端到端Transformer对象检测网络TOD-Net
PDF格式 | 6.45MB |
更新于2024-08-03
| 192 浏览量 | 举报
"这篇SCI论文介绍了TOD-Net,一个基于Transformer的端到端目标检测网络,由印度VIT-AP大学的研究人员Museboyina Sirisha和S.V. Sudha提出。该网络旨在利用Transformer架构捕捉语义信息和多尺度特征,以实现更优秀的目标显著性。"
在当前深度学习领域,人工智能技术的发展促进了目标检测算法的不断进步。TOD-Net(Transformer-based Object Detection network)是一个创新性的模型,它融合了Transformer的强大力量来处理视觉任务。Transformer最初被引入到自然语言处理(NLP)中,因其在序列数据中的并行计算能力和长距离依赖关系建模的优势而备受瞩目。然而,近年来,Transformer的架构逐渐被应用于计算机视觉领域,尤其是在目标检测中显示出巨大潜力。
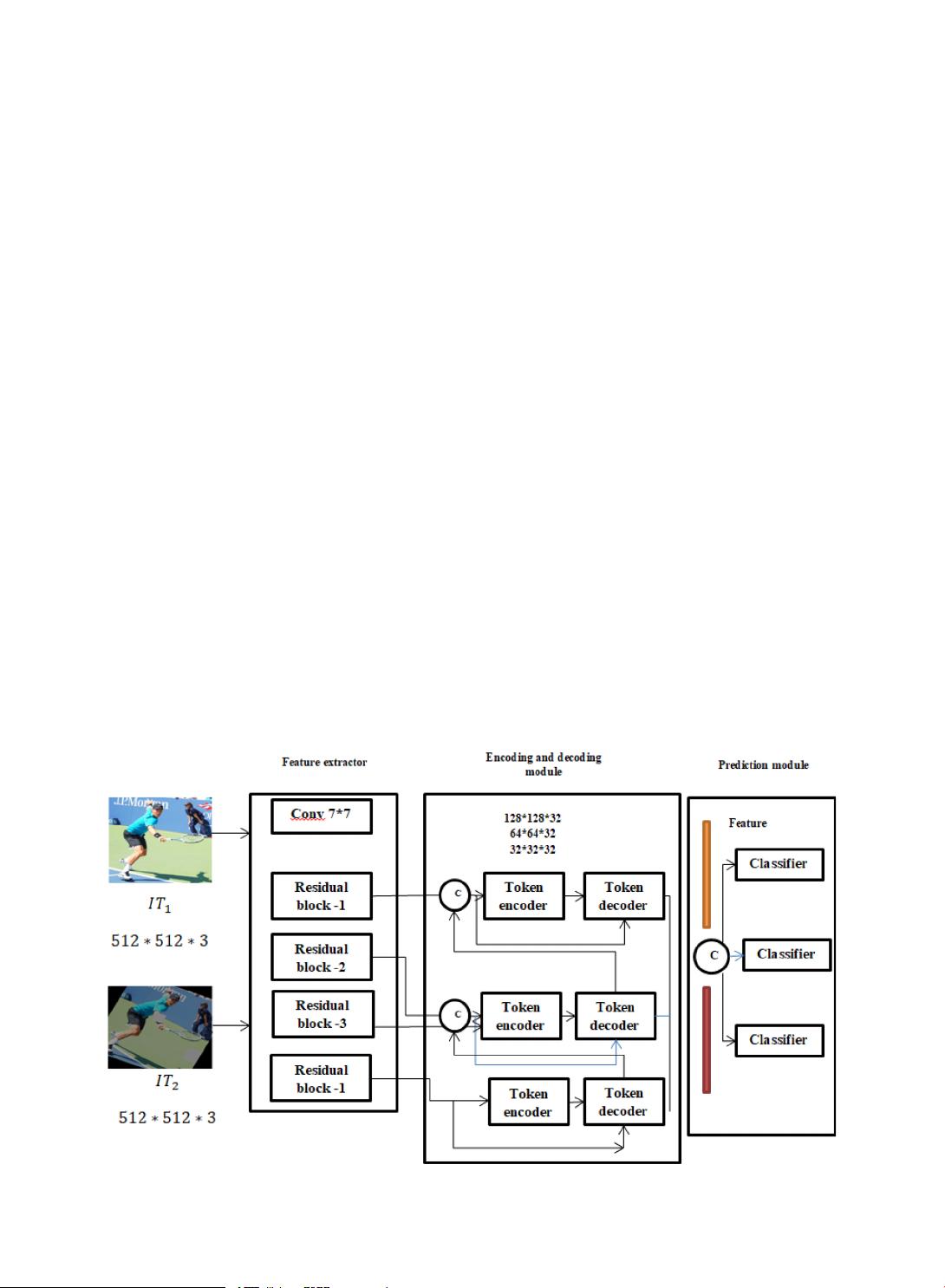
TOD-Net由三个主要部分构成:编码器、解码器和Transformer及预测模块。编码器负责从输入图像中提取特征,这些特征通常包含了多层次的信息,能够捕获图像的细节和全局结构。解码器则用于恢复这些特征,使得网络能够精确地定位和识别目标。Transformer模块是TOD-Net的核心,它通过自注意力机制,允许网络在不同位置之间建立联系,有效地处理空间信息并进行上下文建模。
预测模块作为编码器和Transformer之间的桥梁,其作用在于将编码器获取的局部特征与Transformer的全局上下文信息融合,从而提高目标定位和分类的准确性。这一设计考虑了目标检测中的尺度问题,使得网络能够处理大小不一的目标,并在复杂场景中保持良好的性能。
关键词如“特征表示”和“语义分析”强调了TOD-Net在理解图像内容上的深度。特征分析是检测过程的关键,通过学习和提取具有区分性的特征,网络可以识别出图像中的各个目标。语义分析则涉及到对图像内容的高级理解,这有助于网络在复杂的背景中分离和识别目标。
此外,“本地特征”和“缩放”表明TOD-Net处理了多尺度信息,这对于目标检测尤其重要,因为目标在图像中的大小可能会有很大变化。通过有效地结合不同尺度的特征,TOD-Net能够适应各种目标尺寸,提高了检测的鲁棒性。
总结起来,TOD-Net是一个以Transformer为基础的端到端目标检测框架,它通过创新的架构设计,成功地将Transformer的优势应用到计算机视觉任务中,特别是在理解和处理图像的语义信息和多尺度特征方面表现出色。这一研究为未来的目标检测算法提供了新的思路,有望推动相关领域的进一步发展。
Computers and Electrical Engineering 108 (2023) 108695
3
Natural language processing has actively studied attention mechanisms as essential elements for neural networks. In recent years,
attention mechanisms in computer vision have been applied to various elds to enhance performance by highlighting regions of in-
terest in images and detecting long-range dependencies. Segmentation, generation of images, and classication of images are some of
the applications of computer vision using them. Previous studies have proven that attention mechanisms can improve object detection
performance by locating and recognizing objects in images. In addition, a MAD unit is suggested in [29] to identify the activation of the
neuron in the lower and higher streams via the aggressive search. A new structure couplenet is suggested, which combines the local and
global information related to objects to improve detection performance. Recent improvements have been made in the accuracy of
object detection methods using transformers.
The attention-based NLP models’ success has inspired a recent initiative to integrate transformers into CNNs. The ViT Vision
Transformer is a pure transformer used to classify the images. The 2D image is reshaped into attened patches to handle it. The
transformer attens the patches and maps them to dimensions using a trainable linear projection using constant latent vector sizes
across all its layers. The results obtained when trained on large datasets prove that the transformers efciently extract features of an
image. Video Vision Transformer (ViViT) is proposed for the classication of videos. A sequence of spatiotemporal tokens extracted
from the video input is used in this architecture as the primary method of computation for self-attention. Several methods are applied
to factorize the model along spatial and temporal dimensions to increase efciency and scalability. The author suggested the Tran-
sUNet, which integrates the transformer’s encoder and the U-Net. Transformer encodes the tokenized image patches based on the CNN
feature map to detect global context initially and extract global context later. Decoding ensures that the encoded features are
upsampled, and the CNN feature maps are combined for precise localization. TransUNet leverages detailed, high-resolution geospatial
information and the global context by combining CNN features and transformers. In various medical applications, TransUNet out-
performs other competing methods [29].
Many methods based on U-Net related to detecting video anomaly utilize the successive stacked frames as input and the constraints
of motion like loss of optical ow to extract the temporal information. The structure is limited, and inadequate temporal information is
used to predict and reconstruct. Better performance is obtained by ViViT than other models for video classication using different
variants of the transformers [29]. Using the transformers, the model performs better, encoding both spatial and temporal features in
the videos. Furthermore, the U-Net is widely used for detecting video anomalies. In addition, the potential integration of the U-Net and
the transformer is mentioned by the TransUNet. The model inspires us to modify the encoder of the transformer in the proposed system
to make reliable predictions in the video. The model encodes spatial data, while the suggested encoder of the transformer encodes the
temporal data. The model performs better than the baseline model based on prediction without the transformer module. However, the
performance is comparatively lesser and triggers the need for a novel approach. This research intends to solve the complexity of the
existing approaches by proposing a transformer-based network framework for object detection (TOD − Net).
3. Methodology
The backbone of the proposed network uses TOD − Net as the feature extractor that is modied by taking the existing ResNet-18 and
removing the primary fully connected layer. Hence, the feature extractor has a convolution layer of 7 × 7 and four residual blocks
Fig 1. Overview of TOD − Net.
M. Sirisha and S.V. Sudha
剩余11页未读,继续阅读
相关推荐




DrYJ
- 粉丝: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaWeb中Servlet、Jsp与JDBC技术
- 粒子滤波在视频目标跟踪中的应用与MATLAB实现
- ISTQB ISEB基础级认证考试BH0-010题库解析
- 深入探讨HTML技术在hundeakademie中的应用
- Delphi实现EXE/DLL文件PE头修改技术
- 光线追踪:探索反射与折射模型的奥秘
- 构建http接口以返回json格式,使用SpringMVC+MyBatis+Oracle
- 文件驱动程序示例:实现缓存区读写操作
- JavaScript顶盒技术开发与应用
- 掌握PLSQL: 从语法到数据库对象的全面解析
- MP4v2在iOS平台上的应用与编译指南
- 探索Chrome与Google Cardboard的WebGL基础VR实验
- Windows平台下的IOMeter性能测试工具使用指南
- 激光切割板材表面质量研究综述
- 西门子200编程电缆PPI驱动程序下载及使用指南
- Pablo的编程笔记与机器学习项目探索
