大数据挖掘:价值与知识提取的挑战
需积分: 7 139 浏览量
更新于2024-07-18
收藏 2.21MB PDF 举报
《大规模数据挖掘:理论与实践》(Mining of Massive Datasets)是由Jure Leskovec、Anand Rajaraman和Jeff Ullman三位来自斯坦福大学的专家合著的一本书和在线课程。该课程的第1节介绍了大数据的概论,强调了数据的价值和知识蕴含其中。大数据时代,数据不仅仅是存储和管理的问题,更重要的是如何进行有效的分析,从而挖掘出有价值的信息和模式。
数据挖掘与大数据、预测性分析以及数据科学密切相关。数据挖掘是指从海量数据中发现有意义的规律、趋势和关联,这些规律不仅能对现有数据集有较高的验证性(即在新数据上具有一定的确定性),而且在实际应用中具有实用性,能够指导决策或改进业务流程。
课程开始时,作者强调了数据处理的三个关键环节:存储、管理和分析。存储是确保数据的可访问性和安全性,管理则涉及到数据组织、清洗和整合,而分析则是核心,通过数据挖掘技术,如机器学习算法和统计模型,来提取隐藏在数据背后的有价值信息。
大数据的兴起使得数据量远超过传统数据库的处理能力,这促使我们不得不开发新的技术和方法来应对。例如,使用分布式计算框架(如Hadoop)来处理和分析PB级的数据,以及使用NoSQL数据库来适应非结构化数据的存储需求。
在这一章节中,读者可以了解到数据挖掘的具体应用场景,比如社交网络分析(理解用户行为、推荐系统)、商业智能(销售趋势预测、客户细分)、医疗保健(疾病风险评估)等。此外,还讨论了如何评估数据挖掘结果的有效性和实用性,以及在实际应用中可能面临的挑战,如数据质量问题、隐私保护和算法选择等。
《Mining of Massive Datasets》的第1章为学习者提供了一个全面的大数据挖掘入门,引导读者理解数据的价值并掌握从中获取知识的关键步骤和技术。无论是学术研究还是企业实践,理解和掌握这一领域都对现代社会的决策制定和创新至关重要。
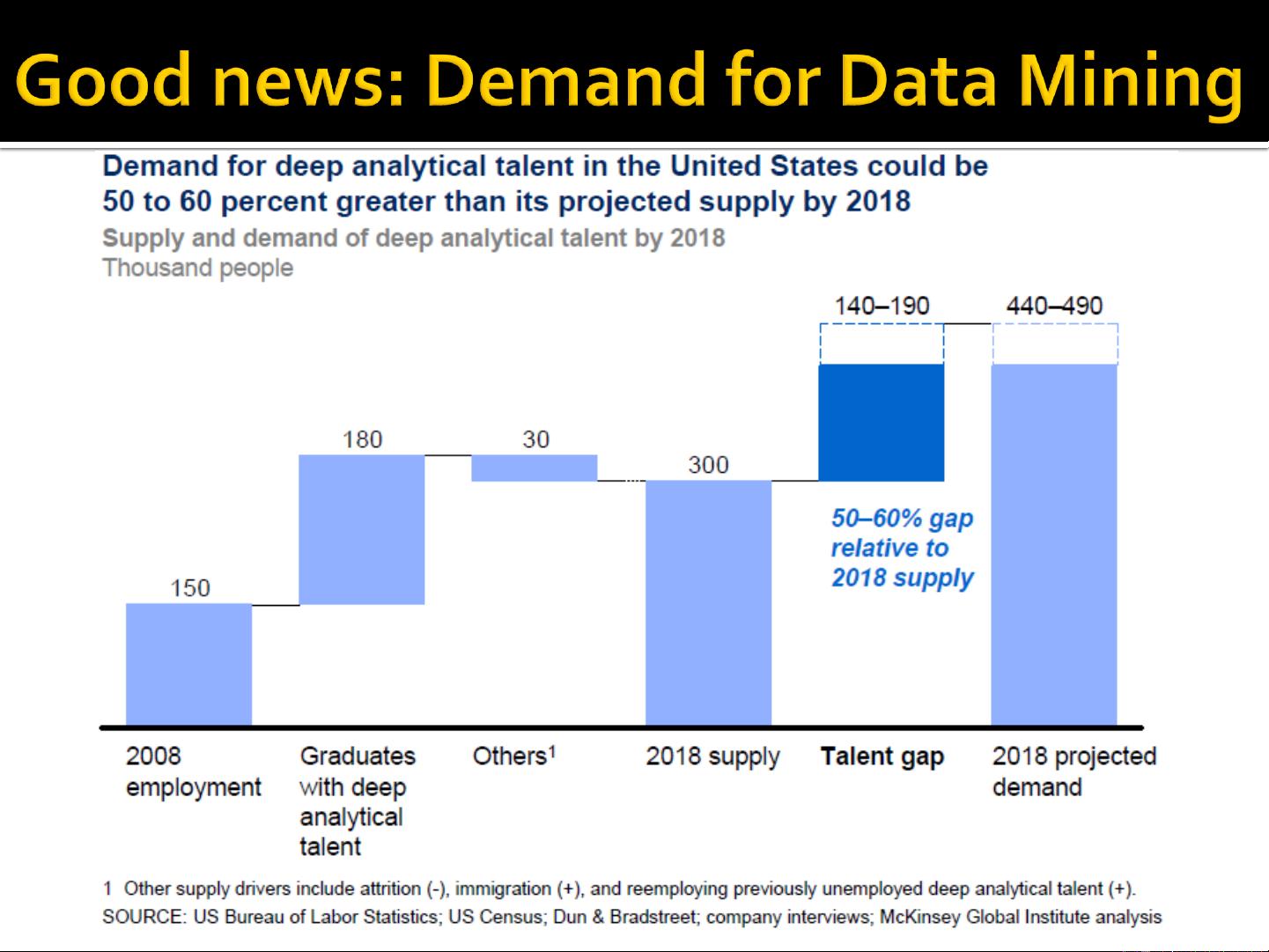
6J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
剩余27页未读,继续阅读
2016-06-01 上传
2017-10-01 上传
2019-06-13 上传
2018-09-19 上传
2012-11-29 上传
2014-12-20 上传
2024-11-06 上传
2024-11-06 上传
2024-11-06 上传

qq_39276198
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
