机器学习入门:线性回归详解与实践
需积分: 9 105 浏览量
更新于2024-07-15
收藏 359KB DOCX 举报
在"每天进步一点点《ML - 线性回归》"文档中,作者详细介绍了机器学习中的线性回归方法,这是监督学习的一个基础概念。作者强调,机器学习的目标是根据给定的输入实例(X)和期望输出(Y),通过训练一个模型(P),预测新的未知实例的输出。文档特别提到了监督学习与非监督学习的区别,前者如线性回归和分类,后者则是数据的自动聚类。
在文章的起始部分,作者提到他们的学习主要基于Andrew Ng的斯坦福大学录制的机器学习课程,并表示文章是个人学习的记录和分享,适合初学者阅读,同时也欢迎读者提出反馈以进行修正和更新。作者设定了一些约定,比如使用大写字母表示矩阵或向量,明确了实例矩阵X的维度和结构,以及参数向量θ的定义。
线性回归是文章的核心部分,其模式表示为H(θ)(X) = Xθ,这里的X是一个M*N的实例矩阵,θ是一个N*1的参数向量。每个实例的预测输出Y(i)可以通过将X(i)与θ相乘得到,形式上即Y(i) = (1, X(i)')(θ0, θ1, ..., θN)',其中X(i)'是第i个实例特征向量的转置。
线性回归被定义为对连续数值的预测,它假设输出与输入特征之间存在线性关系。作者会通过大量的计算过程和图示来解释如何估计参数θ,例如最小二乘法或梯度下降等优化算法,以及评估模型性能的方法,如均方误差(Mean Squared Error, MSE)。
文档后续可能会探讨线性回归的适用场景、模型训练步骤、特征选择、正则化等关键知识点,这些都是理解和应用线性回归不可或缺的部分。这篇文章为初学者提供了一个从理论到实践理解线性回归的全面指南,是机器学习入门者学习这一核心概念的重要参考资料。
clc;clear all;close all;
set(0,'defaultgurecolor','w');
x = [1, 2, 3, 4];
y = [1.1, 2.3, 3.2, 4.6];
theta = -2:0.1:4;
cost = zeros(size(theta));
for m=1:size(theta)(2)
cost(m) = sum((x .* theta(m) - y) .^ 2) / (2 * size(x)(2));
end;
gure();
subplot(1,1, 1)
scatter(theta, cost, 'r', 'linewidth', 3);
xlim([-2,7]);
ylim([-3,100]);
% axis equal;
grid on;
xlabel('theta');
ylabel('cost value');
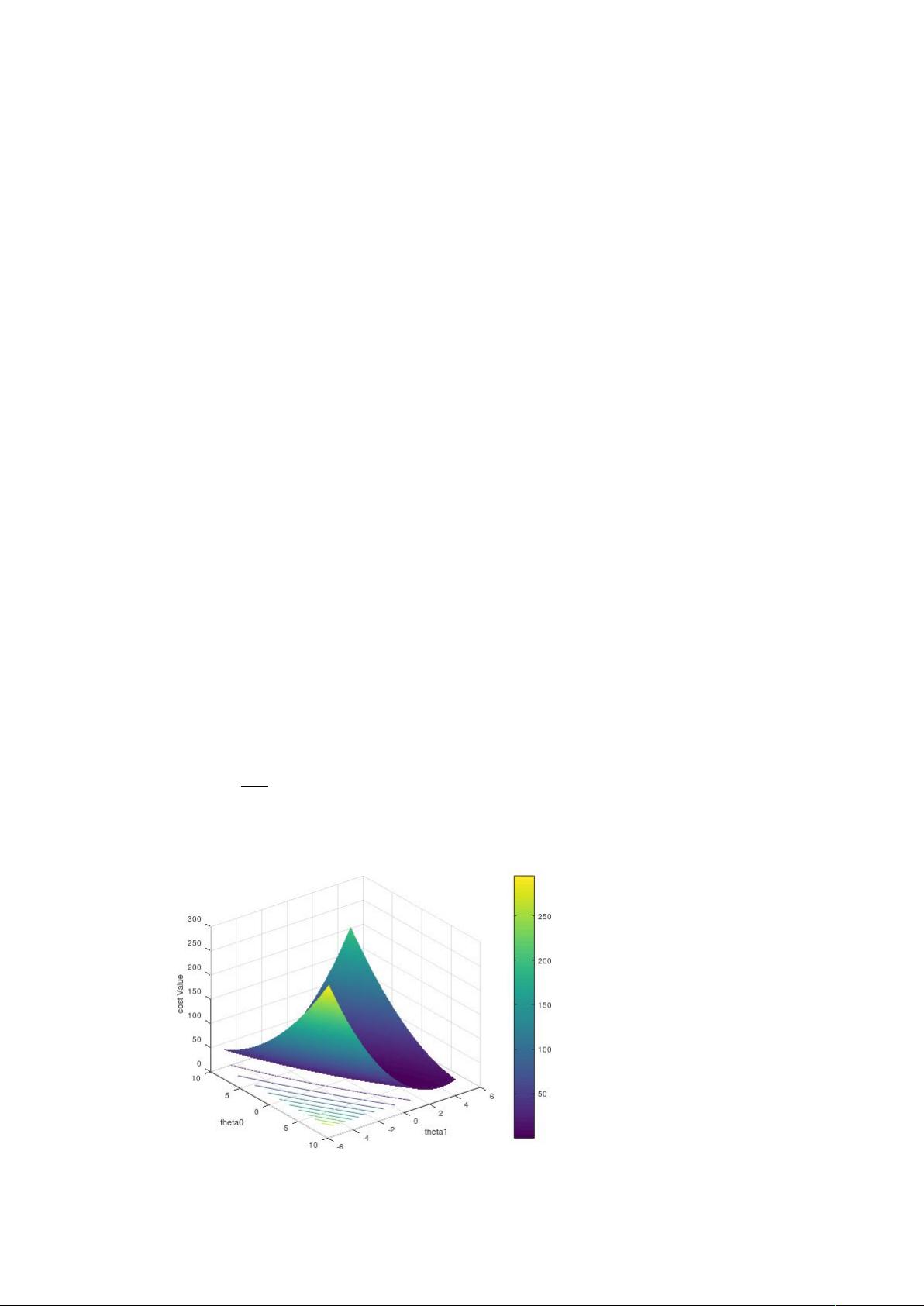
直观的印象二(含有两个参数):
假设函数模型:Y = H
(θ)
(X) = θ
1
x +θ
0
则
J (θ)=
1
2 m
∑
i=1
m
[θ
1
x+θ
0
− y
(
i
)
]
2
给出四个点(1,1.1),(2,2.3),(3,3.2),(4,4.6),画出 J(θ)随着 θ 的函数图像
随着 θ
1
和 θ
0
的变化,cost function value 也随着变化,终有取最小值的一系列点。
剩余15页未读,继续阅读
103 浏览量
1123 浏览量
2024-08-31 上传
2023-03-22 上传

星海千寻
- 粉丝: 305
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
