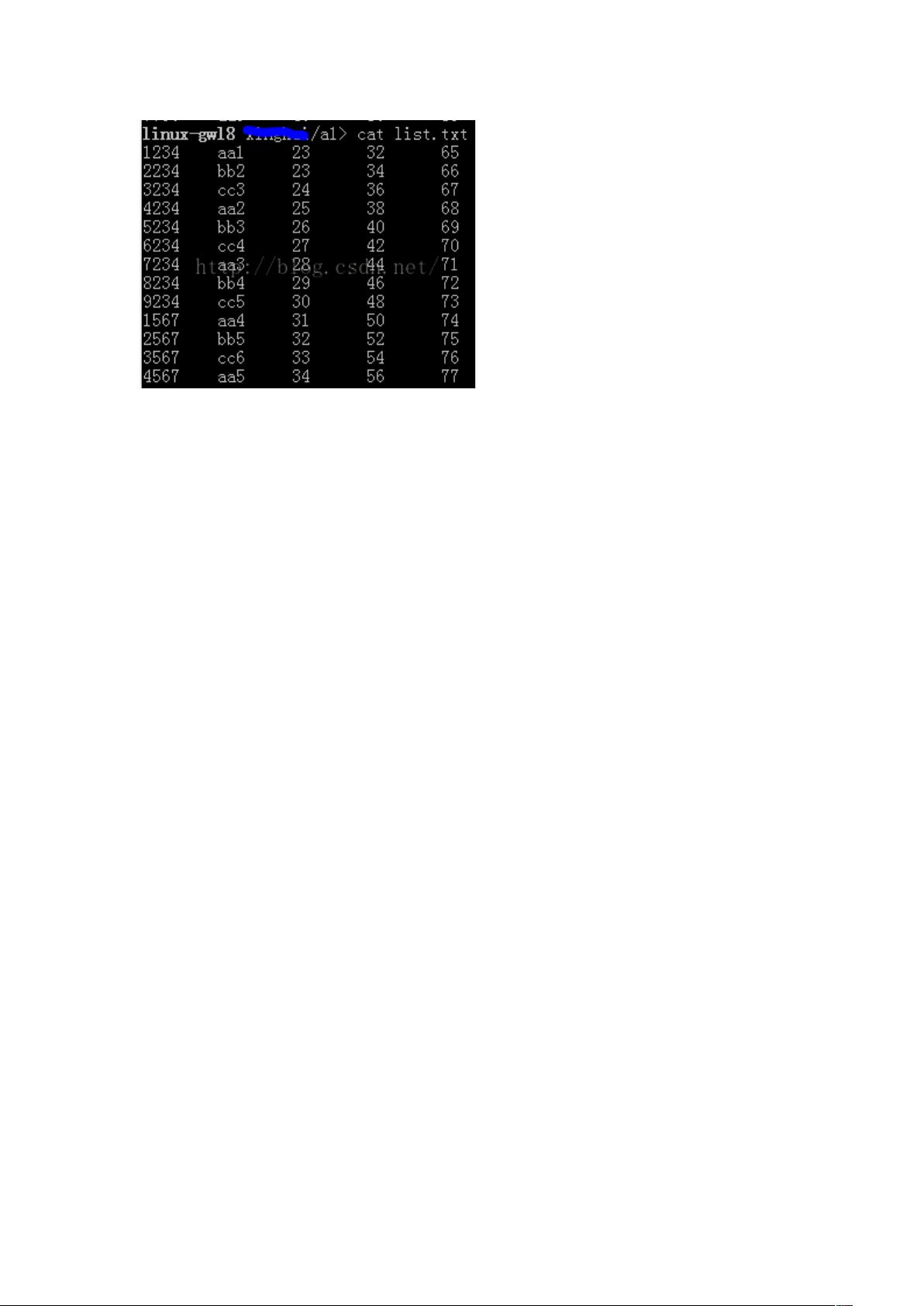
计算每一行第四、五、六列的总和和平均值,并生成第七、八列;最后将新的文本内容保
存到 list_new.txt 中:
awk '{print $1"\t"$2"\t"$3"\t"$4"\t"$5"\t"$3+$4+$5"\t"($3+$4+$5)/3}' list.txt | tee list_new.txt
8. 加入逻辑运算符实现更复杂的匹配操作:
针对上述新生成的 list_new.txt 文件,查找第二列值包含 aa、且第七列值大于 150 的行:
awk '($2 ~/^aa*/ && $6>150){print $0}' list_new.txt
*总之,使用 awk 时,一定要将执行编辑的语句放入单引号内,将多个模式和条件放在小
括号中,函数和流控制语句放入大括号内,避免产生错误。
【在 awk 命令中使用内部变量】
awk 的变量分两种,内部变量(Built-in Variables)和自定义变量。内部变量通常用于控制
输出和保存 awk 当前工作状态等信息,在引用这些变量时通常不需使用$符号。
1. 关于 awk 全部的内部变量说明,可以使用 man awk 查看,在 Built-in Variables 部分有
详细说明(本人使用 awk 版本为 GNU Awk 3.1.8)。下面列举一些常用的
FILENAME:保存被读取文件的文件名
NF:保存当前正在处理记录的域个数(列数),即使只读取本行记录的某几个域,这个值
也会把这行中所有符合分隔符条件的列数记录下来
NR:读取到的行数,当有多个输入文件、读取新文件时,不会被重置
FNR:保存读取当前文件的记录数(行数),当有多个输入文件、读取新文件时,awk 会
重置这个变量
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2008-11-14 上传
2018-03-12 上传
2020-12-21 上传
2022-09-20 上传
2009-04-29 上传
2024-06-12 上传

跬行万里
- 粉丝: 64
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB全常用函数下载,权威性
- 基于C#的 office owc统计图解决方案
- 关于modbus学习的 pdf 文档
- 微软的面试题及答案-超变态但是很经典
- CISCO交换机配置AAA、802.1X以及VACL
- microsoft office excel 2003 函数应用完全手册
- ModBus通讯协议
- 学员信息管理系统PPT答辩稿
- D-LINK校园网设计
- 计算机三级等级考试资料
- 嵌入式C C++语言精华应用
- Java23种设计模式
- java和jsp编程常见到的异常解决方案
- Linux操作系统下C语言编程入门.pdf
- Wrox.Beginning.Shell.Scripting.Apr.2005.eBook-DDU.pdf
- 基于MVC模式Struts框架
