Kafka分布式消息系统配置详解
需积分: 5 19 浏览量
更新于2024-09-11
收藏 261KB PPTX 举报
"kafka配置.pptx - 介绍Kafka的定义、应用领域、消息队列比较、架构、Zookeeper集群搭建以及Kafka集群配置步骤"
Kafka是一种分布式消息系统,由LinkedIn开发并用Scala编程语言实现。它最初设计用于处理LinkedIn的活动流和运营数据,具备高度可扩展性和高吞吐量的特性。Kafka被广泛应用于数据管道和消息传递,例如在淘宝、支付宝、百度、Twitter等大型互联网公司中都有应用。
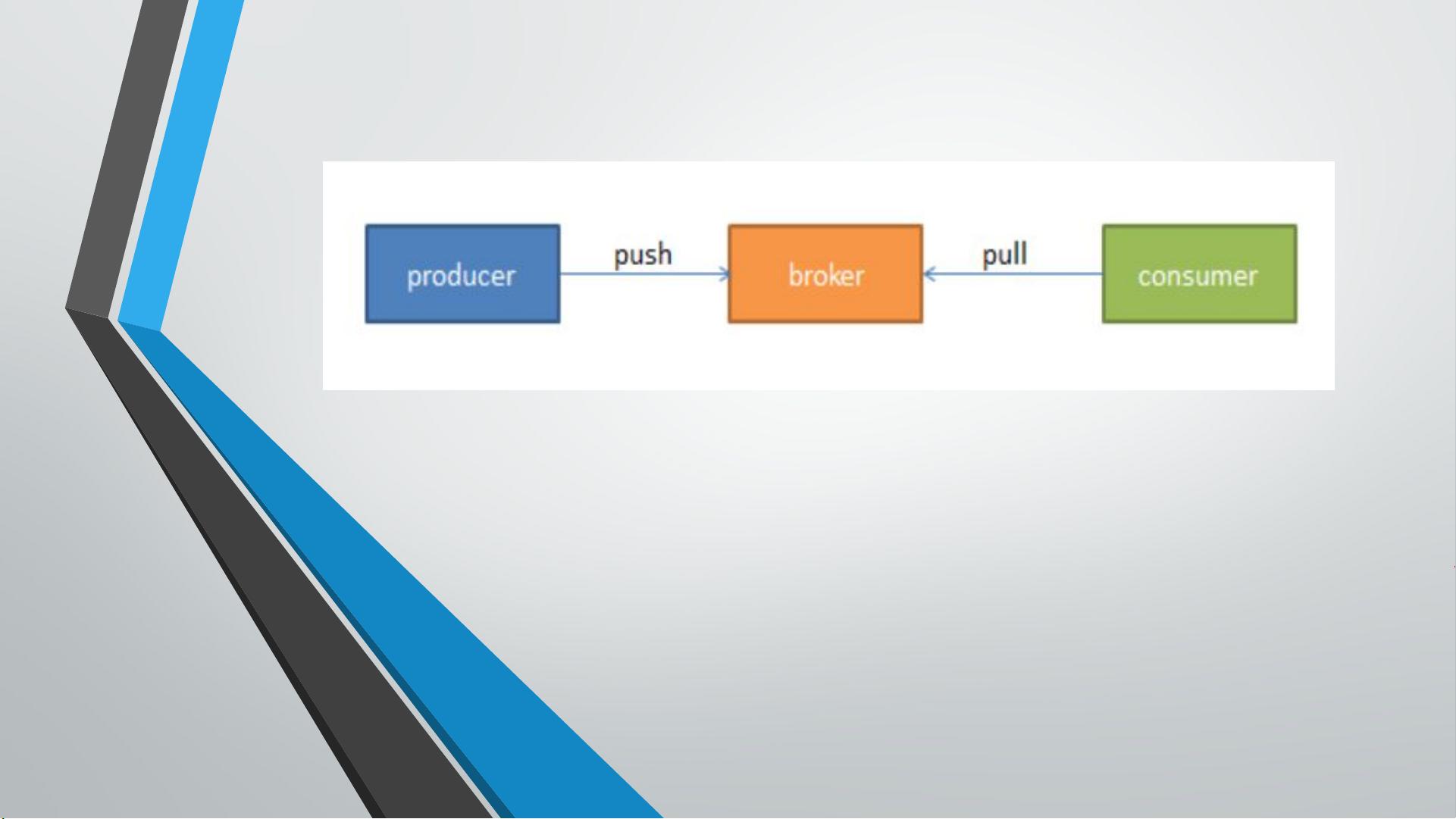
在消息队列领域,Kafka与AMQP协议有所不同。在AMQP中,有消费者(Consumer)、生产者(Producer)和服务器端(Broker)的角色,而Kafka的核心概念包括主题(Topic)和分区(Partition)。一个主题通常对应于一个业务场景,而分区则是构成Kafka消息队列的基本单元。这种设计允许数据分散存储,提高读写性能,并支持并行处理。
Kafka的架构通常包含Zookeeper集群和Kafka集群。Zookeeper是一个分布式协调服务,用于管理Kafka的元数据和选举领导节点。在搭建Kafka集群时,首先需要准备Zookeeper集群,然后是Kafka节点的配置。例如,在搭建过程中,需要上传Kafka软件包,解压到指定目录,并进行配置。配置文件`server.properties`中,需要设置如主机名、消息大小限制、副本因子、取信息的最大值以及Zookeeper连接地址等参数。完成单个节点的配置后,需要将配置复制到其他所有节点,确保集群的一致性。
在Kafka集群中,每个节点都可以作为生产者或消费者,同时处理消息的发布和订阅。通过分区策略,Kafka能够保证消息的顺序,并在多台机器间均衡负载,提供高可用性和容错性。此外,Kafka还支持数据的持久化,即使在节点故障时,也能通过副本恢复数据,确保数据不丢失。
总结来说,Kafka是一个高效、可扩展的分布式消息中间件,适用于大数据实时处理、流计算等多种场景。其核心特性包括分布式架构、主题与分区的设计、高吞吐量以及与Zookeeper的集成,使得Kafka成为现代云环境中的重要组件。理解并掌握Kafka的配置和运行原理对于构建大规模分布式系统至关重要。
AMQP 协议
基本的概念 :
•
消费者( Consumer ):从消息队列中请求消息的客户端应用程序;
•
生产者( Producer ):向 broker 发布消息的客户端应用程序;
•
AMQP 服务器端( broker ) : 用来接收生产者发送的消息并将这些消息路由给服务
器中的队列;
剩余10页未读,继续阅读
2022-12-23 上传
2021-03-06 上传
2022-11-30 上传
2022-12-23 上传
2021-11-28 上传
2021-11-28 上传
2022-12-23 上传
2021-03-05 上传
2021-04-28 上传

jtyoui
- 粉丝: 39
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
