深度学习驱动的场景文字检测与识别研究进展
需积分: 10 182 浏览量
更新于2024-07-16
收藏 2.37MB PDF 举报
"这篇论文是《Scene Text Detection and Recognition with Advances in Deep Learning》,由Liu X, Meng G和Pan C共同撰写,并发表在《International Journal on Document Analysis & Recognition》2019年第22卷第2期,页码143-162。论文探讨了深度学习在场景文本检测与识别领域的最新进展,特别是过去五年中的方法,包括文本检测、识别以及端到端识别系统的最新技术。"
正文:
在计算机视觉领域,场景文本检测和识别是一个极具挑战性的研究主题,近年来受到了广泛的关注。它具有多种现实应用,例如帮助视障人士导航以及对自然场景的语义理解。随着深度学习技术的发展,这个领域的研究取得了显著的进步。
该论文详尽地回顾了过去五年中在图像和视频中进行文本检测和识别的技术,特别关注深度学习的应用。深度学习,尤其是卷积神经网络(CNN)和循环神经网络(RNN),已经在图像处理和序列建模方面展现了强大的能力,这使得它们成为解决场景文本问题的理想工具。
1. 场景文本检测:这是识别图像中文字位置的过程。论文可能涵盖了基于连接组件分析的传统方法,如Canny边缘检测和Hough变换,以及基于深度学习的方法,如 EAST(Efficient and Accurate Scene Text Detector)、TextBoxes++ 和 PSENet,这些模型利用CNNs来直接预测文本框的位置和形状。
2. 场景文本识别:这是识别检测出的文本内容的任务。传统方法如OCR(光学字符识别)与现代深度学习方法如CTC(Connectionist Temporal Classification)和Attention机制结合的RNNs(如LSTM或GRU)有显著的区别。现代方法如ASTER和CRNN利用深度学习的序列建模能力,能更好地处理不同形状和方向的文字。
3. 端到端文本识别系统:这种系统将检测和识别过程合并为一个单一的模型,减少了中间步骤的错误传递。例如,端到端的E2E-TextSpotter和SegLink++结合了检测和识别的网络,能够直接从原始图像中输出文本字符串。
此外,论文可能还讨论了数据集、评估指标、公开的代码库和工具包,这些都是推动该领域研究的重要资源。作者们可能分析了当前方法的局限性,提出了未来研究的方向,比如如何处理多语言文本、低光照条件下的文本检测、复杂背景下的识别精度提升等。
这篇论文为研究人员和从业者提供了一个全面了解深度学习在场景文本检测和识别领域最新发展的窗口,对于深入理解这个领域的技术趋势和挑战至关重要。
X. Liu et al.
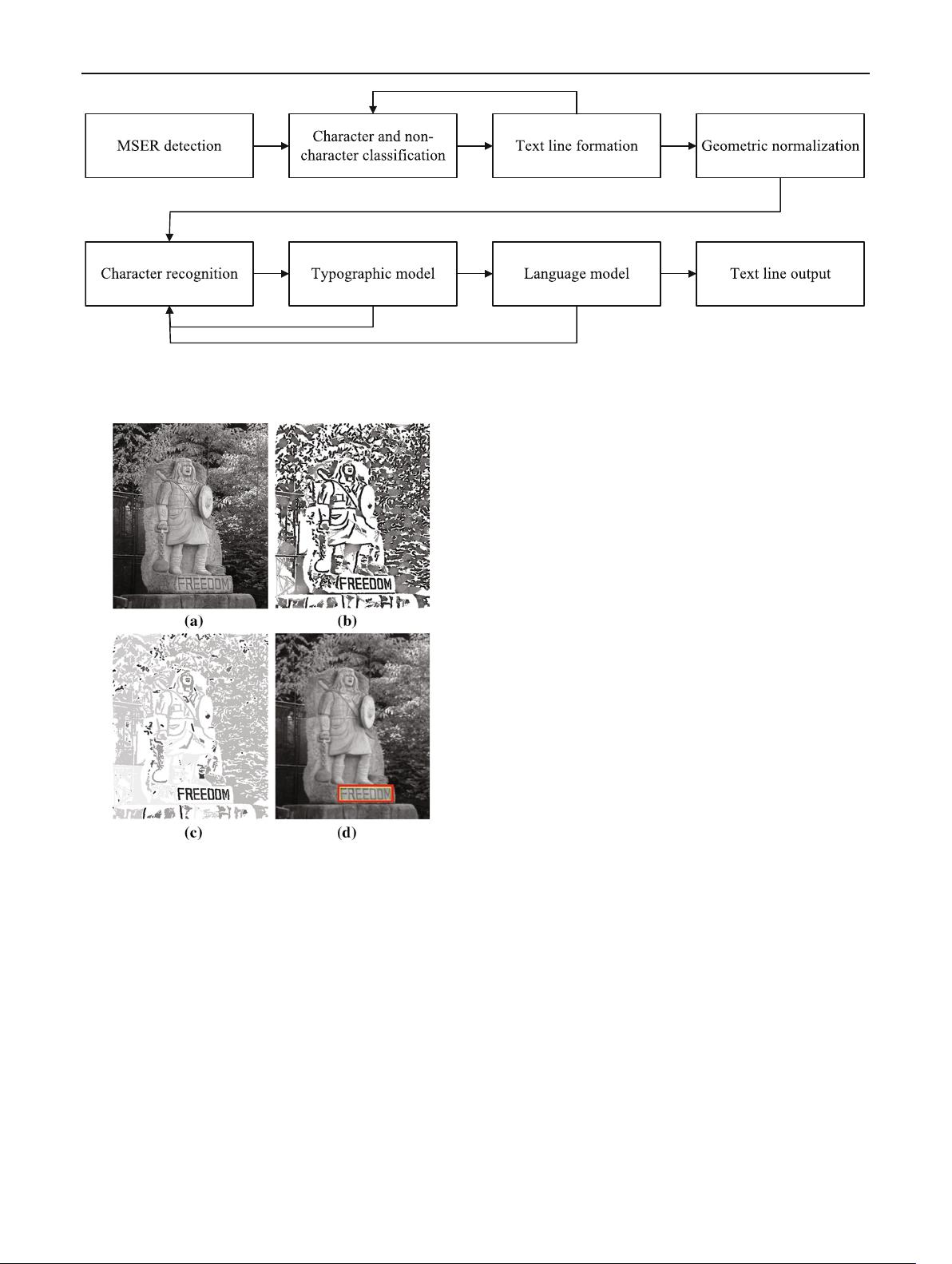
Fig. 2 Flowchart of the method presented by Neumann et al. [1]. This method introduced maximally stable extremal regions (MSERs) which
provides robustness to geometric and illumination conditions
Fig. 3 Results of scene text detection by Epshtein et al. [2]. In their
method, stroke width transform (SWT) is first introduced to distinguish
text objects from non-textual objects from cluttered backgrounds
series of conditions, eventually, the text line is formed (see
Fig. 3). Experiments show that SWT is highly efficient for
text detection. This operator can detect texts in many fonts
and languages, and it is insensitive to multi-scales and multi-
directions. Nevertheless, SWT requires many human-defined
constraints, so it may be failed in some challenging cases.
Yin et al. [3] developed MSER-based methods. They first
extracted character candidates by the proposed MSERs prun-
ing algorithm. Second, single-link clustering algorithm was
adopted to cluster the character candidates into text candi-
dates. Then, they trained a character classifier to eliminate
non-text candidates. Finally, an AdaBoost classifier was used
to detect text. However, there is room for further progress in
detecting multi-orientation, multi-language or highly blurred
texts in lower-resolution natural scene images.
The method proposed by Neumann et al. [4] treats the
character detection problem as an efficient sequential selec-
tion from the set of extremal regions (ERs). This method takes
up less memory, computes faster and maintains real-time per-
formance. Similarly based on extremal regions (ERs), Cho
et al. [5] presented an effective algorithm that can detect
various texts. The algorithm extracted character candidates
by extremal regions (ERs), and non-maximum suppression
(NMS) was used to guarantee the uniqueness and compact-
ness. In addition, double threshold and hysteresis tracking
was adopted to fully detect texts even the candidates with
low confidence. This method achieves high recall rate but is
computationally expensive.
An efficient stroke detector was proposed by Busta et
al. [6]. There are mainly three contributions. Firstly, stroke
ending keypoint (SEK) and stroke bend keypoint (SBK)
were introduced to detect stroke keypoint and then exploited
to produce stroke segmentations. Secondly, they trained an
AdaBoost-based classifier to classify text fragment and back-
ground clutter. Finally, based on text direction voting, they
adopted a text clustering technique to group individual char-
acters into text lines. It is worth noting that, besides computes
fast, this method is scale- and rotation-invariant and supports
a wide variety of scripts and fonts. However, it may be failed
in some challenging cases, such as low image contrast, com-
pact character.
3.1.2 Texture-based methods
The idea behind the texture-based method is that text in image
has distinct textural properties, which can distinguish them
123
剩余19页未读,继续阅读
点击了解资源详情
点击了解资源详情
228 浏览量
446 浏览量
240 浏览量
378 浏览量
2017-03-26 上传

shelleyHLX
- 粉丝: 1302
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







