CentOS上伪分布式Hadoop安装步骤详解
需积分: 10 158 浏览量
更新于2024-09-03
收藏 403KB PDF 举报
"该资源是一份关于Hadoop伪分布式安装的详细教程,主要适用于大数据处理环境,涵盖了从系统准备、用户创建、SSH无密码登录设置到Hadoop安装和配置的所有步骤。"
在分布式计算领域,Hadoop是一个广泛使用的开源框架,它能够高效地处理和存储大量数据。本教程详细讲解了在伪分布式模式下安装Hadoop的过程,这种模式适用于单机环境中模拟分布式环境,可以理解为在一台机器上运行多个Hadoop进程,模拟多节点集群的行为。
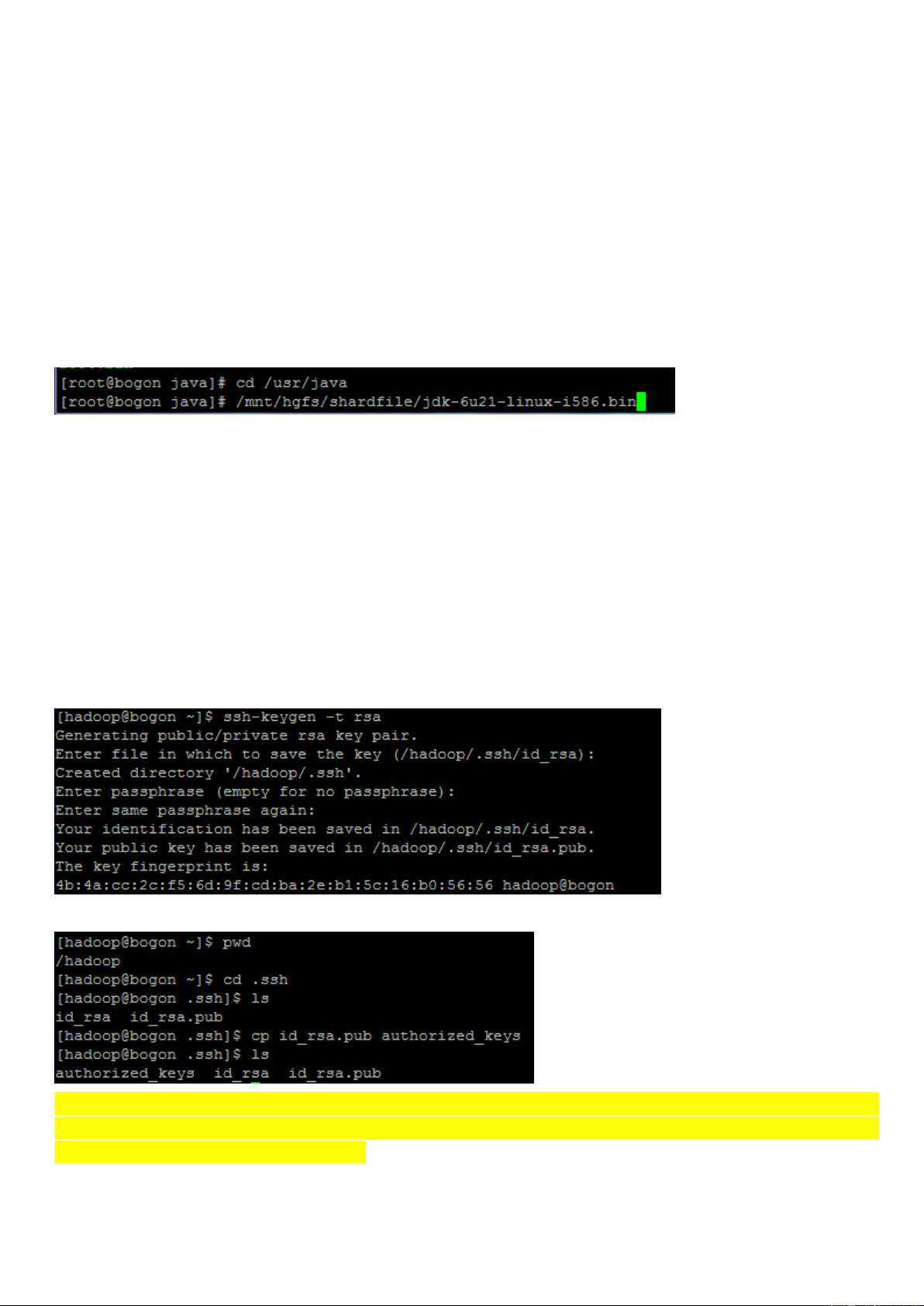
首先,安装前提是操作系统为CentOS5.5,并且需要预先安装JDK。下载并安装JDK的Linux版本,例如`jdk-6u21-linux-i586.bin`,然后将其解压至 `/usr/java` 目录下。接着,为了安全性和管理便捷性,创建名为`hadoop`的用户组和用户,分配相应的权限。
在分布式部署中,SSH无密码登录是必需的。教程中提到,通过`ssh-keygen`命令生成RSA密钥对,将所有节点的`~/.ssh/id_rsa.pub`(公钥)内容合并到每个节点的`~/.ssh/authorized_keys`文件中。这样,节点间可以无需密码进行SSH连接。如果遇到无法连接的问题,可以检查SSH服务是否已启动,可以通过`/etc/init.d/sshd restart`命令重启SSH服务。
接下来是Hadoop的安装和配置。教程指导我们解压Hadoop的二进制包,如`hadoop-0.20.2`,并配置相关环境变量。在`hadoop-env.sh`文件中,设置HADOOP_HOME以及Java路径。核心配置文件`core-site.xml`中,`fs.default.name`属性指定了HDFS的默认名称节点地址,这里设置为`hdfs://localhost:9000`。
HDFS的配置在`hdfs-site.xml`中,`dfs.data.dir`定义了数据块的存储位置,`dfs.replication`则设置了副本因子,因为是伪分布式,一般设置为1。而在`mapred-site.xml`中,`mapred.job.tracker`配置了作业调度器的位置,同样设置为`localhost:9001`。
最后,格式化分布式文件系统(HDFS)是启动Hadoop前的重要步骤,这会清除HDFS上的所有数据,因此在生产环境中应谨慎操作。通过执行`hadoop namenode -format`命令来完成格式化。
这份教程详细指导了如何在单个系统上搭建Hadoop伪分布式环境,这对于学习和测试Hadoop功能非常有用。通过这个过程,用户可以熟悉Hadoop的基本配置和操作,为实际的分布式部署打下基础。
一、 Hadoop 安装(伪分布式)
说明:操作系统 CentOS5.5
1. JDK 安装
下载: jdk-6u21-linux-i586.bin
mkdir /usr/java
2. 创建 hadoop 用户
groupadd hadoop
useradd -d /hadoop -g hadoop -m hadoop
设置 hadoop 用户密码: passwd hadoop
3. 生成 SSH 秘钥对
su – hadoop
ssh-keygen -t rsa
cp id_rsa.pub authorized_keys
分布式部署,必须把各个节点的 authorized_keys 的内容互相拷贝加入到对方的此文件中,然后就可以免密码彼此 ssh
连入,具体用文件 cat 操作,所有节点的 authorized_keys,即包含了各自节点生成的 rsa.pub(authorized_keys)内容
合并一个 authorized_keys 后拷贝到所有节点
下载后可阅读完整内容,剩余5页未读,立即下载
2021-04-29 上传
2024-07-16 上传
2021-10-14 上传
2018-11-07 上传
2021-08-15 上传
2019-06-18 上传
2021-06-22 上传
2020-08-18 上传
2020-12-20 上传

豫州刺史
- 粉丝: 206
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
