深度学习解析:从监督到无监督
需积分: 5 10 浏览量
更新于2024-06-27
2
收藏 71.31MB PDF 举报
"理解深度学习"
本书《Understanding DeepLearning》由Simon J.D. Prince撰写,旨在深入探讨深度学习这一主题。作者在2022年12月15日发布了此预览版,最终版本预计将于2024年由麻省理工学院出版社(MIT Press)正式发布。所有关于版权的询问应直接向MIT Press的版权和许可部门提出。本书遵循Creative Commons CC-BY-NC-ND许可协议,并欢迎读者提供反馈和建议。
本书内容涵盖了深度学习的基础与核心概念,以帮助读者深入理解这一领域。作者首先介绍了监督学习,这是机器学习的一个主要分支。监督学习包括回归和分类问题,其中,回归问题涉及预测连续值,而分类问题则涉及预测离散类别。输入数据在模型中起着关键作用,它可以是各种形式,如图像、文本或数值数据。
接着,书中详细讨论了机器学习模型,特别是深度神经网络(DNNs)。深度学习的“深度”来源于其多层结构,这些层次允许模型学习复杂的特征表示。DNNs在图像识别、自然语言处理和许多其他领域都表现出卓越的性能。
在监督学习之后,Prince转向了无监督学习。无监督学习不依赖于标记数据,它通常用于发现数据中的模式和结构。书中特别提到了生成模型,这类模型可以学习数据的概率分布,并用来生成新的、类似的数据样本。另一个无监督学习的子领域是聚类,尽管在书中未详细展开,但它同样重要,能帮助我们发现数据的内在结构和群体。
此外,书中还提及了结构化输出,这是一个关键概念,特别是在处理序列数据或需要生成复杂结构(如语法树或图像布局)的任务时。结构化输出的学习通常涉及更复杂的损失函数和解码策略。
《Understanding DeepLearning》是一本面向深度学习初学者和专业人士的详细教程,它不仅涵盖基础概念,还深入到监督和无监督学习的实践应用,以及深度神经网络的关键特性。通过阅读这本书,读者将能够更好地理解深度学习的原理,以及如何在实际项目中应用这些原理。

12 1 Introduction
Figure 1.1 Machine learning is an area
of articial intelligence that ts math-
ematical models to observed data. It
can coarsely be divided into supervised
learning, unsupervised learning, and re-
inforcement learning. Deep neural net-
works contribute to each of these areas.
1.1.1 Regression and classication problems
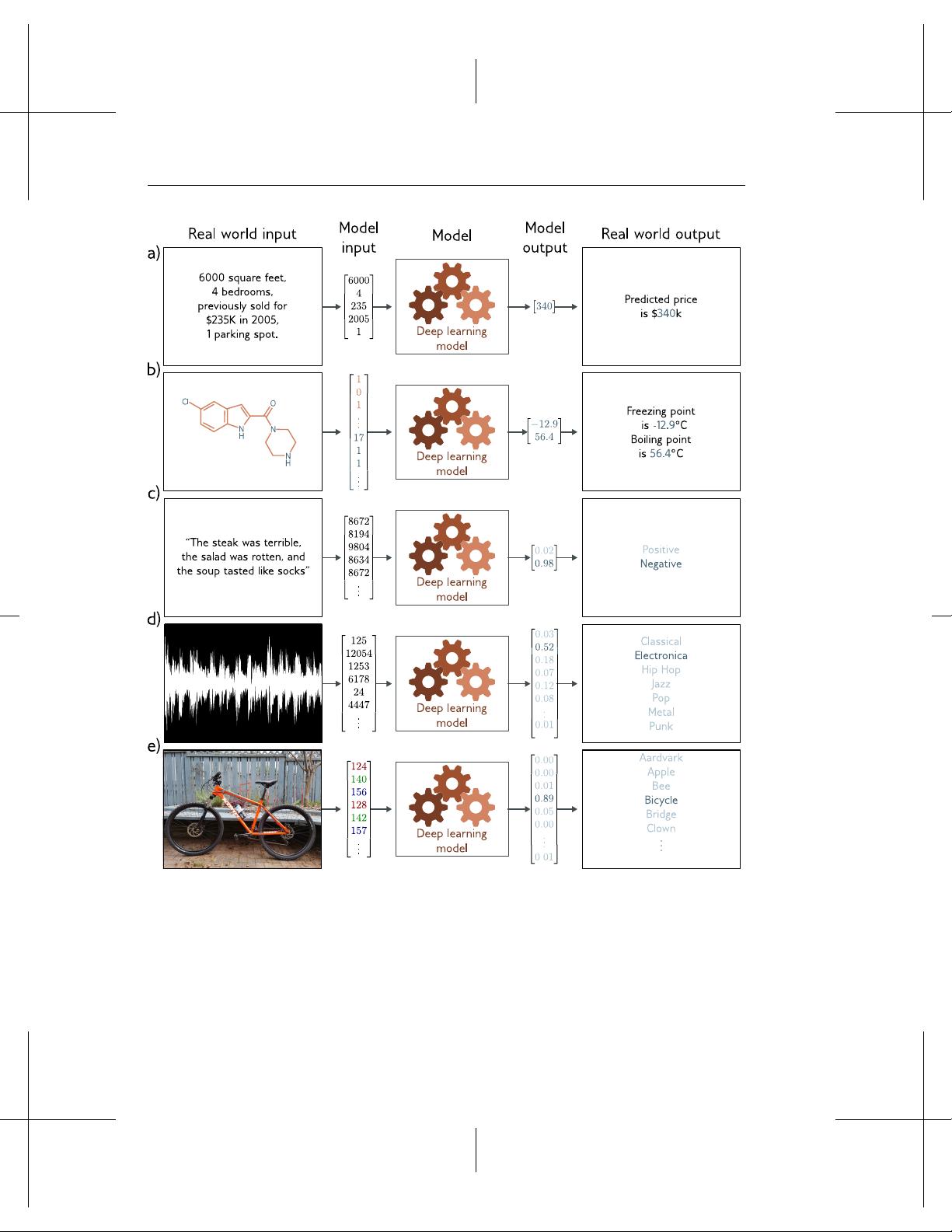
Figure 1.2 depicts several regression and classication problems. In each case, there is a
meaningful real-world input (a sentence, a sound le, an image, etc.) and this is encoded
as a vector of numbers. This vector forms the input to the model. The model maps the
input to an output vector and this is then “translated” back to a meaningful real-world
prediction. For now, we’ll focus on the inputs and outputs and just treat the model as
a black box that ingests a vector of numbers and returns another vector of numbers.
The model in gure 1.2a predicts the price of a house based on input characteristics
like the square footage and number of bedrooms. This is a univariate regression problem;
it is a regression problem because the model returns a continuous number (rather than
a category assignment). It is univariate because it only returns one such number. In
contrast, the model in 1.2b takes the chemical structure of a molecule as an input and
predicts both the melting and boiling points. This is a multivariate regression problem
since it predicts more than one real number.
The model in gure 1.2c receives a text string containing a restaurant review as input
and predicts whether the review is positive or negative. This is a binary classication
problem because the model attempts to assign the input to one of two categories. The
output vector contains the probabilities that the input belongs to each category.
Figures 1.2d and 1.2e depict multi-class classication problems. Here, the model
assigns the input to one of K > 2 categories. In the rst case, the input is an audio le
and the model predicts which genre of music it belongs to. In the second case, the input
is an image and the model predicts which object it contains. In each case, the model
returns a xed-length vector that contains the probabilities of each category.
1.1.2 Inputs
The input data in gure 1.2 varies widely. In the house pricing example, the input is a
xed-length vector containing values that characterize the property. This is an example
of tabular data because it has no internal structure; if we change the order of the inputs
and build a new model, then we expect the model prediction to remain the same.
Conversely, the input in the restaurant review example is a body of text. This may
This work is subject to a Creative Commons CC-BY-NC-ND license. (C) MIT Press.

剩余409页未读,继续阅读
2023-08-12 上传
2020-04-06 上传
2023-05-01 上传
2021-04-22 上传
2018-08-02 上传
2017-11-07 上传

asd8705
- 粉丝: 120
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
