NANYA Technology DDR2-1GB SDRAM规格介绍
需积分: 11 16 浏览量
更新于2024-07-25
收藏 2.8MB PDF 举报
NT5TU64M16DG.pdf文件主要介绍了1GB(1 Gb) DDR2双数据速率(Double-Data-Rate 2,简称DDR2)动态随机存取内存(DRAM)模块。这种高速CMOS DRAM包含1,073,741,824位,内部配置为八银行结构。它具有多种规格,包括不同频率和 CAS latency(列地址有效时间)、RAS(Row Address Strobe,行地址使能)时间和RP(RAS Precharge,行预充电)时间,以支持不同的工作模式。
DDR2-533、DDR2-667、DDR2-800以及DDR2-1066等频率选项,分别对应着不同的时序参数,如tRCD(列地址到数据传输时间)、tRP(行预充电时间)、tRC(行刷新时间)和tRAS(行有效时间)。这些时序参数对于确保内存性能稳定、降低功耗和提高系统效率至关重要。例如,随着时钟频率的提升,时序值可能会有所减少,以适应更高的数据传输速度。
文件还提到,内存模块支持从CL(Cas Latency)3到CL7的不同级别,这意味着在不同CAS延迟下,平均时钟周期(tCK)也有相应的调整。此外,这款内存供电电压为1.8V±0.1V,且具有可编程性,允许根据系统需求进行配置。
NT5TU64M16DG系列还包括NT5TU256M4DE和NT5TU128M8DE,这些都是相同类型的内存,但容量不同,分别提供256MB和128MB。该系列产品的设计目标是满足消费者级应用,更新日期为2009年11月,由纳尼亚科技公司(Nanya Technology Corp.)制造并保留所有权利,声明产品规格可能随时变更而无需通知。
NT5TU64M16DG是一款高性能的DDR2内存,适用于需要高速数据传输和低延迟的计算机系统,其特性决定了它在现代计算机架构中的关键角色。理解这些参数对于优化内存子系统的性能和稳定性至关重要。
NT5TU256M4DE / NT5TU128M8DE / NT5TU64M16DG
1Gb DDR2 SDRAM
15
REV 1.8 CONSUMER DRAM
Nov / 2009 © NANYA TECHNOLOGY CORP. All rights reserved
NANYA TECHNOLOGY CORP. reserves the right to change Products and Specifications without notice.
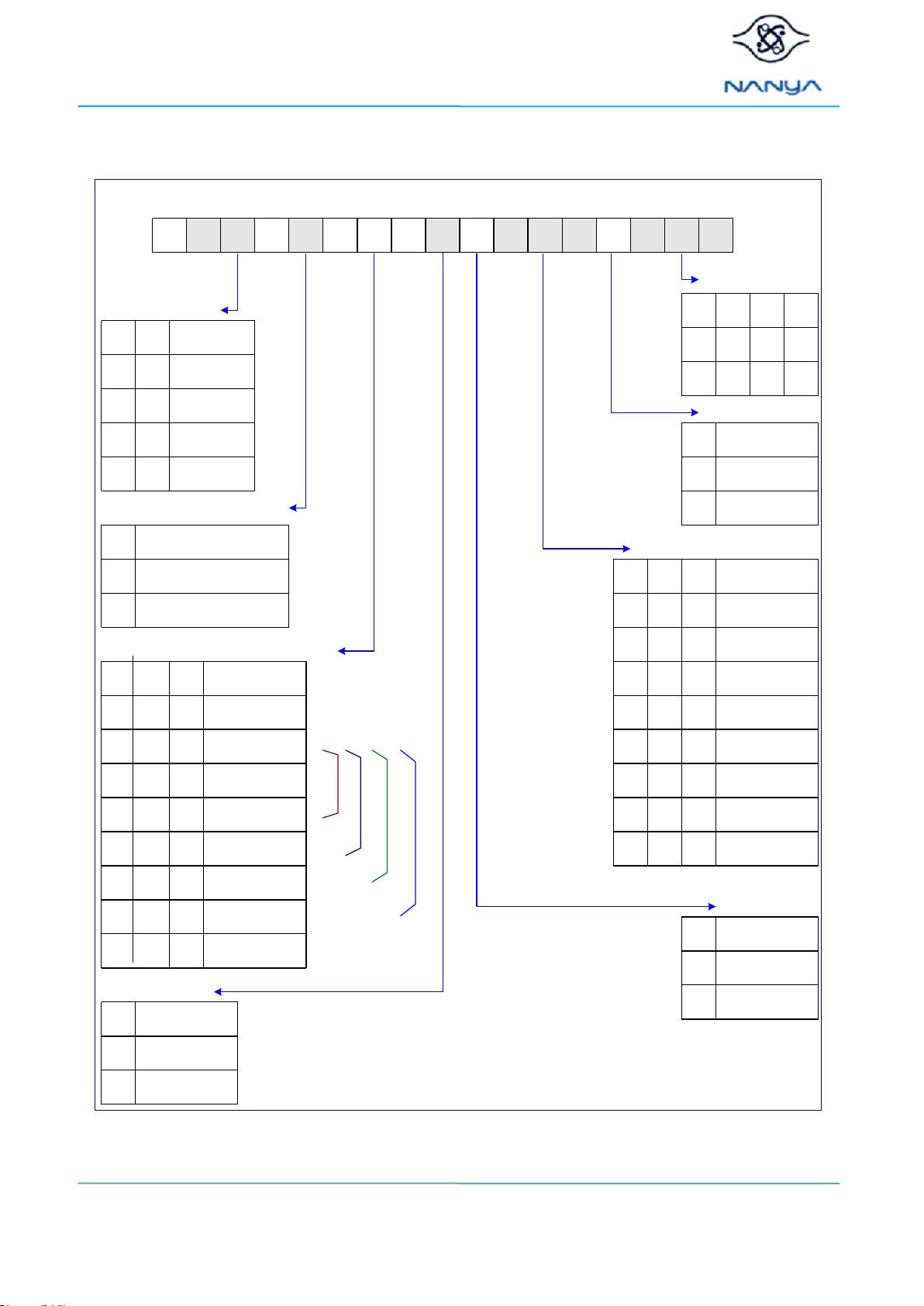
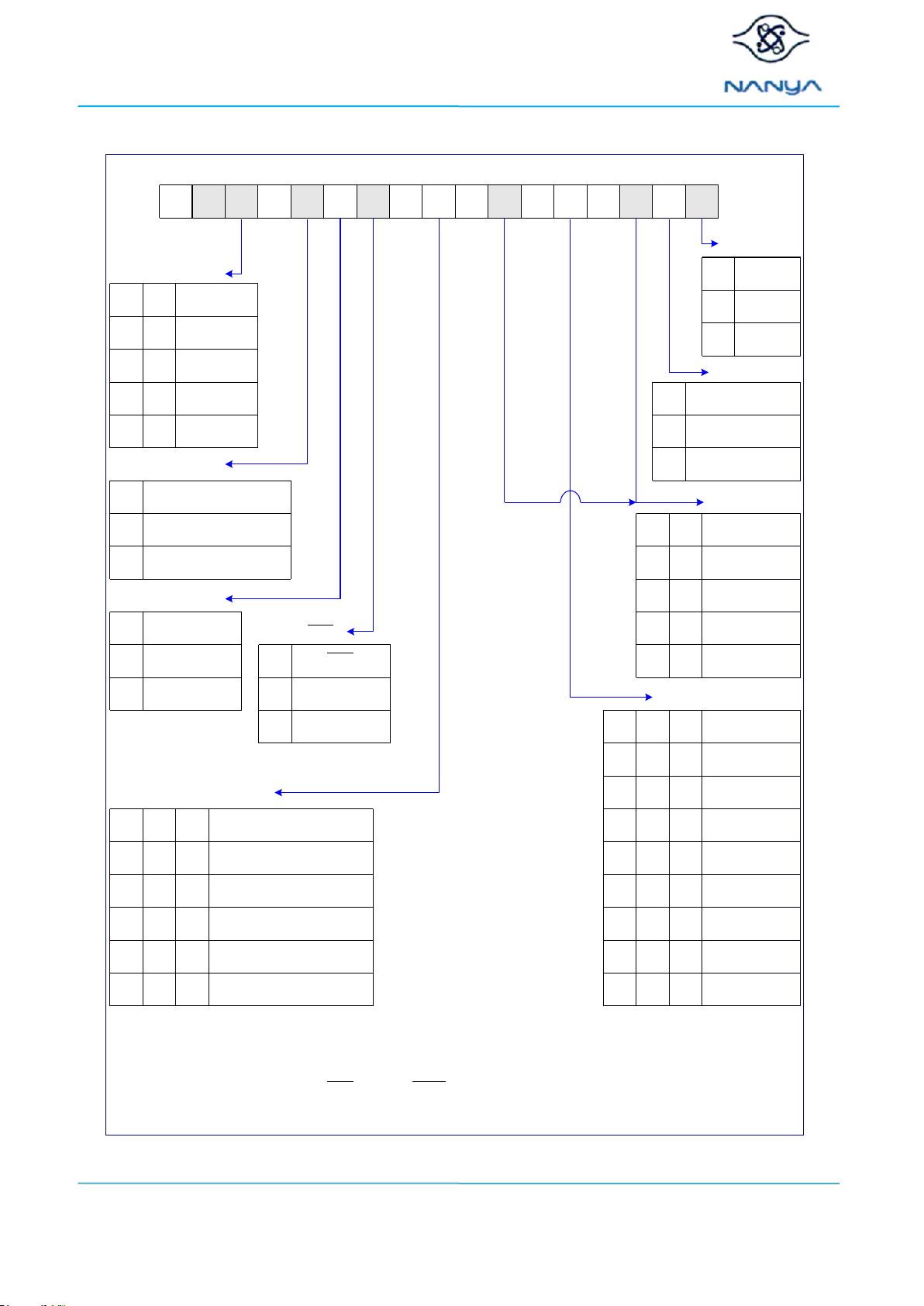
MRS Mode Register Operation Table (Address Input for Mode Set)
A0A1A2A3A4A5A6A7A8A9A10A11A12A13BA0BA1BA2
Address Field
BLA0A1A2
4010
8110
Burst Length
Burst TypeA3
Sequential0
Interleave
1
Burst Type
CAS LatencyA4A5A6
Reserved000
Reserved100
/CAS Latency
010
110
001
101
011
111
6
Reserved
7
MRS mode
BA0BA1
MR
00
EMR(1)
10
MRS mode
01
11
EMR(3)
EMR(2)
Active power down
exit time
A12
Fast exit (use tXARD)0
Slow exit (use tXARDS)
1
Active power down exit
time
* *
WR(cycles)A9A10A11
Reserved000
2100
Write recovery for autoprecharge
010
110
001
101
011
111
4
5
6
7
3
DLL ResetA8
NO0
YES
1
DLL Reset
ModeA7
Normal0
TEST
1
Mode
* BA2 and A13 are reserved for future use and must be set to
"0" when programming MR.
3
4
5
DDR2-1066
DDR2-667
DDR2-800
DDR2-533
Reserved


剩余86页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-07-11 上传
2019-10-15 上传
2020-01-14 上传
2021-02-16 上传
2021-07-09 上传

Kuakan
- 粉丝: 0
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
