VMware上配置Hadoop多节点教程
版权申诉
82 浏览量
更新于2024-07-02
收藏 2.11MB DOC 举报
"VM下配置Hadoop详细教程"
在配置Hadoop环境时,我们需要了解Hadoop的基本构成和特性。Hadoop是由三个主要组件组成的:HDFS(Hadoop Distributed File System)、MapReduce以及HBase。HDFS是分布式文件系统,模仿了Google的GFS,能够提供高容错性和高吞吐量的数据存储;MapReduce则是处理大数据的计算框架,基于Google的MapReduce模型;而HBase是基于HDFS的分布式数据库,类似于Google的BigTable,用于存储非结构化和半结构化数据。
在VMware虚拟机中配置Hadoop,首先需要确保你拥有合适的软件工具。这些包括VMware Workstation、Ubuntu操作系统镜像、Hadoop的二进制包、Java Development Kit (JDK)以及一个用于检查CPU虚拟化技术的工具Securable。在Windows 7系统下,你将配置两台虚拟机,一台作为NameNode、master和jobTracker,另一台作为DataNode、slave和taskTracker。
在开始配置之前,你需要检查CPU是否支持Virtualization Technology(VT),这对于提高虚拟机性能至关重要。使用Securable工具可以查看CPU的VT状态,如果CPU支持VT,但未开启,你需要进入BIOS设置开启它。
接下来的步骤大致包括以下几个阶段:
1. 安装Ubuntu操作系统:使用VMware创建虚拟机,并安装Ubuntu。确保为每台虚拟机分配足够的内存和磁盘空间。
2. 配置网络:设置虚拟机的网络模式为NAT或桥接模式,确保它们可以互相通信。通过修改/etc/network/interfaces文件配置静态IP地址,例如,NameNode为192.168.137.2,DataNode为192.168.137.3。
3. 安装JDK:在每台虚拟机上安装JDK,因为Hadoop需要Java环境来运行。通常,你可以从Oracle官网下载适用于Linux的JDK,并按照官方文档进行安装。
4. 设置环境变量:配置JAVA_HOME、PATH和CLASSPATH等环境变量,使得Hadoop能够找到Java安装路径。
5. 安装Hadoop:将下载的Hadoop压缩包解压到适当目录,如/usr/local/hadoop。然后配置Hadoop的配置文件,如hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,根据你的环境设置HDFS和MapReduce的相关参数。
6. 初始化HDFS:在NameNode上执行格式化HDFS的命令,这会创建名称节点所需的元数据。
7. 启动Hadoop服务:启动DataNode和NameNode,以及其他相关服务如ResourceManager和NodeManager。你还需要启动secondary NameNode以提供名称节点的定期备份。
8. 测试集群:通过运行简单的WordCount示例来验证Hadoop集群是否正常工作。这将涉及编写一个MapReduce程序,将文件上传到HDFS,然后运行该程序。
9. 高可用性设置(可选):如果你需要更高的可用性,可以配置Hadoop的HA功能,包括设置备用NameNode和使用ZooKeeper进行故障转移。
在配置过程中,可能会遇到各种问题,如网络不通、权限错误或Hadoop服务无法启动等。遇到这些问题时,要熟练使用Linux命令行和搜索引擎来寻找解决方案。
总结,配置Hadoop集群需要对Linux系统、网络配置、Java环境以及Hadoop的原理有一定理解。通过详细的步骤和适当的调试,你可以在VMware环境下成功搭建和运行Hadoop分布式系统。
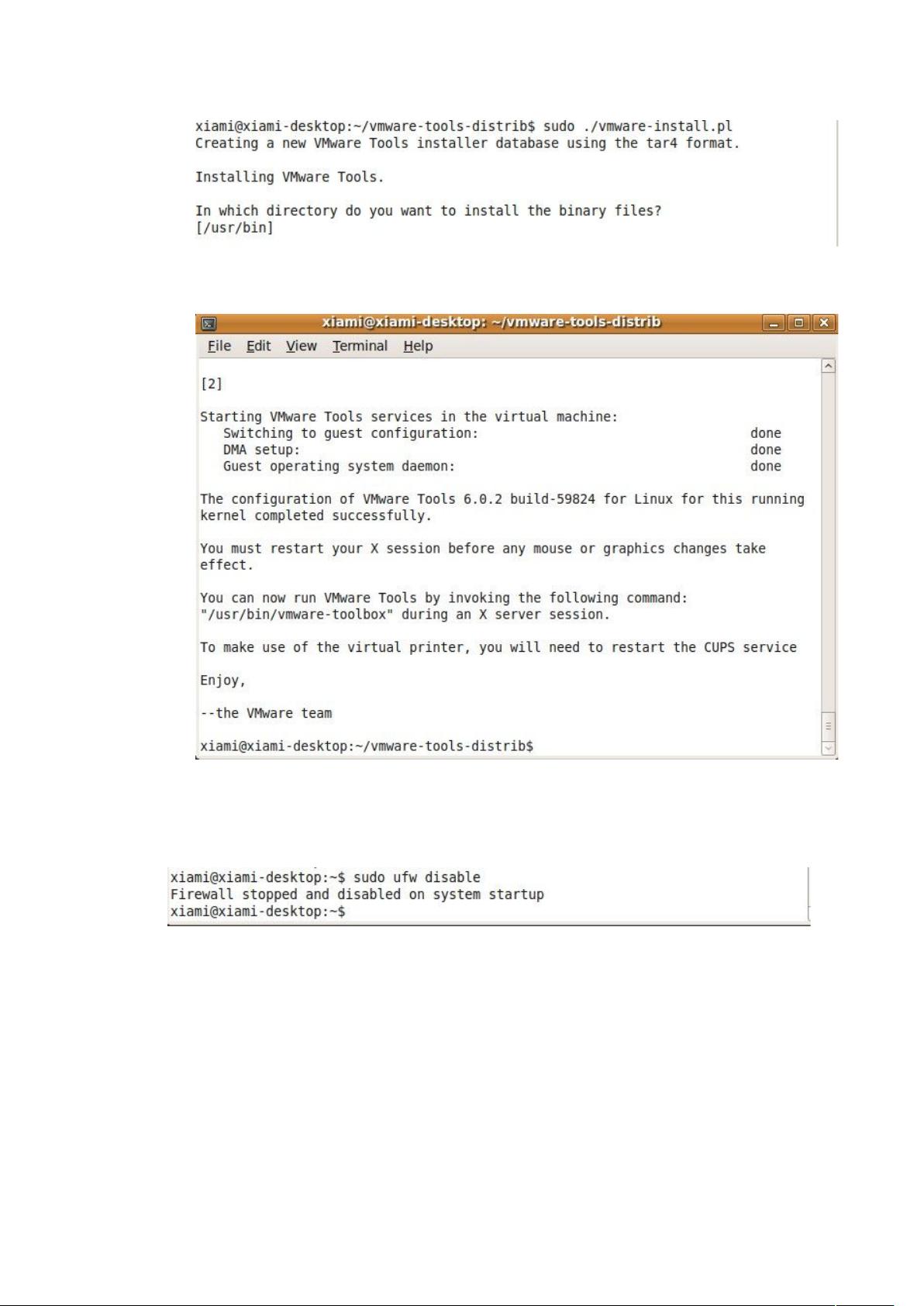
6. 直到出现“Enjoy——the VMware team”的字样后,VMwareTools 终于安装
完成:
四、关闭防火墙
用如下命令关闭虚拟机的防火墙:
PS:这步非常重要,如果不关闭的话,会出现找不到 datanode 节点的错误。而
且还要关闭宿主机的防火墙,方便下一步的网络配置。
五、网络配置
1. 设置你 window 下的网络共享:单击任务栏网络连接按钮,打开“网络和共
享中心”,选择“更改适配器设置”:
剩余18页未读,继续阅读
2021-10-05 上传
400 浏览量
2091 浏览量
2021-09-06 上传
407 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

智慧安全方案
- 粉丝: 3847
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Star UML指导手册
- FAT32文件系统白皮书(中文)
- 领域驱动模型详细介绍
- Asp.net开发必备51种代码(非常实用)
- 智能手机操作系统简介
- 当前,CORBA、DCOM、RMI等RPC中间件技术已广泛应用于各个领域。但是面对规模和复杂度都越来越高的分布式系统,这些技术也显示出其局限性:(1)同步通信:客户发出调用后,必须等待服务对象完成处理并返回结果后才能继续执行;(2)客户和服务对象的生命周期紧密耦合:客户进程和服务对象进程都必须正常运行;如果由于服务对象崩溃或者网络故障导致客户的请求不可达,客户会接收到异常;(3)点对点通信:客户的一次调用只发送给某个单独的目标对象。
- JSP 《标签啊,标签!》
- UDDI 注册中心介绍
- Thinking in C++, Volume 2, 2nd Edition 英文版 (pdf)
- 完全精通局域网.rar
- mtk的make命令分析
- Essential-MATLAB-for-Engineers-and-Scientists-Third-Edition
- Maven 权威指南 简体中文版
- 深入理解计算体系结构英文版
- AT&T汇编学习资料
- 计算机故障查询手册(非高手用)
