最大熵与条件随机场模型在NLP中的应用解析
版权申诉
"北大语言学 自然语言处理课程 NLP系列课程 8-最大熵和条件随机场模型 ME&CRF 共48页.pptx"
在自然语言处理领域,最大熵模型(MaxEnt Model)和条件随机场模型(Conditional Random Field, CRF)是两种重要的概率建模方法,常用于文本分类、词性标注、命名实体识别等任务。这两者都是基于概率论的机器学习模型,能够处理复杂的输入输出关系。
最大熵模型是一种在给定信息条件下熵最大的概率模型。在自然语言处理中,我们通常处理的是特征丰富的数据,例如句子中的词汇和它们的上下文。最大熵模型假设了模型的预测输出是对所有可能特征的线性组合,这些特征可以是词的出现、词序等。线性组合的系数(权重)通过训练数据来学习,以最大化模型的熵,这意味着在所有可能的模型中,选择不确定性最大的那一个,以避免过早做出过于确定的决策,从而提高泛化能力。
在课程中,通过具体例子展示了如何使用最大熵模型进行词类标注,比如判断单词"can"在不同上下文中可能是动词(VB)、名词(NN)还是助动词(MD)。通过设计一系列特征,如当前词、前后词是否在词汇表中,以及词尾是否为特定后缀等,构建特征向量。然后,模型会学习这些特征的权重,以计算出每个词类的概率,并选取概率最大的作为预测结果。
条件随机场模型则是另一种序列建模方法,它考虑了整个序列的联合概率,而不仅仅是单个元素的概率。与最大熵模型不同,条件随机场不仅依赖于当前的观测值,还依赖于其前后的观测值,因此在处理序列数据时,如词性标注,能够更好地捕捉上下文信息。在词类标注任务中,CRF可以考虑前后词对当前词类的影响,从而更准确地预测词性。
CRF的学习过程是寻找使序列概率最大的模型参数,这通常通过优化算法(如L-BFGS或梯度下降)实现。在预测阶段,CRF模型会计算给定输入序列的所有可能标注序列的联合概率,并选择概率最高的那个作为最终输出。
这两个模型都为解决自然语言处理中的分类问题提供了强大的工具。最大熵模型因其对特征的灵活处理和良好的泛化性能而受欢迎,而条件随机场模型则通过考虑序列依赖,尤其适用于需要上下文信息的任务。理解并熟练运用这两种模型是自然语言处理进阶学习的重要环节。在实际应用中,根据任务特点选择合适的方法,或者结合使用,往往能取得更好的效果。

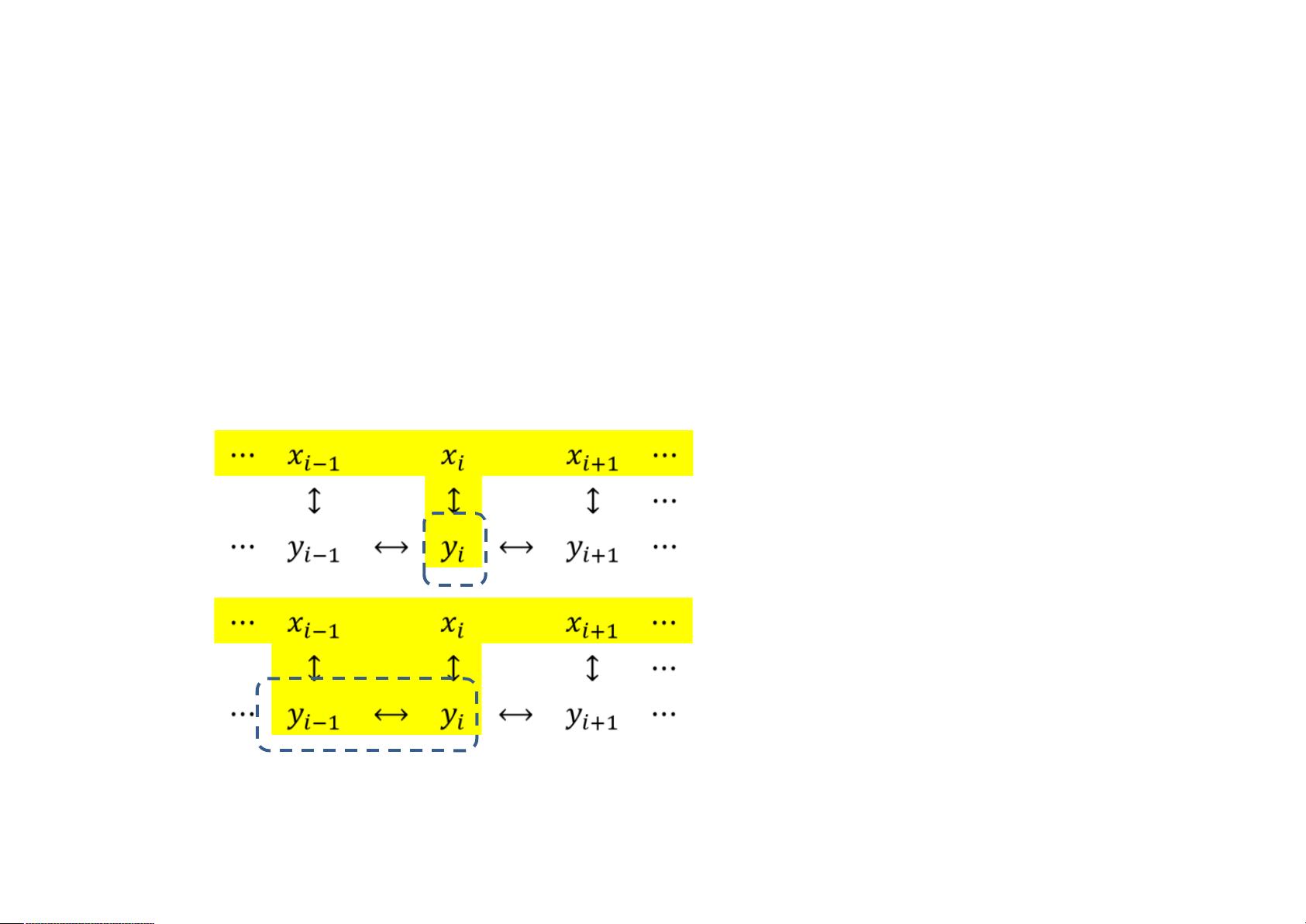
如果我们的问题是序列标注任务,怎么办?
输入对象 是序列,输出也是序列 ,长度相等
1 2 n 1 2 n
剩余47页未读,继续阅读

passionSnail
- 粉丝: 460
- 资源: 7712
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
