SPSS非线性回归实战:Logistics曲线拟合与分析
在SPSS中进行非线性回归是一种处理非线性关系的有效工具,特别适合于那些自变量与因变量之间的关系不能用简单的线性模型来描述的情况。本文以南美斑潜蝇幼虫在不同温度条件下的发育速率为例,具体介绍了如何在SPSS的Nonlinear过程下进行非线性回归分析。
首先,非线性回归分析是在线性回归的基础上扩展的一种统计方法,它能够捕捉到更复杂的数据模式,如曲线或指数关系。在SPSS中,"Nonlinear"过程允许用户选择不同的拟合函数,如本例中的逻辑斯蒂回归(Logistic Regression),这是一种广泛应用于二分类问题中的模型,可以用来预测概率而非连续的数值。
在实际操作中,用户需要设定一些关键参数。例如,“Levenberg-Marquardt”算法被选用,这是最常用的优化算法之一,采用麦夸尔迭代法,这种方法在求解非线性最小二乘问题时非常有效。用户需要设置“Maximumiterations”,即最大迭代步数,以便在达到预设精度前终止计算。此外,还有“Sum-of-squares convergence”和“Parameter convergence”两个指标,分别对应目标函数残差平方和的变化比例和参数变化的比例,这两个值的阈值越小,表明拟合精度越高。
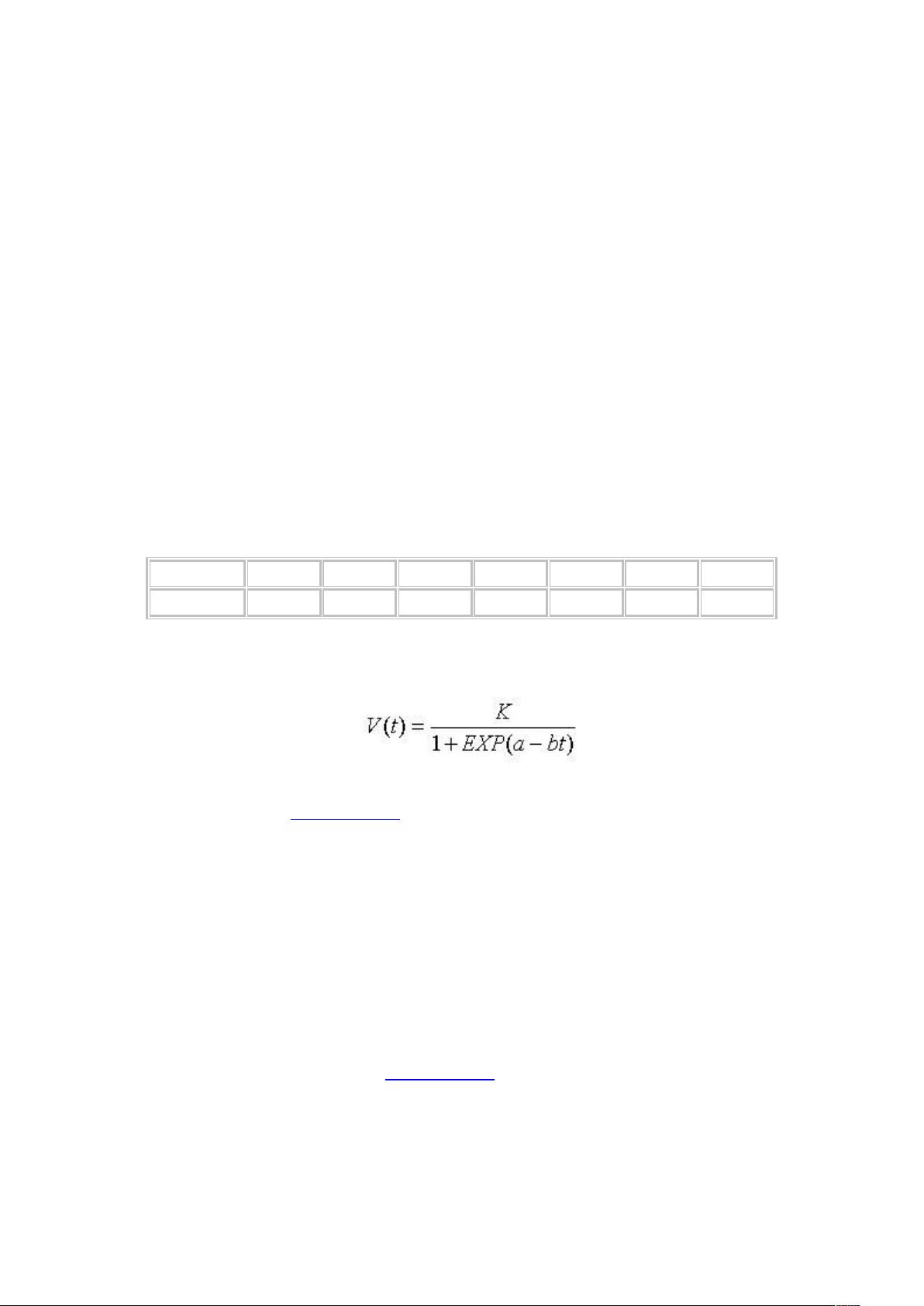
在本例中,用户设置了最大迭代步数为100次,残差平方和变化比例为1E-8,参数变化比例也为1E-8,这些都是为了确保拟合过程达到足够高的收敛性。执行这些设置后,用户点击“OK”启动非线性回归,SPSS会计算并输出结果,包括参数估计值(K、a和b)、拟合的逻辑斯蒂函数表达式以及评估指标,如残差平方和(Q)和拟合优度系数(R2)。
残差平方和衡量了实际观测值与模型预测值之间的差异,而拟合优度系数(R2)则表示模型解释了数据变异性的比例。在本例中,R2值为0.92370,说明模型对数据的拟合效果非常好,剩余的0.07630%变异未被模型完全解释。
通过这个实例,我们可以看到如何在SPSS中利用非线性回归进行数据分析,不仅限于逻辑斯蒂回归,还涵盖了选择合适算法、设置参数和解读结果的关键步骤。这是一项实用的技能,特别是在生物、社会科学等领域,非线性关系的模型可以帮助研究人员深入理解复杂现象背后的规律。
线性回归分析
在回归分析中,当自变量和因变量间的关系不能简单地表示为线性方程,或者不能表示
为可化为线性方程的时侯,可采用非线性估计来建立回归模型。
SPSS 提供了非线性回归“Nonlinear”过程,下面就以实例来介绍非线性拟合
“Nonlinear”过程的基本步骤和使用方法。
应用实例
研究了南美斑潜蝇幼虫在不同温度条件下的发育速率,得到试验数据如下:
表 5-1 南美斑潜蝇幼虫在不同温度条件下的发育速率
温度℃
17.5 20 22.5 25 27.5 30 35
发育速率
0.0638 0.0826 0.1100 0.1327 0.1667 0.1859 0.1572
根据以上数据拟合逻辑斯蒂模型:
本例子数据保存在 DATA6-4.SAV。
1)准备分析数据
在 SPSS 数据编辑窗口建立变量“t”和“v”两个变量,把表 6-14 中的数据分别输入“温度”
和“发育速率”对应的变量中。
或者打开已经存在的数据文件(DATA6-4.SAV)。
下载后可阅读完整内容,剩余9页未读,立即下载
2012-04-03 上传
2024-12-26 上传

happyeggplant
- 粉丝: 7
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- WeatherApp
- Marlin-Anet-A8:我的自定义设置的Marlin Anet A8配置
- Fit-Friends-API:这是使用Python和Django创建的Fit-Friends API的存储库。该API允许用户创建用户和CRUD锻炼资源。 Fit-Friends是一个简单但有趣的运动健身分享应用程序,通过对保持健康的共同热情将人们聚集在一起!
- CakePHP-Draft-Plugin:CakePHP插件可自动保存任何模型的草稿,从而允许对通过身份验证超时或断电而持久保存的进度进行数据恢复
- A星搜索算法:一种加权启发式的星搜索算法-matlab开发
- spmia2:Spring Cloud 2020的Spring Cloud实际应用示例代码
- LichVN-crx插件
- Mastering-Golang
- DhillonPhish:我的GitHub个人资料的配置文件
- 园林绿化景观施工组织设计-某道路绿化铺装工程施工组织设计方案
- 自相关:此代码给出离散序列的自相关-matlab开发
- Guia1_DSM05L:Desarrollo de la guia 1 DSM 05L
- FPS_教程
- Campanella-rapidfork:Campanella的话题后端
- os_rust:我自己的用Rust编写的操作系统
- Allociné Chrome Filter-crx插件
