"深入解析Transformer多头注意力机制原理(上卷):剖析解决问题的思路"
Transformer详解
Transformer是一种深度学习模型架构,最初由谷歌提出,并在NLP领域取得了巨大成功。它的成功主要得益于其创新的注意力机制,以及并行的计算结构。本文将对Transformer的原理进行详细分析,帮助读者全面理解这一模型。
在本文的第一部分,我们以多头注意力机制为切入点,从动机、原理和应用角度逐层分解Transformer模型。在理解多头注意力机制的基础上,我们将深入讨论Transformer模型的工作原理,揭示其在解决自然语言处理问题上的优势。
首先,我们将探讨动机,即为什么需要多头注意力机制。在自然语言处理领域,传统的循环神经网络和卷积神经网络在建模长距离依赖时存在一定局限性。多头注意力机制通过对输入序列进行并行的加权平均,可以更好地捕捉长距离依赖关系,从而提高模型的效果。
接下来,我们将详细解释多头注意力机制的原理,包括注意力分布的计算方法、注意力矩阵的构建以及多头注意力的合并方式。通过具体的数学推导和图示,读者将能够清晰地理解注意力机制是如何在Transformer中工作的。
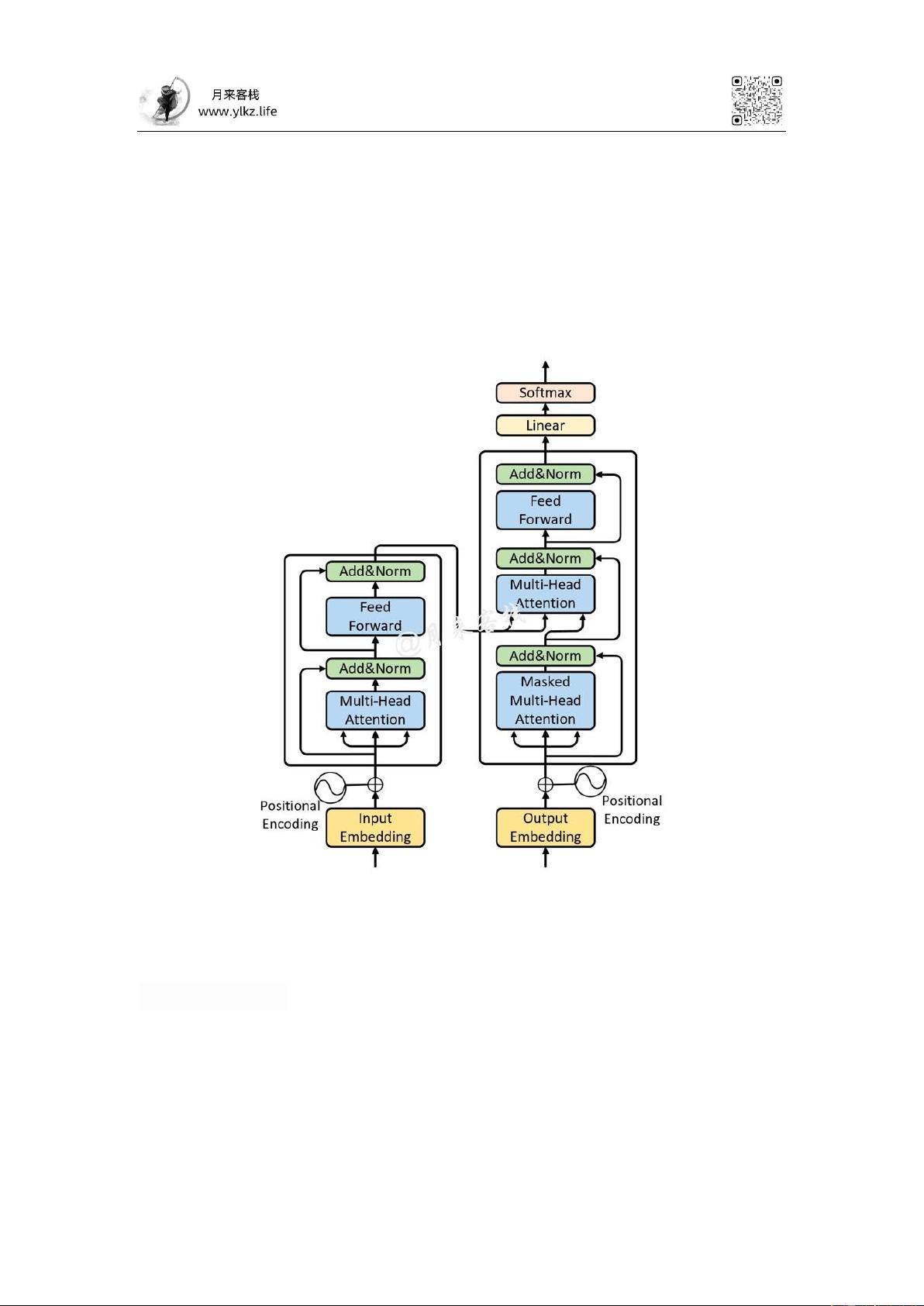
随后,我们将阐述多头注意力机制在Transformer模型中的应用。Transformer模型通过多层堆叠注意力机制和前馈神经网络来组成,从而实现对输入序列的建模。我们将解释Transformer模型的网络结构,以及其在机器翻译、文本生成等任务中的应用效果。
在第二部分中,我们将深入剖析Transformer模型的构成要素:自注意力机制和位置编码。自注意力机制是Transformer模型的核心,它能够使模型在不同位置之间建立起长距离的依赖关系。我们将详细介绍自注意力机制的计算过程和数学原理,使读者能够深入理解该机制的工作方式。
此外,我们还将解释位置编码在Transformer模型中的重要性。由于Transformer模型丢弃了序列的顺序信息,需要通过位置编码来为输入序列引入位置信息。我们将介绍位置编码的设计思路和实现方法,帮助读者理解如何将位置信息融入到Transformer模型中。
最后,我们将以几个具体的案例来展示Transformer模型的应用效果。我们将以机器翻译、文本摘要等NLP任务为例,对比Transformer模型与传统模型的性能差异,从而展示Transformer模型在不同任务上的优势和实用性。
通过本文的阅读,读者将能够全面、深入地了解Transformer模型的工作原理和应用方法。我们希望本文能够帮助更多的读者掌握Transformer模型,从而在NLP领域取得更好的成绩。

12
第 2 节 位置编码与编码解码过程
2.1 Embedding 机制
在正式介绍 Transformer 的网络结构之前,我们先来一起看看 Transformer 如
何对字符进行 Embedding 处理。
2.1.1 Token Embedding
熟悉文本处理的读者可能都知道,在对文本相关的数据进行建模时首先要做
的便是对其进行向量化。例如在机器学习中,常见的文本表示方法有 one-hot 编
码、词袋模型以及 TF-IDF 等。不过在深度学习中,更常见的做法便是将各个词
(或者字)通过一个 Embedding 层映射到低维稠密的向量空间。因此,在
Transformer 模型中,首先第一步要做的同样是将文本以这样的方式进行向量化
表示,并且将其称之为 Token Embedding,也就是深度学习中常说的词嵌入(Word
Embedding)如图 2-1 所示。
图 2-1. Token Embedding
如果是换做之前的网络模型,例如 CNN 或 RNN,那么对于文本向量化的步
骤就到此结束了,因为这些网络结构本身已经具备了捕捉时序特征的能力,不管
是 CNN 中的 n-gram 形式还是 RNN 中的时序形式。但是这对仅仅只有自注意力
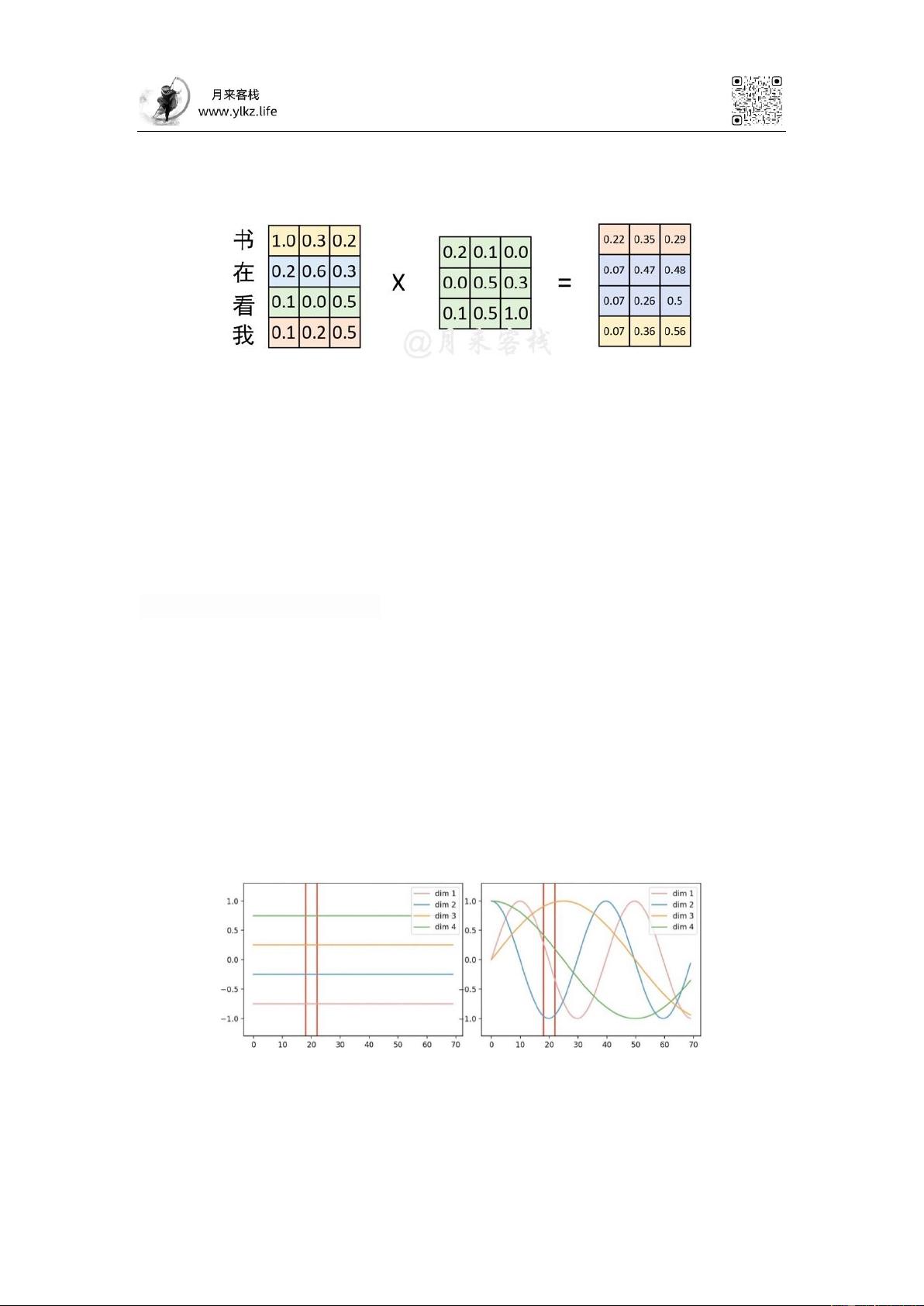
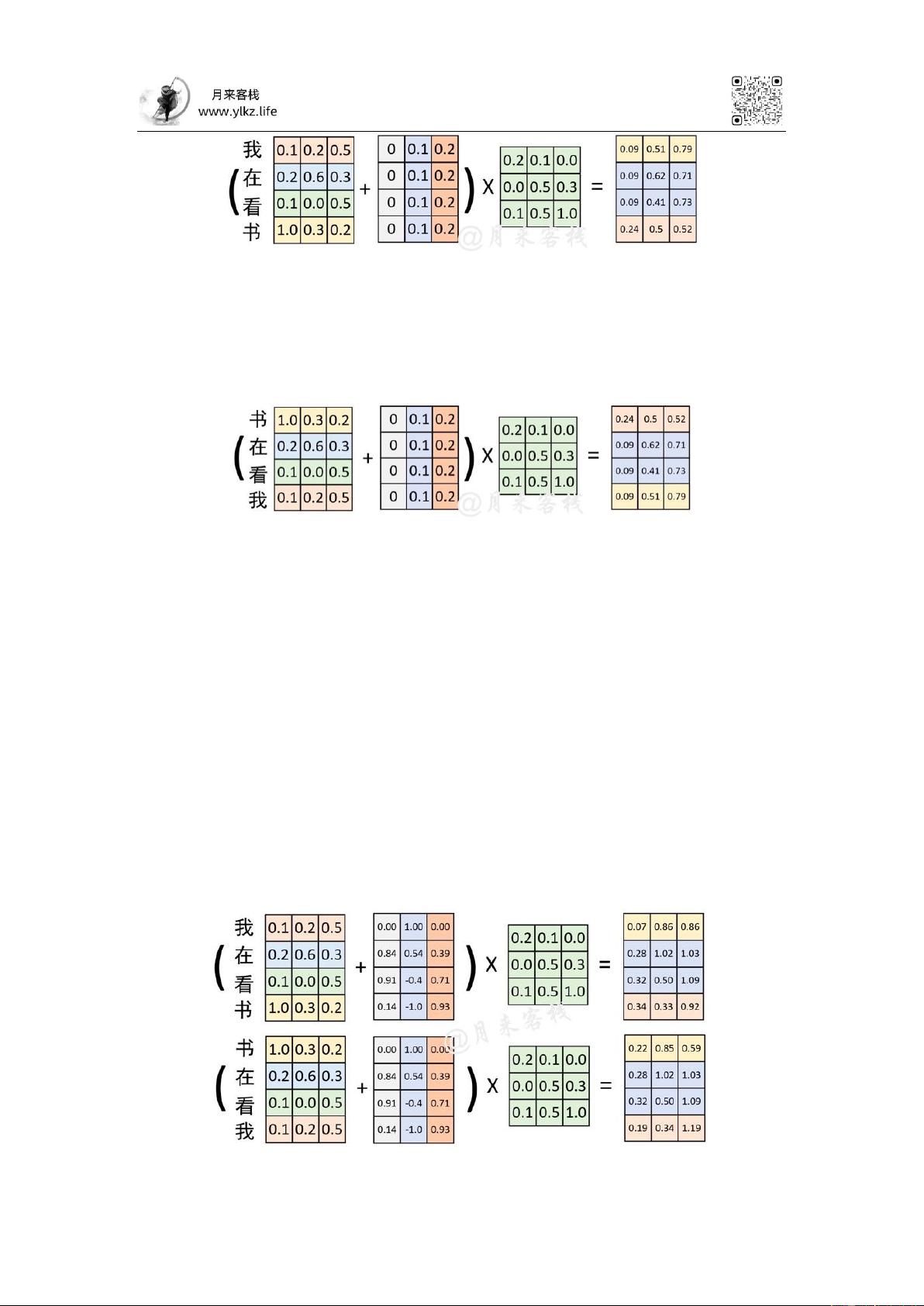
机制的网络结构来说却不行。为什么呢?根据自注意力机制原理的介绍我们知道,
自注意力机制在实际运算过程中不过就是几个矩阵来回相乘进行线性变换而已。
因此,这就导致即使是打乱各个词的顺序,那么最终计算得到的结果本质上却没
有发生任何变换,换句话说仅仅只使用自注意力机制会丢失文本原有的序列信息。
图 2-2. 自注意力机制弊端图(一)
剩余94页未读,继续阅读
131 浏览量
188 浏览量
2215 浏览量
150 浏览量
218 浏览量
121 浏览量

锦鲤少年丶
- 粉丝: 222
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
