统计自然语言处理:HMM与词性标注详解
需积分: 3 106 浏览量
更新于2024-08-02
收藏 2.89MB PPT 举报
统计自然语言处理是一门研究如何利用统计方法来理解和生成人类语言的学科,其中关键概念之一是隐马尔可夫模型(Hidden Markov Model, HMM)。HMM是一种概率模型,用于建模那些通过一系列不可见状态产生观测序列的现象。在自然语言处理中,它常被用于词性标注、语音识别、机器翻译等任务。
**隐马尔可夫模型概述**
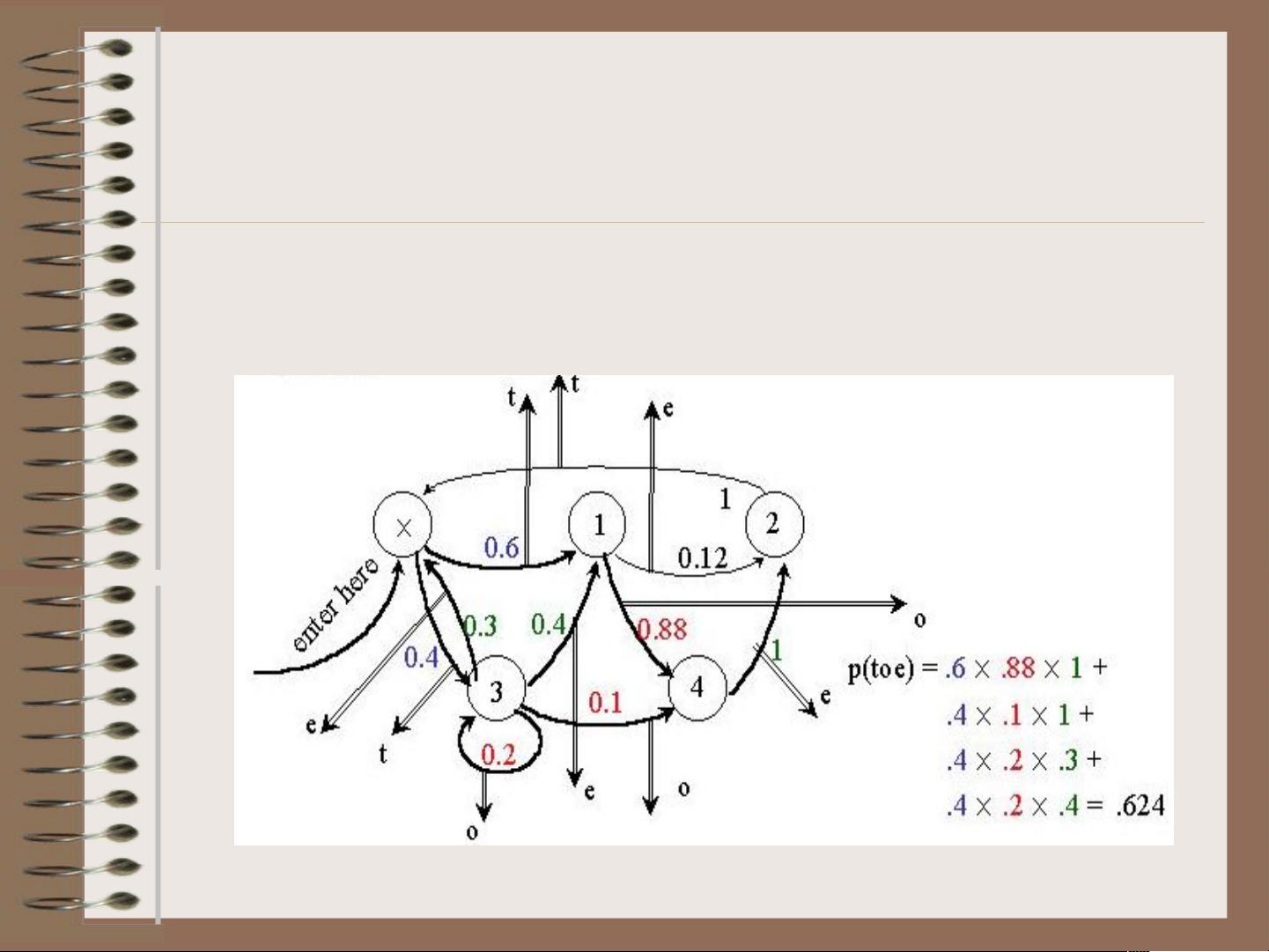
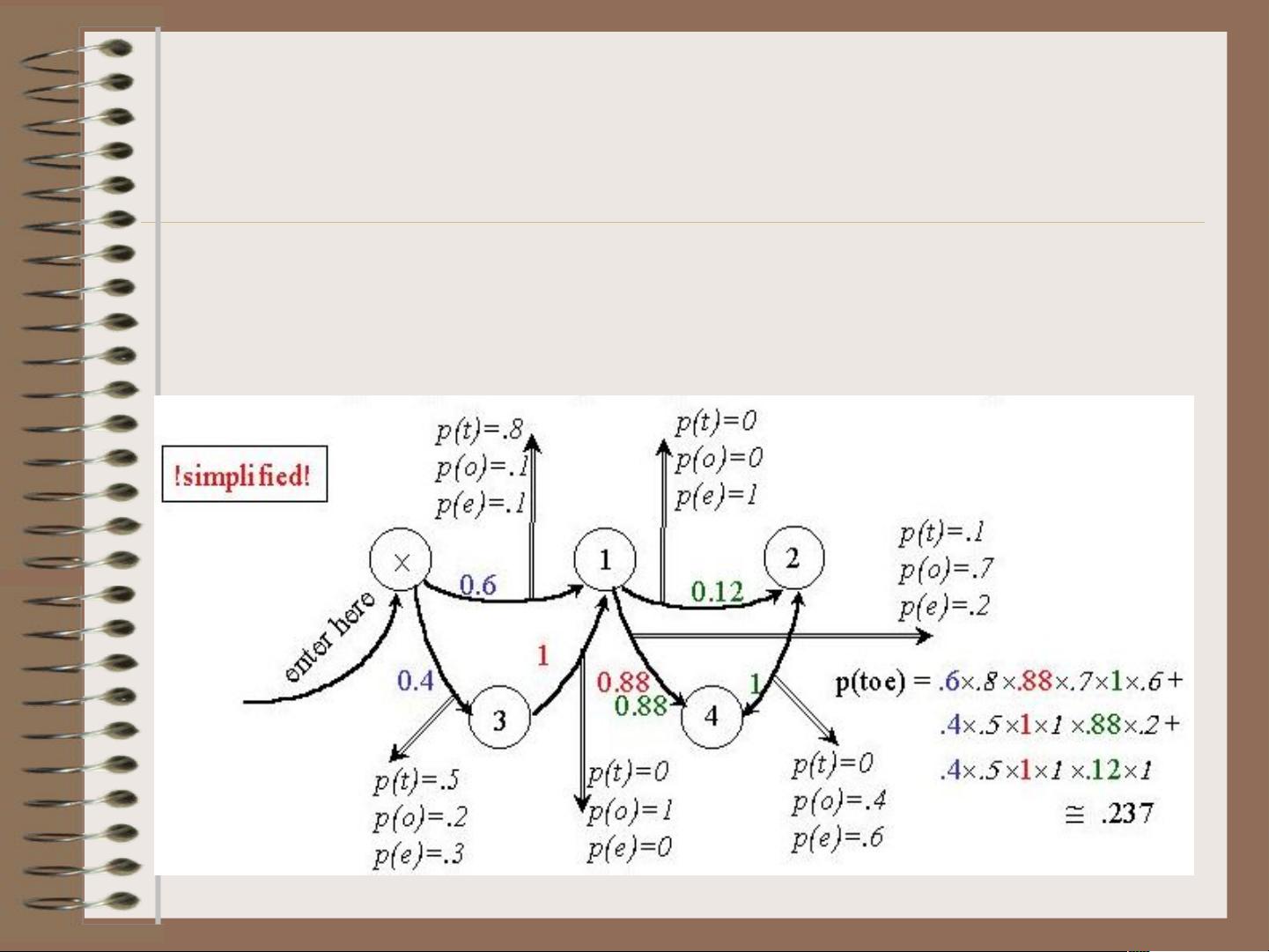
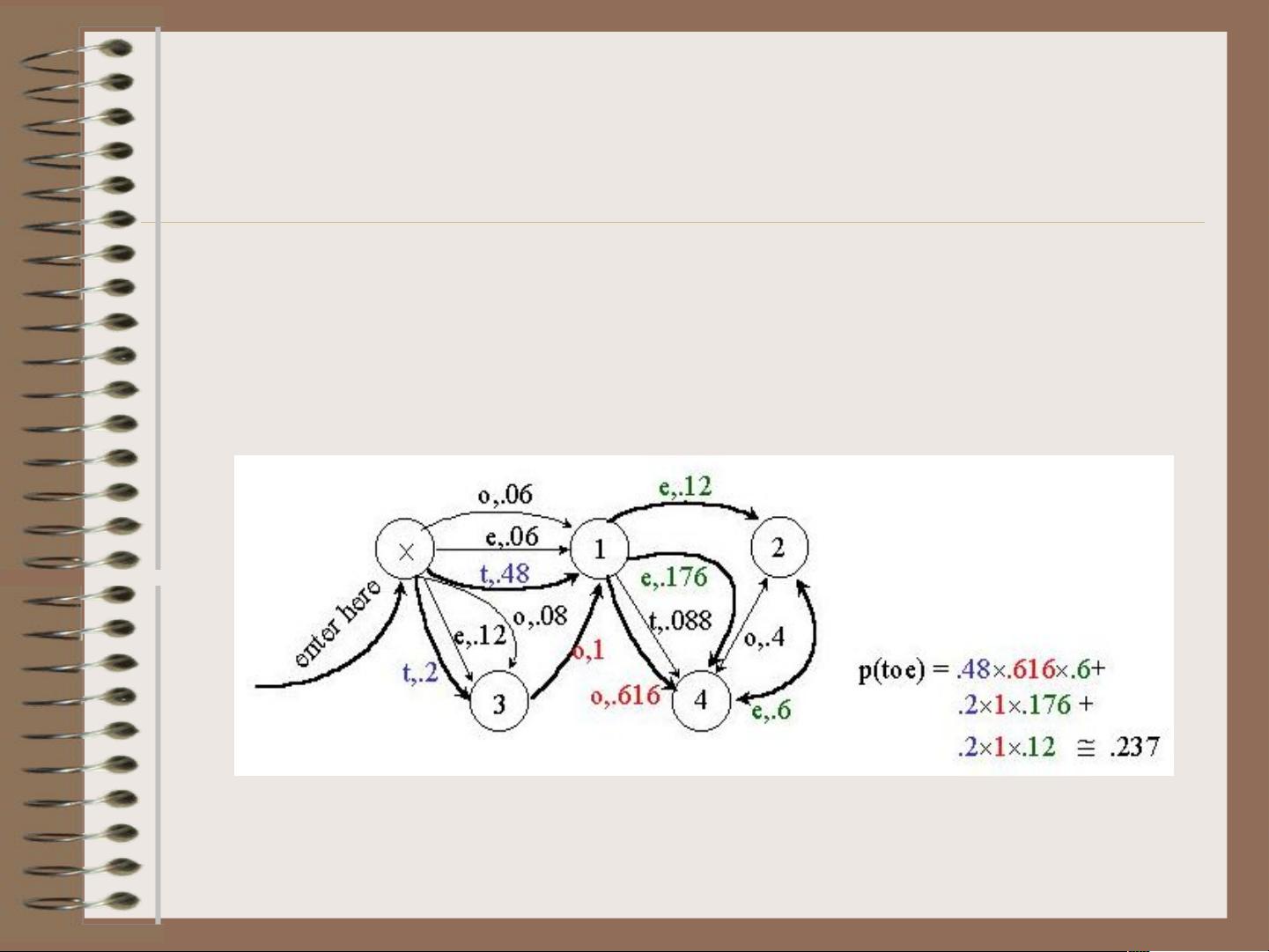
隐马尔可夫模型由五个基本元素组成:状态集S,初始状态S0,输出字母表Y,转移概率分布PS,和发射概率分布PY。状态集S由多个状态s1到sT组成,每个状态代表一种潜在的语言结构或特征;初始状态S0指明序列的起始状态;输出字母表Y定义了从一个状态到另一个状态可能产生的观测结果;转移概率aij给出了从状态sj转移到状态si的概率,形成状态间的转移关系;发射概率bijk则定义了在状态si下产生观测符号yk的概率。
**任务1:计算观察序列的概率**
给定一个训练好的HMM模型,计算观察序列Y={y1,y2,…,yk}的概率是关键任务。这个过程利用转移概率和发射概率来衡量整个序列发生的可能性,这对于构建语言模型和文本分类至关重要。例如,在文本分析中,可以将词转换为类别,从而降低因词汇量大导致的数据稀疏问题。
**任务2:最大概率状态序列**
此任务涉及寻找能够解释观察序列的最可能状态序列。通过动态规划算法(如维特比算法),可以找到最可能的状态路径,即一个状态序列,使得其产生的观测序列概率最大。
**马尔可夫链与有限状态自动机**
马尔可夫链是HMM的基础,描述了系统从一个状态到另一个状态的随机转移。有限状态自动机则强调状态间的转移和输出,但通常为可见状态模型(Visible Markov Model, VMM),而HMM则是隐含状态模型,输出直接关联到观察序列。
**词性标注**
词性标注是自然语言处理中的一个具体应用,利用HMM来确定一个单词在句子中的语法角色,如名词、动词等。通过学习词汇在不同上下文中的词性分布,模型可以预测给定单词的词性,帮助解析句子结构。
总结来说,统计自然语言处理中的隐马尔科夫模型提供了一种强大的框架,用于理解和生成语言模式。理解这些基本概念有助于深入研究和开发各种自然语言处理技术,如文本分类、语音识别、机器翻译和语言模型等。通过学习HMM的原理和应用,开发者可以构建更高效和准确的自然语言处理系统。
2021-10-05 上传
2021-10-01 上传
2023-05-09 上传
2023-07-01 上传
2023-08-04 上传
2023-08-03 上传
2023-10-19 上传
2024-10-26 上传

anyupu
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
