深度学习驱动的双路径注意力网络:遥感影像语义分割新方法
需积分: 10 201 浏览量
更新于2024-07-09
收藏 3.97MB PDF 举报
"这篇论文是' Dual Path Attention Net for Remote Sensing Semantic Image Segmentation',发表在《International Journal of Geo-Information》上,由Jinglun Li, Jiapeng Xiu, Zhengqiu Yang和Chen Liu等人撰写。文章讨论了深度学习技术在遥感影像语义分割中的应用,并提出了一种名为DPA-Net的新模型,该模型基于卷积神经网络,具有双路径注意力机制,旨在解决遥感图像语义分割的挑战。"
在遥感影像分析领域,语义分割是一项关键任务,它能帮助我们理解遥感图像中的各种地物和场景。近年来,随着深度学习的兴起,尤其是基于全卷积网络(Fully Convolutional Networks, FCNs)的方法,已经在遥感影像语义分割中取得了显著的成效。然而,遥感图像通常包含丰富的信息和复杂的场景,这使得网络训练变得极具挑战性,同时也对数据集的质量和规模提出了高要求。
论文提出的DPA-Net模型,是一种创新的卷积神经网络架构,它的核心在于双路径注意力机制。这种机制能够同时处理不同尺度的信息,增强模型对细节和全局结构的捕获能力。具体来说,"双路径"可能指的是两个并行的处理路径,分别关注图像的不同方面,如局部特征和全局上下文。而“注意力”则意味着模型可以自动分配权重,聚焦于对分割任务重要的区域或特征。
DPA-Net的模块化结构设计使得网络易于理解和优化。通过结合两种路径的输出,模型可以更准确地进行边界识别和复杂场景的分割。此外,由于其简洁的设计,DPA-Net可能在计算效率和泛化能力上有所提升,这在遥感影像处理这样的大数据量任务中尤其重要。
这篇论文对遥感影像语义分割领域的研究做出了贡献,DPA-Net模型提供了一个新的解决思路,以应对遥感图像的复杂性和多样性。它不仅有助于提高分割的准确性,还可能推动未来遥感影像分析技术的发展。该研究对于那些关注深度学习在遥感领域应用的研究人员和工程师来说,具有很高的参考价值。
ISPRS Int. J. Geo-Inf. 2020, 9, 571 4 of 20
problem can be considered as more than just a multi-scale and multi-angle problem. In a remote
sensing image, there will be many different types of land cover. In general, different types of land
cover have their own spectral and structural characteristics, which are visible in different brightness
values, pixel values, or spatial changes in remote sensing images. On account of the complexity of
the composition, nature, distribution, and imaging conditions of the surface features, remote sensing
images can be thought of in terms of “same object, different spectrum” and “same spectrum, different
object”. There are also two or more kinds of “mixed pixels” that can occur in a single pixel or the
instantaneous field of view, making the work of recognition in remote sensing images even more
complex. All of these factors can affect the accuracy of the result. To deal with this, our proposed
method seeks to enhance the aggregated channel and spatial features separately, thus improving the
feature representation for remote sensing segmentation.
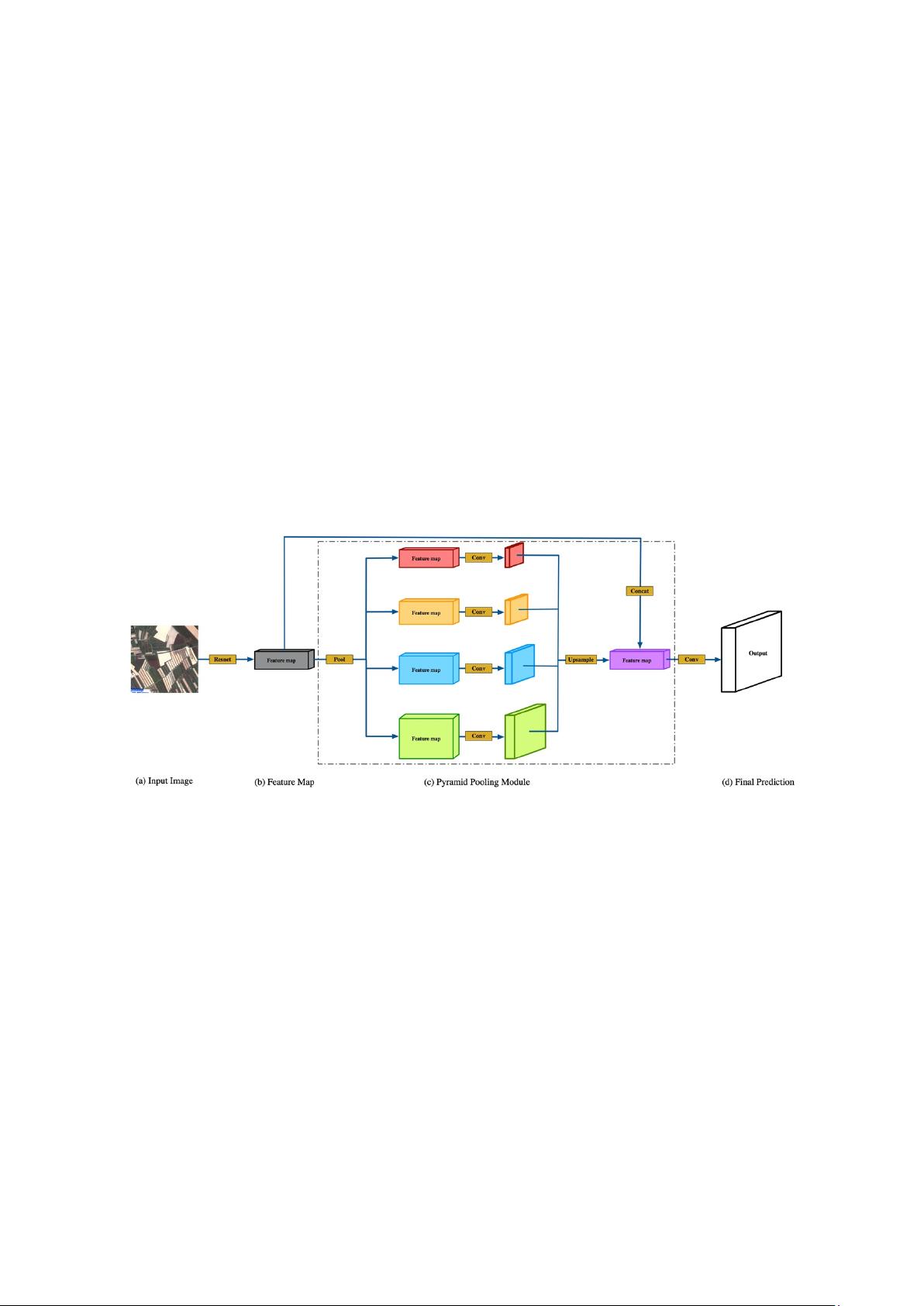
Our method can be used with any semantic segmentation model, such as U-Net, PSP-Net, etc.
Taking PSP-Net as an example, its basic structure is shown in Figure 1 [
22
]. The input image (a) is fed
into a Convolutional Neural Network (CNN) to obtain the feature map of the last convolutional layer
(b). Then, a pyramid parsing module (c) is used to get different sub-region representations, followed by
upsampling and concatenation layers to form the final feature representation. This contains both local
and global context information. Finally, a convolutional layer is used to get the per-pixel prediction (d)
according to the required representation.
ISPRS Int. J. Geo-Inf. 2020, 9, x FOR PEER REVIEW 4 of 20
3.1. Overview
For regular semantic segmentation, the scene for segmentation will include a variety of objects
of diverse scales with different lighting that are visible from different viewpoints. However, because
of the same shooting angle and distance of the samples in different remote sensing images, the
boundary problem can be considered as more than just a multi-scale and multi-angle problem. In a
remote sensing image, there will be many different types of land cover. In general, different types of
land cover have their own spectral and structural characteristics, which are visible in different
brightness values, pixel values, or spatial changes in remote sensing images. On account of the
complexity of the composition, nature, distribution, and imaging conditions of the surface features,
remote sensing images can be thought of in terms of “same object, different spectrum” and “same
spectrum, different object”. There are also two or more kinds of “mixed pixels” that can occur in a
single pixel or the instantaneous field of view, making the work of recognition in remote sensing
images even more complex. All of these factors can affect the accuracy of the result. To deal with
this, our proposed method seeks to enhance the aggregated channel and spatial features separately,
thus improving the feature representation for remote sensing segmentation.
Our method can be used with any semantic segmentation model, such as U-Net, PSP-Net, etc.
Taking PSP-Net as an example, its basic structure is shown in Figure 1 [22]. The input image (a) is
fed into a Convolutional Neural Network (CNN) to obtain the feature map of the last convolutional
layer (b). Then, a pyramid parsing module (c) is used to get different sub-region representations,
followed by upsampling and concatenation layers to form the final feature representation. This
contains both local and global context information. Finally, a convolutional layer is used to get the
per-pixel prediction (d) according to the required representation.
Figure 1. Overview of PSP-Net.
The general structure of DPA-PSP-Net is shown in Figure 2. We employed a pretrained
ResNet50 [48] and used a dilated strategy [38] for the backbone. Drawing upon the structure of
ResNet50, the proposed framework has four residual blocks, a Pyramid Pooling Module (PPM), a
channel attention module, and a spatial attention module. We removed the down-sampling
operation and employed dilated convolutions in the last two residual blocks instead, which is
identical to the process used in PSP-Net. Thus, the size of the final feature map was at 1/8 of the scale
of the input image. Given an input image with a size of 256 px × 256 px, we used ResNet50 to get the
feature map, F
1, while the weighting factor for the spatial attention, Ws, was obtained by the spatial
attention module. F
1 was fed into the PPM and the channel attention module, respectively, to obtain
the feature map, F
2, after up-sampling and applying the weighting factor for channel attention, Wc.
Finally, F
2 was multiplied by Wc and Ws to obtain the features to obtain the channel
attention-weighted feature map, F
C, and spatial attention-weighted feature map, FS. Then, FC and FS
were aggregated to get the final output.
Figure 1. Overview of PSP-Net.
The general structure of DPA-PSP-Net is shown in Figure 2. We employed a pretrained
ResNet50 [
48
] and used a dilated strategy [
38
] for the backbone. Drawing upon the structure
of ResNet50, the proposed framework has four residual blocks, a Pyramid Pooling Module (PPM),
a channel attention module, and a spatial attention module. We removed the down-sampling operation
and employed dilated convolutions in the last two residual blocks instead, which is identical to the
process used in PSP-Net. Thus, the size of the final feature map was at 1/8 of the scale of the input
image. Given an input image with a size of 256 px
×
256 px, we used ResNet50 to get the feature
map, F
1
, while the weighting factor for the spatial attention, Ws, was obtained by the spatial attention
module. F
1
was fed into the PPM and the channel attention module, respectively, to obtain the feature
map, F
2
, after up-sampling and applying the weighting factor for channel attention, W
c
. Finally, F
2
was
multiplied by W
c
and W
s
to obtain the features to obtain the channel attention-weighted feature
map, F
C
, and spatial attention-weighted feature map, F
S
. Then, F
C
and F
S
were aggregated to get the
final output.
剩余19页未读,继续阅读
2020-04-03 上传
2021-02-07 上传
2011-08-23 上传
2021-09-30 上传
点击了解资源详情
2023-06-09 上传
2018-10-18 上传
2010-08-18 上传

吾王saber_
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
