Apache Kafka:高性能消息系统详解
需积分: 0 186 浏览量
更新于2024-06-30
收藏 951KB DOCX 举报
"Kafka, Scala, 高吞吐量, 消息队列, 分布式, zookeeper, 消息确认机制"
Apache Kafka是一个基于Scala编写的分布式流处理平台,最初由LinkedIn开发并开源。它是一个高效的消息中间件,主要用于构建实时数据管道和流应用。Kafka的主要特点是其高吞吐量、低延迟的设计,使其在处理大量实时数据时表现出色。
1. Kafka的架构:
Kafka的核心组件包括生产者(Producer)、消费者(Consumer)和代理(Broker)。生产者负责发布消息到特定的主题(Topic),消费者则从这些主题中订阅并消费消息。每个主题可以分为多个分区(Partition),以实现水平扩展和负载均衡。Kafka集群由多个Broker组成,每个Broker可以存储一部分主题的分区。为了保证服务的高可用性,Kafka依赖于ZooKeeper集群来存储元数据和协调集群操作。
2. 零拷贝(Zero-Copy)机制:
Kafka的高性能部分得益于零拷贝技术。这种技术允许操作系统避免不必要的数据复制,从而提高消息处理速度。当数据从磁盘读取到网络发送时,零拷贝减少了CPU的负担,提高了I/O效率,使得Kafka能够实现O(1)的复杂度,即常数时间内的消息读写。
3. 消费模式:
与传统的消息队列如RabbitMQ不同,Kafka采用拉取(Pull)模型而非推送(Push)模型。消费者主动从 Broker 拉取消息,而不是等待 Broker 推送。此外,Kafka的消费者会记录消费位置,即偏移量(Offset),以便下次从上次消费的位置继续读取,这提供了消息的有序性和可重复消费的特性。
4. 消息确认机制:
与RabbitMQ等消息系统提供的消息确认机制不同,Kafka默认不支持显式的消息确认。然而,可以通过设置消费者配置来实现幂等性或确保消息至少被消费一次。例如,使用“enable.auto.commit”配置项,消费者可以定期自动提交偏移量,表示消息已被处理。
5. Kafka与其他系统的整合:
Kafka可以方便地与其他系统集成,例如与Hadoop、Spark、Storm等大数据处理框架结合,实现实时数据处理和分析。此外,Kafka Connect API允许开发者创建可插拔的数据连接器,用于数据的导入和导出。
6. 安装与搭建:
Kafka的集群搭建涉及到安装ZooKeeper,配置Kafka服务器参数,创建主题,以及设置生产者和消费者的相关参数。安装过程需要关注网络通信、磁盘空间和性能优化等方面。
Apache Kafka作为一个强大的消息中间件,以其高吞吐、低延迟和灵活的架构,在实时数据处理领域得到了广泛应用。理解Kafka的基本原理和特性对于构建高性能的实时数据流系统至关重要。
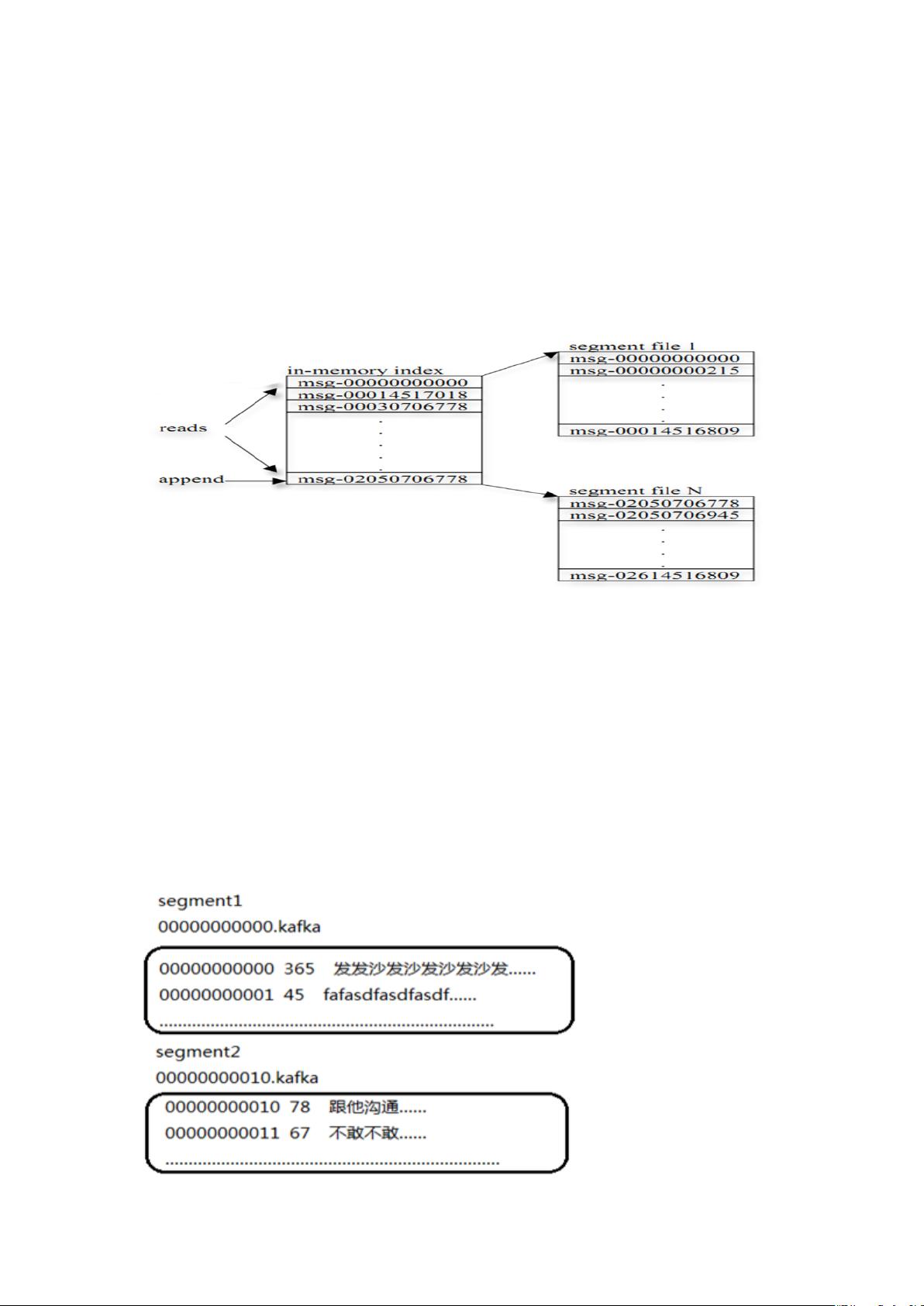
segment
1、 每个 segment 中存储多条消息,消息 id 由其逻辑位置决定,即从消息 id 可直接定位到
消息的存储位置,避免 id 到位置的额外映射。
2、 当某个 segment 上的消息条数达到配置值或消息发布时间超过阈值时,segment 上的消
息会被 flush 到磁盘,只有 flush 到磁盘上的消息订阅者才能订阅到
3、 segment 达到一定的大小(可以通过配置文件设定,默认 1G)后将不会再往该 segment
写数据,broker 会创建新的 segment。
offset
offset 是每条消息的偏移量。
segment 日志文件中保存了一系列"log entries"(日志条目),每个 log entry 格式为"4 个字
节的数字 N 表示消息的长度" + "N 个字节的消息内容";
每个日志文件都有一个 offset 来唯一的标记一条消息,offset 的值为 8 个字节的数字,表示
此消息在此 partition 中所处的起始位置.
每个 partition 在物理存储层面,有多个 log file 组成(称为 segment).
segment file 的命名为"最小 offset".log.例如"00000000000.log";其中"最小 offset"表
示此 segment 中起始消息的 offset.

剩余32页未读,继续阅读
2022-08-08 上传
2022-01-21 上传
点击了解资源详情
2023-07-28 上传
2022-04-28 上传
2021-01-07 上传
2015-05-28 上传
2021-01-07 上传

三山卡夫卡
- 粉丝: 26
- 资源: 323
 我的内容管理
展开
我的内容管理
展开







最新资源
- 毕业设计&课设-混合动力电动汽车的性能和效率仿真.zip
- crunch:高级 DXTc 纹理压缩和转码库
- Water-plant-scheduler:该应用程序使用户能够为其植物创建浇水时间表。 功能包括
- VNET:肺肿瘤分割
- Terraia-ChestTweaks:Minecraft Mod,仿写 Terraria 的箱子整理功能
- matlab求导代码-CO2-System-Extd:用于MATLAB(或GNUOctave)的CO2SYS软件,用于计算海洋CO2系统变量并
- ABB快速上手神器.zip
- 毕业设计&课设-基于Matlab的Intertial导航仿真.zip
- zoomy:终端的Zoom实用程序
- CODE injector-crx插件
- 猜猜我有多爱你flash动画
- matlab求导代码-PRST:Python水库模拟工具箱
- driver_load.rar
- freeglut 3.2.1 vs2017 64位
- dhh
- nodejs-dashboard:来自终端的node.js应用程序的遥测仪表板!
