编码解码原理与乱码解决之道
104 浏览量
更新于2024-08-29
收藏 123KB PDF 举报
本文将深入探讨编码、解码和乱码问题在编程过程中的重要性,特别是针对中文字符处理。首先,编码是指将文本中的字符转换成二进制码流的过程,如将汉字'郭'转换成特定的内码,而解码则是逆过程,即将二进制码流还原回字符。在这个过程中,涉及到三个关键概念:
1. 字符:这是我们在屏幕上看到的文字,例如字母、数字和符号,是人类可读的符号,但在计算机中,这些字符实际上是通过特定的内码进行存储和传输的。
2. 内码:内码是字符在计算机内部的存储形式,用于存储和处理字符的二进制表示。例如,ASCII码是英文字符的标准内码,但为了容纳汉字等多字节字符,中国有自己的编码体系,如国标码、GBK和GB18030,它们是单字节或双字节编码,其中国标码是早期版本,而汉字机内码(汉字内码)才是实际的存储形式。
3. 字符集:字符集是内码在内存中的具体实现方式,它决定了如何将字符的内码映射到实际的字符。ASCII字符集对应英文字符,而Unicode则涵盖了全球各种文字,包括但不限于英文、中文、日文等。常用的Unicode编码如UTF-8、GBK和GB18030,其中UTF-8是一种变长编码,能够高效地存储多种语言字符。
当处理不同编码的文本时,如果编码不匹配,就会出现乱码问题。例如,如果一个文本使用了UTF-8编码,而在程序中使用了GBK进行解码,可能会导致无法正确显示字符,因为UTF-8中的某些字符可能需要多个字节来表示,而GBK可能无法正确处理。解决乱码问题通常需要明确输入和输出的字符编码,确保数据在处理过程中保持一致。
总结来说,理解编码、内码和字符集的关系以及它们在编程中的应用是解决编码和解码问题的关键。同时,随着全球化的趋势,处理多语言字符集的兼容性和适配性变得越来越重要。开发者在实践中应该熟练掌握各种编码标准,以避免常见的乱码困扰。
浅谈编码浅谈编码,解码解码,乱码的问题乱码的问题
在开发的过程中,我们不可避免的会遇到各种各样的编码,解码,或者乱码问题,很多时候,我们可以正常的解决问题,但是
说实在的,我们有可能并不清楚问题到底是怎么被解决的,秉承知其然,更要知其所以然的理念,经过一番研究,就有了下面
的这篇文章,鉴于本人功力尚浅,有错误请给予纠正
编码解码核心编码解码核心
简单的来说,编码是从一个字符,比如‘郭’,到一段二进制码流的过程。解码是从一段二进制码流到一个字符的过程。
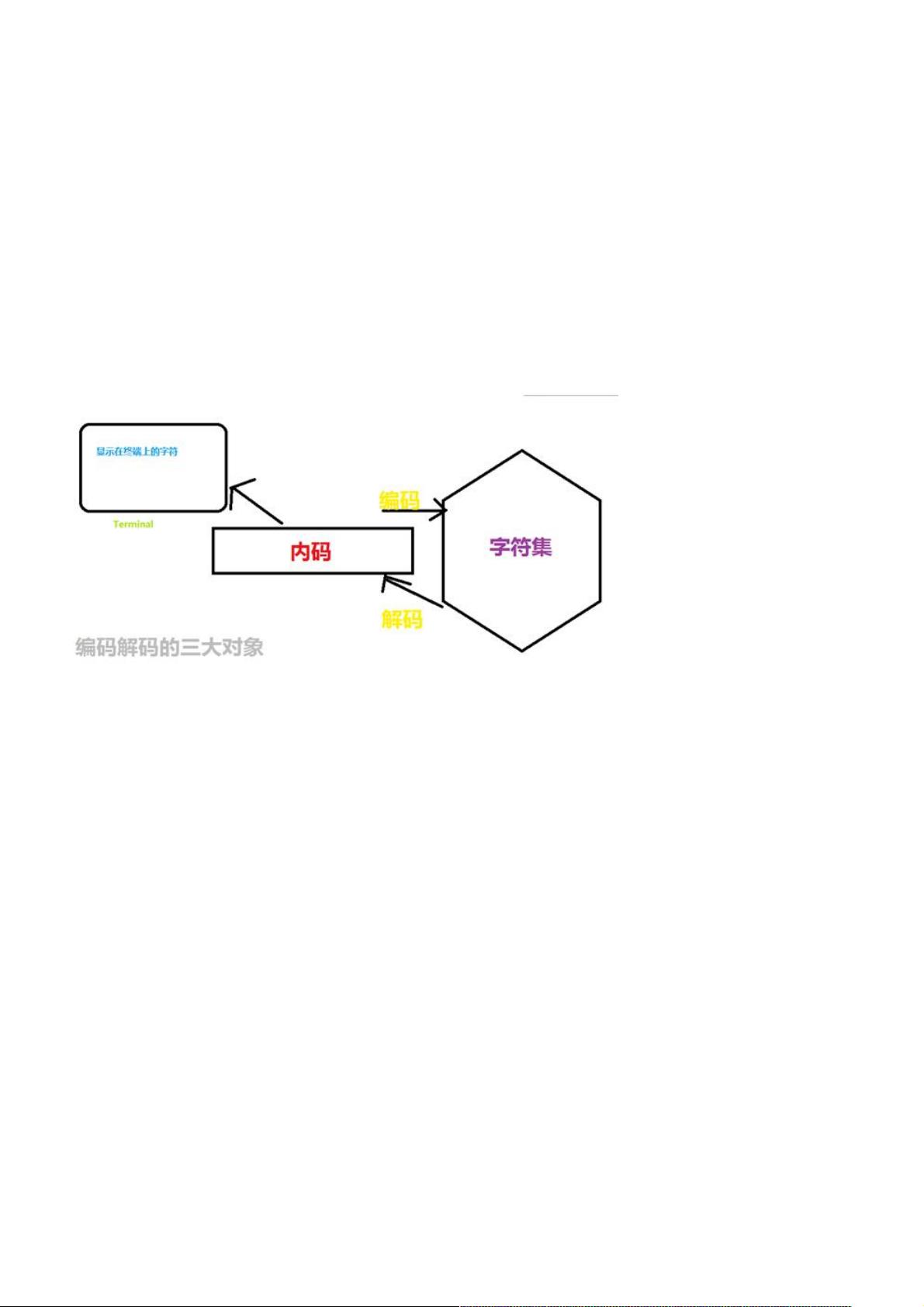
但是,就计算机工作原理而言,这其中涉及到了三个对象。
•字符字符 (我们在各种终端上面看得到的显示结果)(我们在各种终端上面看得到的显示结果)
•内码内码 (对应显示的字符的计算机存储数据)(对应显示的字符的计算机存储数据)
•字符集字符集 (内码在内存中的具体实现)(内码在内存中的具体实现)
这三者之间的配合如下图。这三者之间的配合如下图。
字符字符
对于字符而言,是我们程序员而言想必是最熟悉的了吧。什么Abs_=+/.80,都是我们所熟悉使用的字符。虽然我们表面上看
到的是一个个的字符,但是在计算机而言,其真正识别和处理的不过是对应于显示的字符的一个个的内码。
内码内码
内码是汉字在计算机内部存储,处理和传输用的信息编码。它必须与ASCII码兼容但又不能冲突。
也许你会想,ASCII码又是什么? 对此,百度百科是这样解释的:
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系
统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
从这里我们不禁会想,既然是单字节编码,那么汉字这种多字节表示的信息又是怎么被计算机识别和处理的呢?
国标码规定:一个汉字用两个字节来表示,每个字节只用前七位,最高位均未作定义。但我们要注意,国标码不同于ASCII
码,并非汉字在计算机内的真正表示代码,它仅仅是一种编码方案,计算机内部汉字的代码叫做汉字机内码,简称汉字内码。
所以,这也是国人在平时开发过程中经常会遇到的 乱码问题的根源。乱码问题的根源。
字符集字符集
字符集作为内码在内存中的具体实现,肩负着很大的责任。
•ascii不仅仅指英文对应的内码,还包括它的具体实现,也就是它的字符集。它是用一个字节存储每个内码的。
•unicode是所有文字(包括英文,中文,日文等)所对应的内码的集合。
unicode的实现方式比较多样,常用的有UTF-8,GBK,GB18030。
•其中,UTF-8是一种不定长的内码实现方式。
下载后可阅读完整内容,剩余4页未读,立即下载
2012-08-01 上传
2020-10-21 上传
2020-09-20 上传
2021-01-20 上传
2020-09-28 上传
2020-10-17 上传
2020-09-21 上传
2020-09-18 上传
2016-04-23 上传

weixin_38626943
- 粉丝: 5
- 资源: 935
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
