图像描述生成任务详解:CNN与RNN的结合与注意力机制
需积分: 48 47 浏览量
更新于2024-07-17
收藏 7MB DOCX 举报
"image caption任务是人工智能领域中图像理解和自然语言处理(NLP)相结合的一个重要研究方向,旨在从图像中自动生成能够准确描述其内容的文本描述,捕捉图像的高层语义信息,如物体识别、关系理解及物体属性描述。"
在image caption任务中,主要涉及两种核心技术:卷积神经网络(CNN)和循环神经网络(RNN),特别是长短时记忆网络(LSTM)。CNN用于图像特征提取,它可以从图像中捕获丰富的空间信息,形成特征映射。通常,会取特征映射的平均值或池化值作为图像的全局表示。这一过程被称为编码(Encode)。
接着,RNN,尤其是LSTM,用于生成描述性文本,这被称为解码(Decode)。在基本的Encoder-Decoder架构中,CNN的输出特征作为LSTM的第一步隐藏状态,然后LSTM逐词生成句子。然而,这种方法存在局限,当生成较长的描述时,LSTM在后期可能无法有效利用图像信息。
为了解决这个问题,研究人员引入了注意力机制(Attention Mechanism)。在《Show and Tell: A Neural Image Caption Generator》这篇论文中,Google提出了将CNN用于提取图像的“视觉特征”,形成一个特征向量c,这个c作为Decoder的初始状态。在Decoder的每个时间步,不仅当前的词向量会作为输入,还会根据注意力机制计算出一个上下文向量,该向量反映了Decoder在不同时间步关注图像的不同部分,从而增强了模型对图像细节的捕获能力,提高了caption的准确性。
具体来说,注意力机制允许Decoder在解码过程中动态地聚焦于图像的不同区域,而不是仅仅依赖一个固定不变的图像特征向量。这样,Decoder可以根据生成的文本动态地选择关注图像的哪些部分,从而生成更精确、更具细节的描述。例如,如果图像包含多个对象,注意力机制可以帮助模型在描述每个对象时集中注意力,从而生成更加连贯和详细的caption。
image caption任务结合了计算机视觉和自然语言处理的精华,通过深度学习技术,实现了从视觉信息到语言描述的转化,为机器理解和生成自然语言提供了一种强大的工具。随着技术的进步,这一领域的研究将继续推动人工智能向着更智能、更人性化的方向发展。
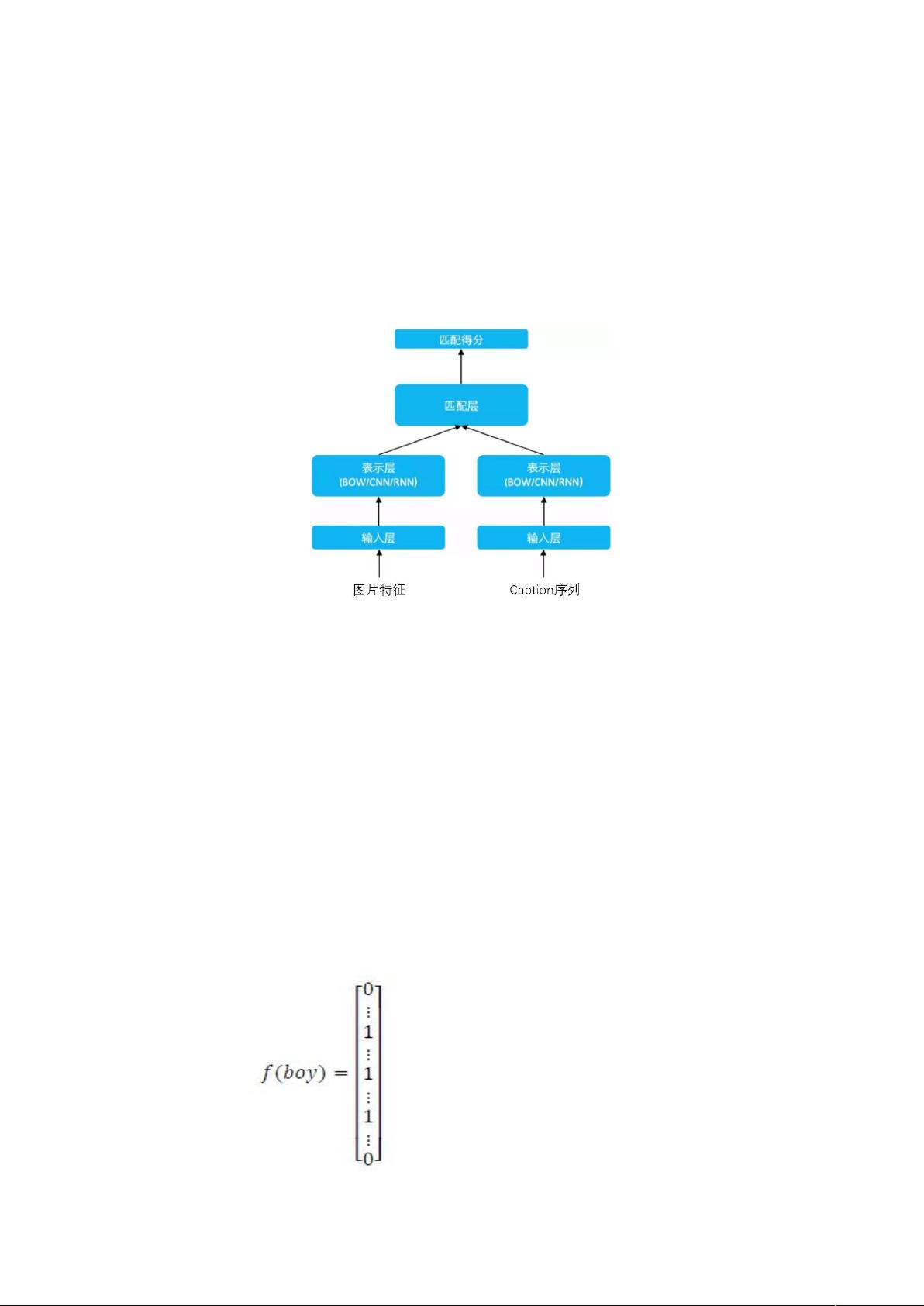
$# 求得多个 0 作为原始图片的候选匹配,针对这些 0
选择与图片最佳的匹配形式。
/ 深度相关性模型 770::7:57"#
在 提 取 了 多 个 候 选 0 之 后 , 为 图 片 选 择 最 佳 的
,基于深度语义匹配模型"#生成 模型对候选
与图片进行相似度匹配。
的原理:用 @把图片和语句分别表达为低维语义向量,
并通过 0:距离来计算两个语义向量的距离,最终训练出语义相
似度模型。
# 输入层
对于 语句,输入层将句子映射到一个向量空间里并输入到
中,输入层处理方式是通过 6*0*::假设用 7.!:0
来切分单词(/个字母为一组,A表示开始和结束符),?5这个单
词会被切为 A!?!'?!!5'!5!A,即三个字母组成一个单元,一共三个
单元的组合集。建立一个 *0*: 表,表中每个位置为一种单元形式
(由于一共只有 & 个字母,因此三个字母组成不同单元的枚举情况
很有限),把对应的单词转化成一个向量替代原本的 !* 向量。
一 个 “ ?5B 单 词 转 化 成 的
*0*: 向量,其中有三个位
置置 ,分别代表“A!?!B单元
“?!!5B单元以及“!5!AB单元

剩余44页未读,继续阅读
2021-03-07 上传
2023-02-06 上传
2023-01-11 上传
2023-05-29 上传
2023-01-11 上传
2023-06-09 上传
2023-05-05 上传

Josephq_ssp
- 粉丝: 3
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
