编译原理:递归下降分析法与文法优化
需积分: 11 68 浏览量
更新于2024-09-20
2
收藏 248KB DOC 举报
"编译原理课后第四章答案"
本章主要涉及编译原理中的递归下降分析方法,这是一种自顶向下的语法分析技术,常用于构造解析器。以下是根据题目给出的内容详解各知识点:
4.1 题目要求为给定的文法设计递归下降分析程序。原文法存在左递归,需要先进行消除。通过改写规则A→Ab|c为A→c{b},可以消除A的左递归。接着,给出了S和A的分析程序,这些程序通常由一系列的函数定义组成,每个函数对应文法中的一个非终结符,函数内部的控制结构反映了文法规则的结构。
4.2 文法G[Z]存在间接左递归,由规则A∷=a|Bb和B∷=Aab引起。在递归下降分析中,如果文法包含左递归或首符号集相交,分析过程可能需要回溯,这会影响效率。题目解释了为什么这个文法无法避免回溯,并提供了一个改写文法以消除回溯的方法。
4.3 对于这个文法,需要去掉左递归并简化表达式部分。通过改写规则,我们消除了<语句>、<表达式>和<项>的左递归,同时利用了后缀表达式的思想,使得分析程序更加简洁。给出了各个非终结符号的分析程序,这些程序遵循了改写后的文法规则。
4.4 这个问题涉及文法的FOLLOW集计算和LL(1)文法的判断。FOLLOW集是每个非终结符在文法中可能出现的下一个符号集合,对于文法G[A],需要逐一计算A和B的FOLLOW集。至于是否为LL(1)文法,LL(1)意味着每个产生式的首符号集互斥且与FOLLOW集不冲突。需要检查文法的所有产生式,确保满足LL(1)条件。
4.5 通常,计算FOLLOW集时,我们需要遍历文法的产生式,根据产生式右部的符号来更新FOLLOW集。例如,对于A::=aABe|ε,B::=Bb|b,我们可以推断出FOLLOW(A)至少包含'e',而FOLLOW(B)至少包含'e'。然后,我们需要检查是否存在冲突,如果不存在冲突,那么文法可能是LL(1)的。
在实际编程实现中,递归下降分析程序通常会用到类似如下的伪代码结构:
```python
def S():
if input_token == 'a':
A()
S()
elif input_token == '|':
consume('|')
(A(), S())
else:
error("Unexpected token")
def A():
if input_token == 'c':
consume('c')
{ produce('b') }
else:
error("Unexpected token")
```
以上就是关于编译原理中递归下降分析方法及其应用的详细解释,包括文法改写、分析程序设计、FOLLOW集计算以及LL(1)文法的判断。这些内容是编译器设计基础的重要组成部分,对于理解编译器如何解析源代码具有关键作用。
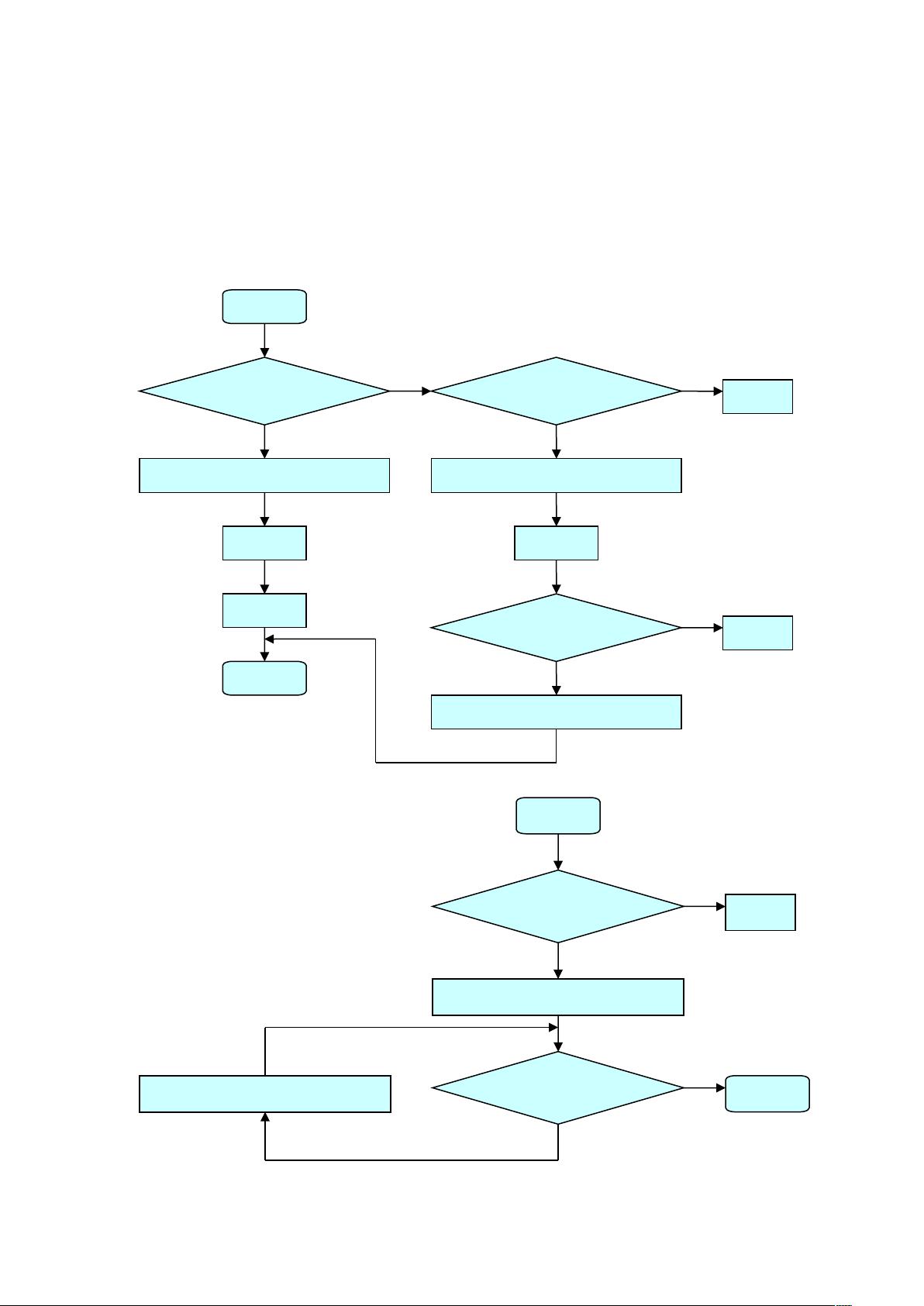
4.1 对下面文法,设计递归下降分析程序。
S→aAS|(A) , A→Ab|c
解:
首先将左递归去掉,将规则 A→Ab|c 改成 A→c{b}
非终结符号 S 的分析程序如下:
非终结符号 A 的分析程序如下:
过程 S
INPUTSYM=’
a’
INPUTSYM= 下一个符号
Y
N
INPUTSYM=’
(’
INPUTSYM= 下一个符号
Y
INPUTSYM=’
)’
INPUTSYM= 下一个符号
Y
N
N
出口
错误
错误
过程 A
过程 S
过程 A
过 程
A
INPUTSYM=’
c’
INPUTSYM= 下一个符号
Y
INPUTSYM=’
b’
N
错误
INPUTSYM= 下一个符号
Y
出口
N
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-05-16 上传
2011-05-16 上传
2011-05-16 上传
2010-04-19 上传
2010-06-05 上传
2009-05-20 上传

agnes717nobel181
- 粉丝: 4
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- Voice-User-Interface:LaunchTech支持助理
- school-ms-netcorewebapi:学校管理系统-使用.NET Core构建的Web API
- OLgallery-开源
- 用于在Python中构建功能强大的交互式命令行应用程序的库-Python开发
- ThreatQ Extension-crx插件
- GeoDataViz-Toolkit:GeoDataViz工具包是一组资源,可通过设计引人注目的视觉效果来帮助您有效地传达数据。在此存储库中,我们正在共享资源,资产和其他有用的链接
- SQL-IMDb:关于IMDb数据集的各种约束SQL查询
- AlgaFoodAPI:藻类食品原料药
- wikiBB-开源
- 参考资料-基于SMS的单片机无线监控系统的设计.zip
- emptyproject-pwa:空项目:PWA + jComponent + Total.js
- React计算
- ux_ui_hw_17
- tamarux-开源
- pytest框架使编写小型测试变得容易,但可以扩展以支持复杂的功能测试-Python开发
- StellarTick-crx插件
