




红楼梦作者身份:统计分析揭示前后差异
需积分: 45 125 浏览量
更新于2024-07-17
6
收藏 832KB PDF 举报
本文以《红楼梦》的作者解析为核心,运用统计分析方法探讨了该作品前八十回与后四十回的作者归属问题。首先,作者针对问题一,将小说分为每二十回和每四十回的两个阶段,通过MATLAB、SPSS或Python等工具分析人物名称的频率变化。通过对27个主要人物的出现次数进行计算和聚类分析,并借助配对样本\( T \)检验,结果显示人物名称的使用频率并不能揭示出作者的差异。
针对问题二,虚词的使用情况被选为研究对象,选取47个具有代表性的虚词,如“偷懒”、“躲懒”和“托懒”的变体。同样采用频率分析和聚类方法,以及\( T \)检验,发现虚词频率的变化支持了前八十回和后四十回作者不同的观点。
问题三,作者进一步考察了词语之间的语义相关性,选择七类同义词组进行数量和词频分析,通过卡方检验来衡量各组之间的文本相似度。结果显示,第一组和第二组的文本相关性较高,而与第三组(后四十回)的对比则显示出显著差异,从而支持了两部分作者不同的论断。
最后,文章提出两种补充分析方法。方法一是通过标点符号的频率统计,利用SPSS软件进行卡方分析,以识别不同章节样本的差异;方法二是平均词长分析,通过ICTCLAS汉语词法分析系统,观察不同章节的词汇构成和纯文本字符比例,以此作为判断作者风格的依据。
本文通过严谨的统计分析,结合多维度的数据处理和统计测试,有力地论证了《红楼梦》前八十回和后四十回的作者并非同一人。这种方法不仅揭示了文本内部结构的细微差别,也为我们理解文学作品的创作历程提供了新的视角。
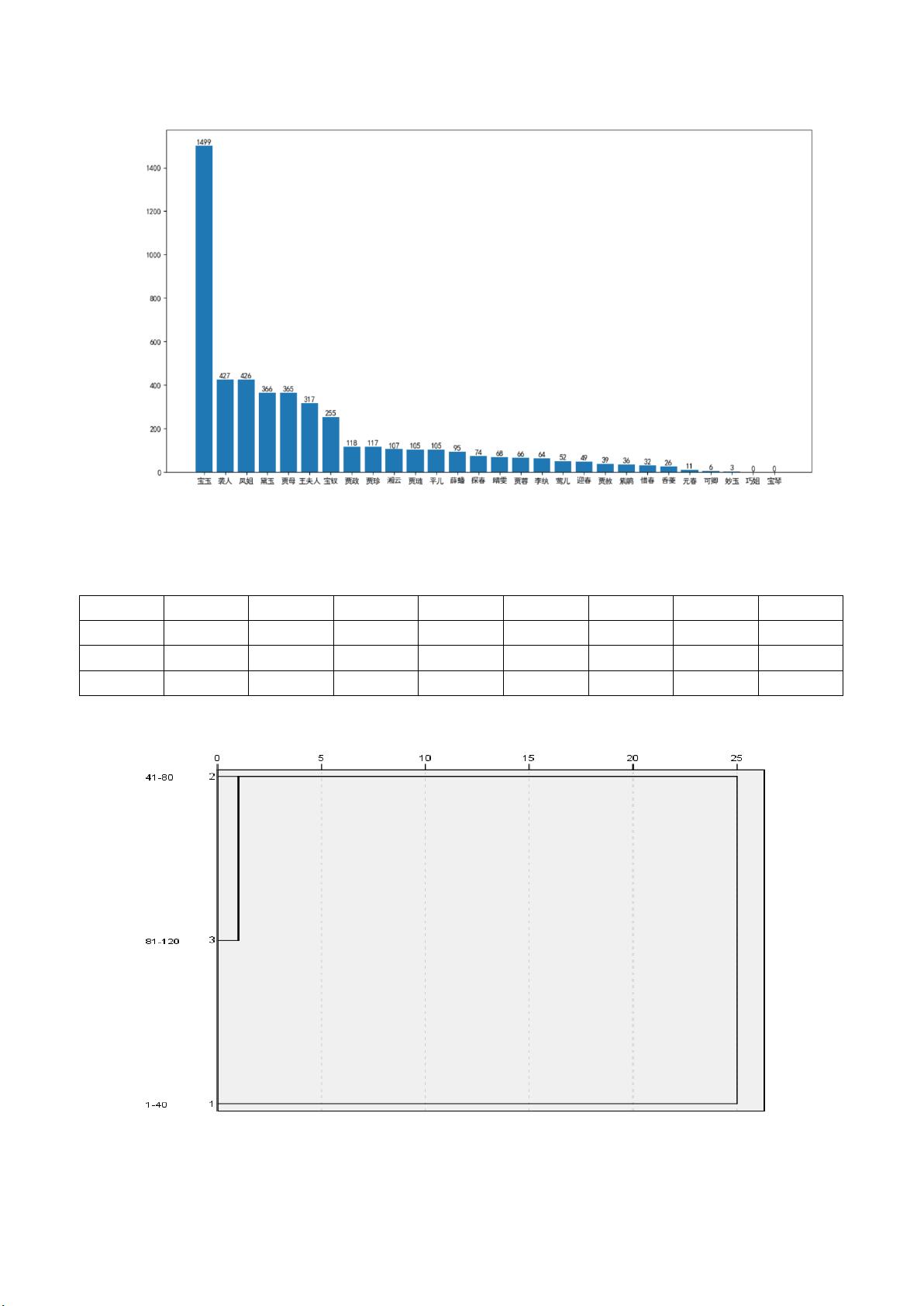
图 2:1-40 回主要人物出现次数
Step2:计算三个样本人物出现的频率(这里只展示部分数据,其余见附录人物
频率统计),结果如下:
章回
宝玉
凤姐
黛玉
王夫人
贾母
袭人
贾蓉
薛蟠
1-40
0.310738
0.088308
0.075871
0.065713
0.075663
0.088516
0.013682
0.019693
41-80
0.185885
0.076221
0.064712
0.046906
0.082736
0.0519
0.020413
0.024756
81-120
0.211005
0.078243
0.067643
0.08245
0.086993
0.067979
0.00488
0.007067
表 1:部分人物频率统计表
Step3:利用 SPSS 软件进行系统聚类分析,结果如下:
图 3:40 回人物频率聚类结果图
Step4: 将文章每 20 回作为一个样本,分别统计每个样本主要人物出现的次数。
下载后可阅读完整内容,剩余21页未读,立即下载
823 浏览量
249 浏览量
107 浏览量
2024-11-03 上传
117 浏览量
343 浏览量
2024-11-03 上传
591 浏览量

mytzs123
- 粉丝: 6893
 我的内容管理
展开
我的内容管理
展开








最新资源
- Haroopad Linux版发布:跨平台离线Markdown编辑器
- 离线安装Kubernetes 1.24.1环境教程
- Delphi7图书管理系统源码详解与应用
- NEC WriteEZ3_78K0 FLASH编程器GUI使用教程
- PHPWord库:轻松处理Word文档内容
- C#语言中的元启发式算法探究
- 深入分析VNC源码与协议细节
- Android NumberPicker实现城市与生日选择功能
- PHPUnit测试用例展示PHP操作Excel库功能
- Java项目实战:demoproject2技术解析
- LabVIEW中传统与小波去噪算法性能对比研究
- VC字符转换为十进制与十六进制教程
- Android面试题整理:从朋友处收集的精选题目
- QT编程实践:图书管理系统开发教程
- A星算法在Winform中的自动寻径功能演示
- 清华版数据结构教程精要讲义






















