SparkSQL执行原理详解
需积分: 0 146 浏览量
更新于2024-08-03
收藏 796KB PDF 举报
"五分钟学大数据-SparkSQL底层执行原理"
SparkSQL是Apache Spark项目中的一个组件,专注于提供在大规模数据集上进行SQL查询的功能。SparkSQL的发展历程与Apache Spark的演进紧密相关,它旨在克服Hive等传统大数据处理工具的低效率问题。以下是SparkSQL的几个关键点和底层执行原理的详细解释:
一、ApacheSpark概述
Apache Spark是一个分布式计算框架,设计用于快速处理大数据。其核心特性是基于内存的计算,这显著提升了数据处理速度。Spark不仅支持批处理,还支持实时流处理和机器学习等任务。通过其弹性分布式数据集(Resilient Distributed Datasets, RDDs)概念,Spark能够高效地存储和操作数据,并且具有高容错性和可扩展性。
二、SparkSQL发展历程
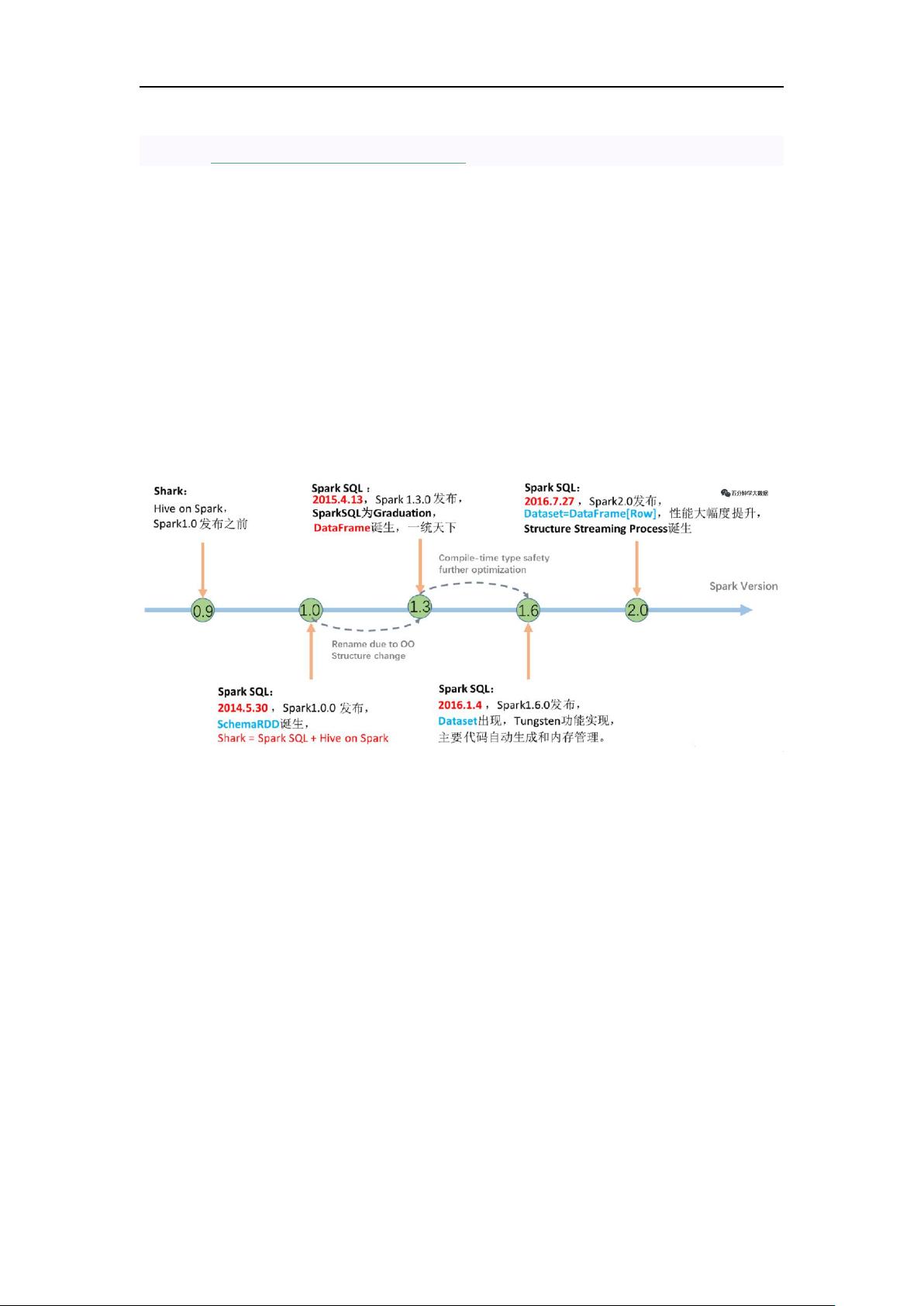
1. Shark的诞生
在Spark早期,为了提升Hive的性能,Shark应运而生。Shark利用Spark的内存计算能力改进了Hive的部分组件,如内存管理、物理计划和执行,但仍然依赖Hive的元数据和查询解析,导致扩展性和灵活性受限。
2. DataFrame的引入
随着Spark的发展,SparkSQL的DataFrame API出现,它提供了更高级别的抽象,允许用户以类似SQL的方式操作数据。DataFrame可以看作是一个分布式的、带列名的数据集合,它支持多种数据源,并提供了优化的执行计划。
3. Dataset的诞生
Dataset是DataFrame的进一步演化,它结合了RDD的强类型和DataFrame的SQL查询能力,提供了一种类型安全的方式来操作数据,同时也保留了Spark的高性能。
三、SparkSQL底层执行原理
1. Parser阶段:输入的SQL语句被解析成抽象语法树(Abstract Syntax Tree, AST),形成未解析的逻辑计划。
2. Analyzer阶段:对AST进行分析,生成解析后的逻辑计划,包括数据源、表和列的验证。
3. Optimizer模块:应用一系列基于规则的优化(RBO)和基于代价的优化(CBO),如Catalyst优化器,生成优化过的逻辑计划。
4. SparkPlanner模块:将优化后的逻辑计划转化为具体的物理执行计划,包括选择合适的执行算子和数据分区策略。
5. 执行物理计划:Spark的Executor节点按照执行计划执行任务,完成数据处理。
四、Catalyst优化器
Catalyst是SparkSQL的优化框架,包含两种主要优化策略:
1. RBO(基于规则的优化):通过一系列预定义的规则,如消除冗余操作、连接重排序等,优化逻辑计划。
2. CBO(基于代价的优化):根据数据大小、分区信息和硬件性能估计每个操作的成本,选择最优的操作路径。
总结,SparkSQL通过其高效的数据处理模型、灵活的API和强大的优化机制,为大数据分析提供了快速且易用的解决方案,克服了传统Hive在性能上的局限性。
本文档来自公众号:五分钟学大数据
3 / 11
传送门:Hive SQL 底层执行过程详细剖析
一、Apache Spark
Apache Spark 是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在
大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户
将 Spark 部署在大量硬件之上,形成集群。
Spark 源码从 1.x 的 40w 行发展到现在的超过 100w 行,有 1400 多位大牛贡献了
代码。整个 Spark 框架源码是一个巨大的工程。
二、Spark SQL 发展历程
我们知道 Hive 实现了 SQL on Hadoop,简化了 MapReduce 任务,只需写 SQL 就
能进行大规模数据处理,但是 Hive 也有致命缺点,因为底层使用 MapReduce 做
计算,查询延迟较高。
1. Shark 的诞生
所以 Spark 在早期版本(1.0 之前)推出了 Shark,这是什么东西呢,Shark 与
Hive 实际上还是紧密关联的,Shark 底层很多东西还是依赖于 Hive,但是修改
了内存管理、物理计划、执行三个模块,底层使用 Spark 的基于内存的计算模型,
从而让性能比 Hive 提升了数倍到上百倍。
产生了问题:
1. 因为 Shark 执行计划的生成严重依赖 Hive,想要增加新的优化非常困难;
剩余10页未读,继续阅读
318 浏览量
2023-08-29 上传
2022-08-03 上传
132 浏览量
123 浏览量
157 浏览量
111 浏览量
2023-05-10 上传
2023-06-09 上传

Libby博仙
- 粉丝: 733
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位instantclient_11_2使用指南及配置教程
- kWSL在WSL上轻松安装KDE Neon 5.20无需额外软件
- phpwebsite 1.6.2完整项目源码及使用教程下载
- 实现UITableViewController完整截图的Swift技术
- 兼容Android 6.0+手机敏感信息获取技术解析
- 掌握apk破解必备工具:dex2jar转换技术
- 十天掌握DIV+CSS:WEB标准实践教程
- Python编程基础视频教程及配套源码分享
- img-optimize脚本:一键压缩jpg与png图像
- 基于Android的WiFi局域网即时通讯技术实现
- Android实用工具库:RecyclerView分段适配器的使用
- ColorPrefUtil:Android主题与颜色自定义工具
- 实现软件自动更新的VC源码教程
- C#环境下CS与BS模式文件路径获取与上传教程
- 学习多种技术领域的二手电子产品交易平台源码
- 深入浅出Dubbo:JAVA分布式服务框架详解
