VMware Serengeti:虚拟化大数据应用的解决方案与挑战
需积分: 10 30 浏览量
更新于2024-07-25
收藏 2.31MB PDF 举报
"Serengeti虚拟化大数据应用研讨会概述"
在当今的大数据时代,随着企业对数据处理能力的需求日益增长,Hadoop生态系统因其分布式计算和存储的优势被广泛应用。然而,传统的物理部署方式带来了诸多挑战,如部署复杂性、性能调优难题、资源利用率低下、安全共享困难以及单点故障风险等。这就是为什么越来越多的组织开始考虑将Hadoop进行虚拟化的原因。
VMware的Serengeti解决方案旨在解决这些问题,通过提供一个全面的虚拟化平台,帮助企业实现Hadoop环境的高效、安全和可扩展的管理。以下是会议大纲的主要内容:
1. **今天的大型数据系统**:这部分将介绍当前大数据处理系统的构成,包括ETL(提取、转换、加载)流程,实时流处理,非结构化数据(如Hadoop Distributed File System, HDFS),实时和结构化数据库,以及基于Spark(如S4或Apache Storm)的大规模并行处理和分析。
2. **为何选择虚拟化Hadoop**:这一环节深入剖析了物理Hadoop环境中的痛点,如部署时间长、资源优化难度大、硬件资源利用率低以及缺乏关键服务的高可用性(如NameNode和JobTracker的单点故障)。虚拟化提供了一个灵活且易于管理的环境,有助于降低这些困扰。
3. **Serengeti介绍**:Serengeti是VMware针对大数据虚拟化的创新解决方案,它旨在简化Hadoop集群的部署、管理和维护,同时提高资源利用效率和整体系统的稳定性。
4. **关于虚拟化常见的问题**:讨论可能遇到的技术疑问,如虚拟化是否会影响性能、如何确保数据一致性、以及虚拟化是否适用于所有Hadoop工作负载。
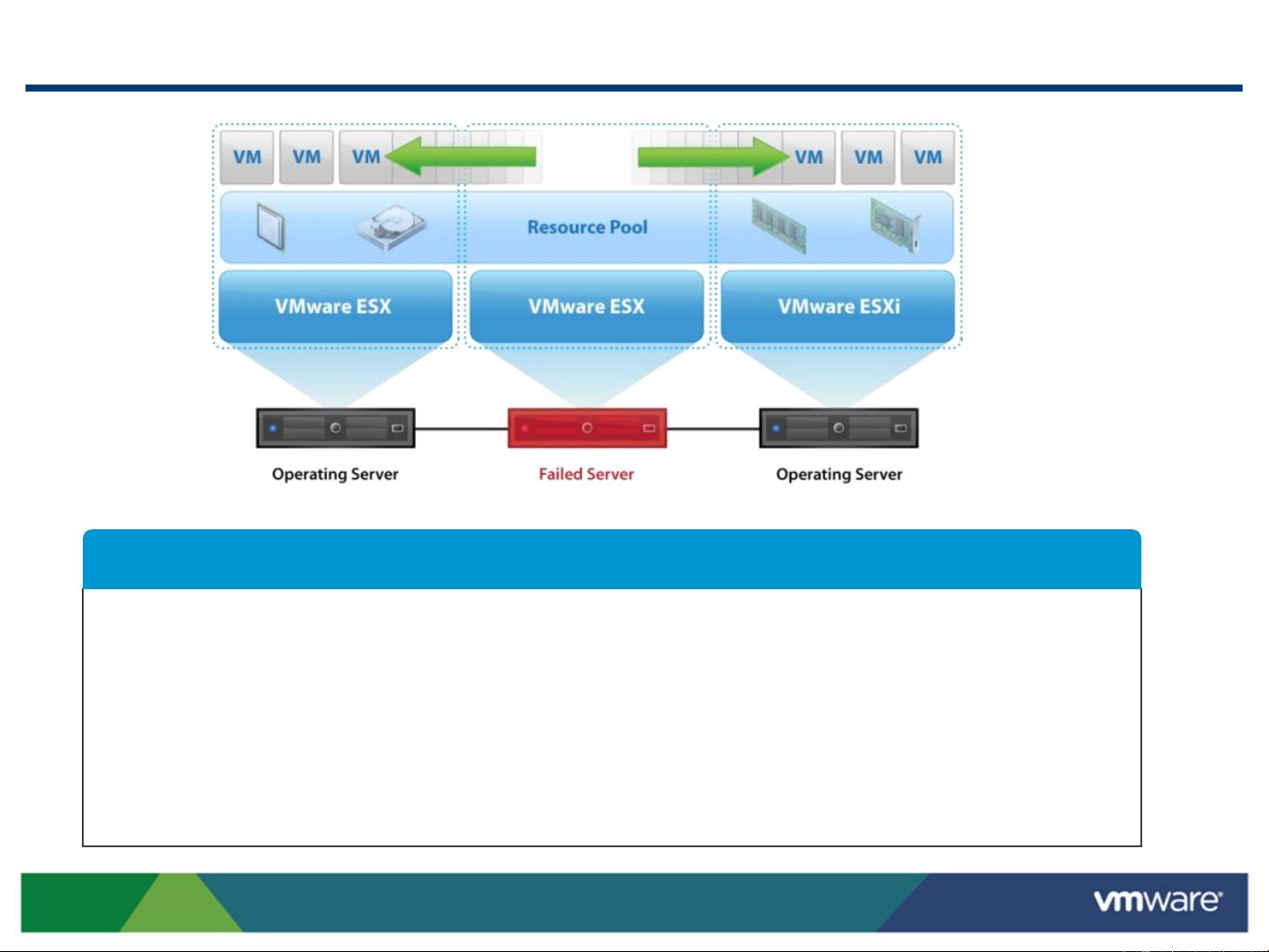
5. **Serengeti解决方案**:详细介绍Serengeti的功能特性,例如自动化部署、动态资源分配、跨工作负载的安全共享资源,以及增强的高可用性和容错机制。
6. **深入了解Serengeti**:深入讲解Serengeti的架构、技术优势和实际案例,展示其如何通过虚拟化提升Hadoop的灵活性、效率和可靠性。
7. **总结与问答**:会议以总结Serengeti的关键价值和应用前景结束,并开放提问环节,解答参会者关于Serengeti使用和实施的任何疑虑。
通过参加这样的研讨会,企业可以了解到如何通过Serengeti虚拟化策略优化其大数据处理基础设施,从而实现更高的运营效率,更低的成本,以及更强大的业务连续性。
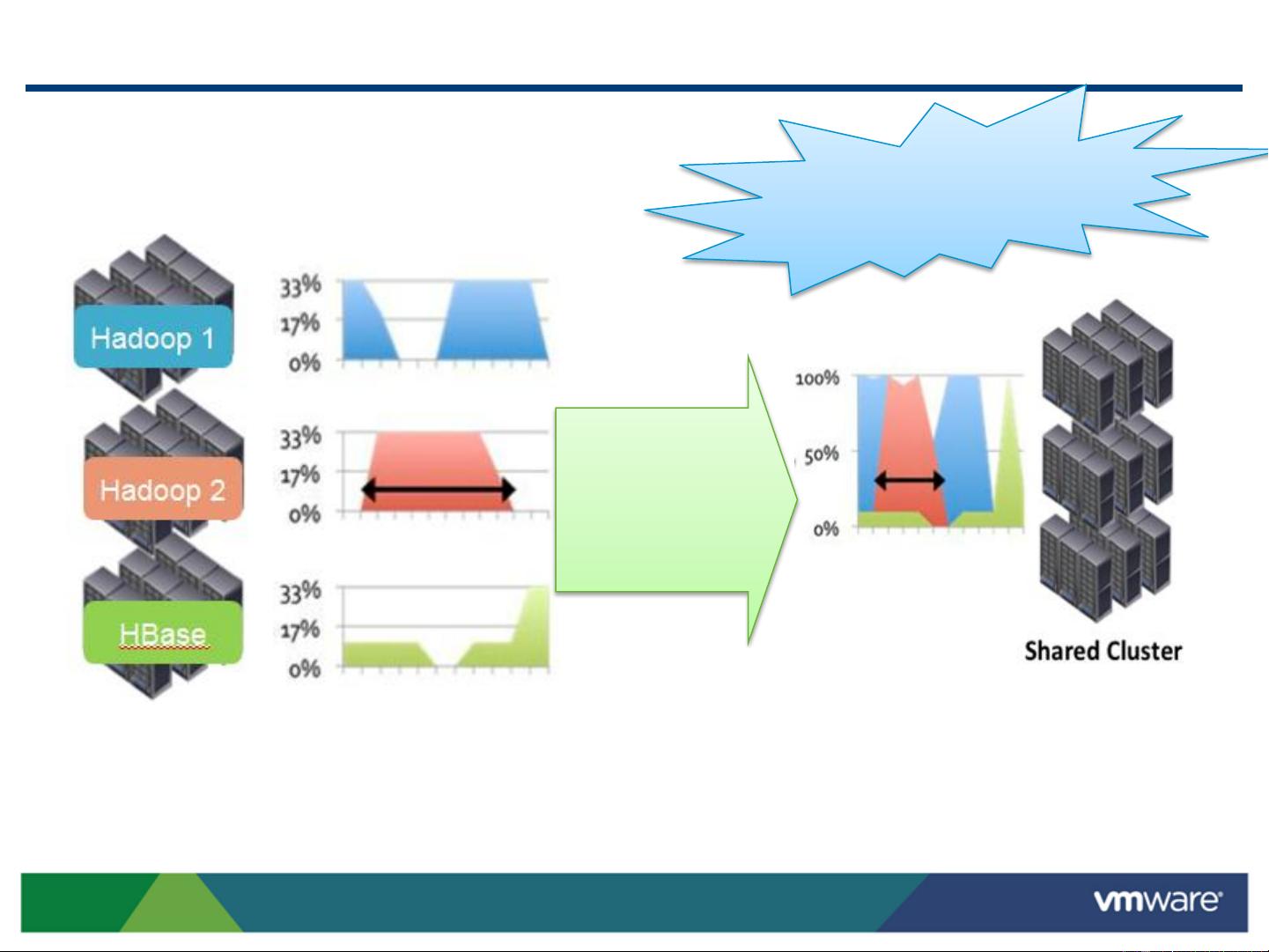
Why Virtualize Hadoop? –
Utilize all your resources to solve the priority problem
50%+ resources are sitting
idle while high priority job is
burning up its cluster.
Utilize all resources from
pool on demand.
Dynamic elastic
scaling on shared
resource pool
3X faster to get analytic results
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-10 上传
2023-03-23 上传
点击了解资源详情
2013-04-30 上传
点击了解资源详情

笃健者智
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实现类似百度的邮箱自动提示功能
- C++基础教程源码剖析与下载指南
- Matlab实现Franck-Condon因子振动重叠积分计算
- MapGIS操作手册:坐标系与地图制作指南
- SpringMVC+MyBatis实现bootstrap风格OA系统源码分享
- Web工程错误页面配置与404页面设计模板详解
- BPMN可视化示例库:展示多种功能使用方法
- 使用JXLS库轻松导出Java对象集合为Excel文件示例教程
- C8051F020单片机编程:全面控制与显示技术应用
- FSCapture 7.0:高效网页截图与编辑工具
- 获取SQL Server 2000 JDBC驱动免分数Jar包
- EZ-USB通用驱动程序源代码学习参考
- Xilinx FPGA与CPLD配置:Verilog源代码教程
- C#使用Spierxls.dll库打印Excel表格技巧
- HDDM:C++库构建与高效数据I/O解决方案
- Android Diary应用开发:使用共享首选项和ViewPager
